







数据集
直接使用微软的猫狗分类数据集合:微软猫狗数据集
应为数据集合有几万张,模型跑起来实在太慢了,所以结果一些处理后在使用。
数据预处理:
import os
from PIL import Image
cat_name = os.listdir('PetImages/Cat/')
dog_name = os.listdir('PetImages/Dog/')
os.mkdir('data/train')
os.mkdir('data/train/Cat')
os.mkdir('data/train/Dog')
train_cnt = 2000
for i in range(train_cnt):
path = os.path.join('PetImages/Cat/', cat_name[i])
try:
img = Image.open(path)
# print(path)
new_path = os.path.join('data/train/Cat/', cat_name[i])
img.save(new_path)
except:
print('读取错误')
for i in range(train_cnt):
path = os.path.join('PetImages/Dog/', dog_name[i])
try:
img = Image.open(path)
# print(path)
new_path = os.path.join('data/train/Dog/', dog_name[i])
img.save(new_path)
except:
print('读取错误')
os.mkdir('data/val')
os.mkdir('data/val/Cat')
os.mkdir('data/val/Dog')
for i in range(train_cnt, 2500):
path = os.path.join('PetImages/Cat/', cat_name[i])
try:
img = Image.open(path)
# print(path)
new_path = os.path.join('data/val/Cat/', cat_name[i])
img.save(new_path)
except:
print('读取错误')
for i in range(train_cnt,2500):
path = os.path.join('PetImages/Dog/', dog_name[i])
try:
img = Image.open(path)
# print(path)
new_path = os.path.join('data/val/Dog/', dog_name[i])
img.save(new_path)
except:
print('读取错误')
处理之后目录结果:

模型训练
导包
from torch.utils.data import DataLoader
import numpy as np
import pandas as pd
from torchvision import datasets
import matplotlib.pyplot as plt
import warnings
# 忽略烦人的红色提示
warnings.filterwarnings("ignore")
数据加载
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [
0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
trian_datasets = datasets.ImageFolder('data/train/',train_transform)
val_datasets = datasets.ImageFolder('data/val/', test_transform)
val_datasets.classes
print('训练集个数', len(trian_datasets))
print('测试几个数', len(val_datasets))
BATCH_SIZE = 16 # 每次取用16个然后去喂模型
train_loader = DataLoader(trian_datasets,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2)
# shuffle 是不是随机
test_loader = DataLoader(val_datasets,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=2)
模型部分
import torch
import torch.nn as nn
from torch.hub import load_state_dict_from_url
model_urls = {
"vgg16": "https://download.pytorch.org/models/vgg16-397923af.pth",
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True, dropout=0.5):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=dropout),
nn.Linear(4096, num_classes),
)
if init_weights:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(
m.weight, mode="fan_out", nonlinearity="relu")
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
"D": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512, "M", 512, 512, 512, "M"],
}
def vgg16(pretrained=True, progress=True, num_classes=2):
model = VGG(make_layers(cfgs['D']))
if pretrained:
state_dict = load_state_dict_from_url(
model_urls['vgg16'], model_dir='./model', progress=progress)
model.load_state_dict(state_dict)
if num_classes != 1000:
model.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
return model
创建GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device配置模型参数
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
model = vgg16(pretrained=True, progress=True, num_classes=2)
model.to(device)
criterion = nn.CrossEntropyLoss()
EPOCHS = 20
# 学习率降低策略
optimizer = optim.Adam(model.parameters(), lr=0.001)
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)
训练
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
epoch = 0
batch_idx = 0
best_test_accuracy = 0
def train_one_batch(images, labels):
'''
运行一个 batch 的训练,返回当前 batch 的训练日志
'''
# 获得一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
loss = criterion(outputs, labels) # 计算当前 batch 中,每个样本的平均交叉熵损失函数值
# 优化更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 获取当前 batch 的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
log_train = {}
log_train['epoch'] = epoch
log_train['batch'] = batch_idx
# 计算分类评估指标
log_train['train_loss'] = loss
log_train['train_accuracy'] = accuracy_score(labels, preds)
# log_train['train_precision'] = precision_score(labels, preds, average='macro')
# log_train['train_recall'] = recall_score(labels, preds, average='macro')
# log_train['train_f1-score'] = f1_score(labels, preds, average='macro')
return log_train
def evaluate_testset():
'''
在整个测试集上评估,返回分类评估指标日志
'''
loss_list = []
labels_list = []
preds_list = []
with torch.no_grad():
for images, labels in test_loader: # 生成一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
# 获取整个测试集的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
# 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值
loss = criterion(outputs, labels)
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
loss_list.append(loss)
labels_list.extend(labels)
preds_list.extend(preds)
log_test = {}
log_test['epoch'] = epoch
# 计算分类评估指标
log_test['test_loss'] = np.mean(loss)
log_test['test_accuracy'] = accuracy_score(labels_list, preds_list)
log_test['test_precision'] = precision_score(
labels_list, preds_list, average='macro')
log_test['test_recall'] = recall_score(
labels_list, preds_list, average='macro')
log_test['test_f1-score'] = f1_score(labels_list,
preds_list, average='macro')
return log_test
# 训练日志-训练集
df_train_log = pd.DataFrame()
log_train = {}
log_train['epoch'] = 0
log_train['batch'] = 0
images, labels = next(iter(train_loader))
log_train.update(train_one_batch(images, labels))
df_train_log = df_train_log.append(log_train, ignore_index=True)
# 训练日志-测试集
df_test_log = pd.DataFrame()
log_test = {}
log_test['epoch'] = 0
log_test.update(evaluate_testset())
df_test_log = df_test_log.append(log_test, ignore_index=True)
import wandb
import time
wandb.init(project='CatAndDog', name=time.strftime('%m%d%H%M%S'))
import os
from tqdm import tqdm
for epoch in range(1, EPOCHS+1):
print(f'EPOCH: {epoch}/{EPOCHS}')
model.train()
for images, labels in tqdm(train_loader):
batch_idx += 1
log_train = train_one_batch(images, labels)
df_train_log = df_train_log.append(log_train, ignore_index=True)
wandb.log(log_train)
lr_scheduler.step()
model.eval()
log_test = evaluate_testset()
df_test_log = df_test_log.append(log_test, ignore_index=True)
wandb.log(log_test)
if log_test['test_accuracy'] > best_test_accuracy:
old_best_path = 'best-{:.3f}.pth'.format(best_test_accuracy)
if os.path.exists(old_best_path):
os.remove(old_best_path)
new_best_path = 'best-{:.3f}.pth'.format(log_test['test_accuracy'])
torch.save(model, new_best_path)
print('保存新的最佳模型', 'best-{:.3f}.pth'.format(best_test_accuracy))
best_test_accuracy = log_test['test_accuracy']x
df_train_log.to_csv('训练日志-训练集.csv', index=False)
df_test_log.to_csv('训练日志-测试集.csv', index=False)
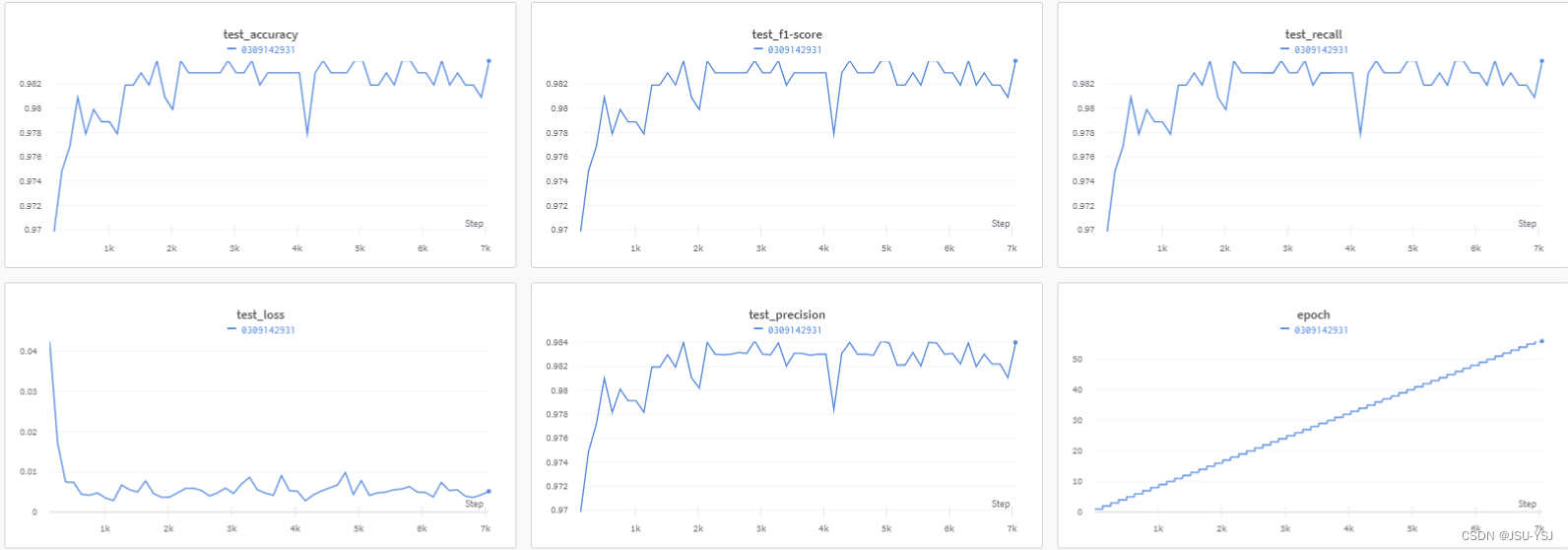
训练结果















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









