







1. 数据库和实例
数据库:物理操作系统文件或其他形式文件类型的集合。
数据库以 frm MYD MYI 结尾的文件
.frm :表定义,描述表结构文件
.MYD: "D"数据信息文件,是表的数据文件
.MYI: "I"索引信息文件,是表数据文件中任何索引的数据树
实例:MySQL数据库由后台线程以及一个共享内存区组成。
实例的启动会在哪些地方找配置文件:
$ mysql --help |grep my.cnf
order of preference, my.cnf, $MYSQL_TCP_PORT,
/etc/my.cnf /etc/mysql/my.cnf ~/.my.cnf按照上面的顺序进行寻找,相同的配置以最后一个配置文件为准
注意点:
1)数据库实例才是真正操作数据库文件的。即一个数据库实例对应一个数据库,一个数据库对应一个数据库实例,但是在集群情况下,可能存在一个数据库对应多个数据库实例。
2)数据库实例在系统上的表现就是一个进程。MySQL是一个单进程多线程的应用。
2.MySQL体系结构
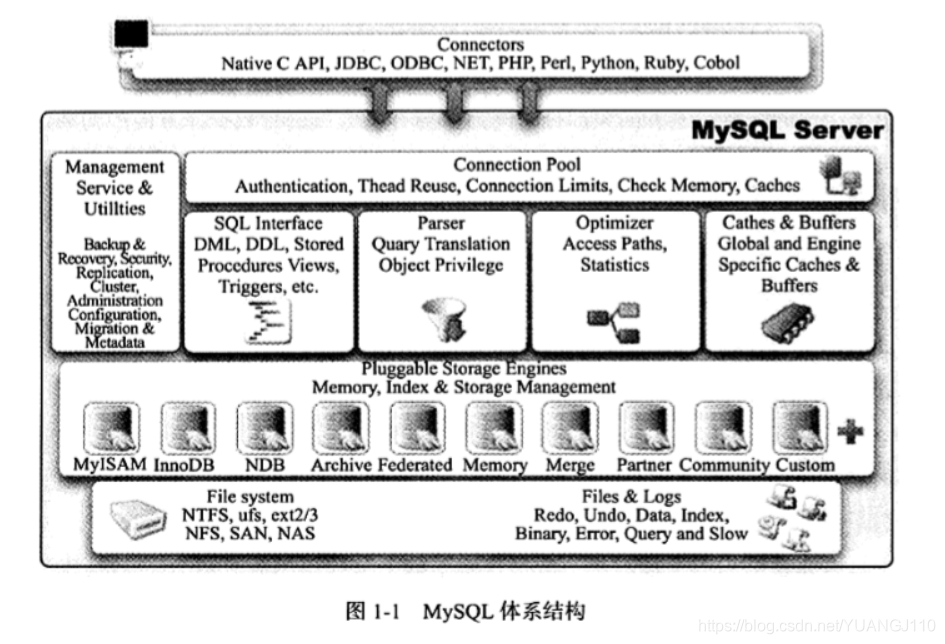
自上而下分别是:
-
数据库驱动(JDBC)
-
连接池组件
-
管理服务和工具组件
-
SQL接口组件
-
查询分析器组件
-
优化器组件
-
缓冲组件
-
插件式存储引擎
-
物理文件
3.MySQL存储引擎
3.1 InnoDB 存储引擎
-
MySQL5.6之后,成为默认存储引擎
-
支持事务,设计目标是面向在线事务处理(OLTP)的应用。
-
支持行锁,外键
-
使用多版本并发控制(MVCC)来实现高并发性以及事物的隔离级别
-
聚集(簇)索引:每张表的数据存储都是按照主键的顺序进行存放的,如果表创建时候没有指定主键,InnoDB会为每一行生成6字节的ROWID,作为主键.
-
聚集索引:比较好的总结
聚簇索引和非聚簇索引:
https://blog.csdn.net/jiadajing267/article/details/54581262
简单来说,聚簇索引就是表记录的排列顺序和索引的排列顺序一致.
不是聚簇索引的就是非聚簇索引.
详细的之后再看.
叶子节点存储的数据:聚簇索引vs非聚簇索引
3.2 MyISAM 存储引擎
- 不支持事务
- 表锁设计
- 支持全文索引
- 主要面向OLAP数据库应用
- 缓存池只缓存索引文件,而不缓存数据文件,数据文件的缓存交由操作系统完成
3.3 NDB引擎
- 集群存储引擎
- 数据全部放在内存中(从MySQL5.1开始,将非索引数据放在磁盘上)
- 问题:存储引擎的连接操作(JOIN)是在MySQL数据库层完成的,而不是在存储引擎层完成的.这意味着复杂的连接操作需要巨大的网络开销.
3.4 MyISAM 和 InnoDB 比较
| MyISAM | InnoDB |
|---|---|
| 不支持事务 | 支持事务 |
| 表锁 | 行锁 |
| 不支持外键 | 支持外键 |
| 类似堆表? | 索引组织表 |
| .frm存储表结构,.MYD存放数据,.MYI存放索引 | .frm存储表结构,ibdata1共享表空间,.ibd多表存储 |
| 索引存放位置:.MYI | 索引和数据一起存放在表空间中 |
| 只缓存索引文件,数据文件的缓存由操作系统本身完成 | 索引和数据一起保存在表空间里 |
堆表:
- 没有聚集索引的表
- 数据存储没有任何的顺序(导致查询慢?),插入数据也没顺序
- 数据页之间没有衔接
3.5 小结
MySQL的存储引擎很多,不存在优劣性的差异,要在合适的场景下使用合适的引擎.
4. 连接MySQL
连接MySQL的操作是一个进程和数据库实例之间的通信,本质上是进程之间的通信.
连接数据库的方式:
- TCP/IP
- 命名管道和共享内存
- UNIX域套接字
4.1 TCP/IP
远程访问首先要将远程的数据库权限打开:
use mysql;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
#最后刷新一个缓存
flush privileges;
#使用下面的命令可以连接远程服务器
#注:ubuntu->win(success),win->ubuntu(fail)
$ mysql -h192.168.137.1 -uroot -p****

win10连接阿里云服务器(ubuntu16.04)的MySQL
MySQL版本:(mysql --version)
mysql Ver 14.14 Distrib 5.7.30, for Linux (x86_64) using EditLine wrapper
参考链接:
https://www.cnblogs.com/xujishou/p/6306765.html
http://www.mamicode.com/info-detail-2213421.html
我遇到的坑:(只找到了替代方案,有大佬指导一下,具体问题在哪)
1)ubuntu 16.04 mysql的配置文件位置: /etc/mysql/mysql.conf.d/mysqld.cnf
2)上面设置完毕后,通过cmd窗口连接:
mysql -hIP地址 -u用户名 -p密码
然后报错:ERROR 1045 (28000): Access denied for user ‘root’@‘1*’ (using password: YES)
问题可能原因 :mysql.user表中有两个root用户,密码不一致?,暂时还不知道为什么
然后我新建一个用户:
CREATE USER ‘yuan’@’%’ IDENTIFIED BY ‘123’;
grant all on * . * to ‘yuan’@’%’;
成功连接,使用Navicat也成功连接.

4.2 命名管道和共享内存
-
两个需要进程通信的进程在同一台服务器上,可以使用命名管道.
-
References:
https://www.jianshu.com/p/c1015f5ffa74
进程间的通信方式:
管道: 匿名管道和命名管道(FIFO)
消息队列
信号量
共享内存
套接字
4.3 UNIX 域套接字
- 只能在MySQL客户端和数据库实例在同一台服务器上这种情况下使用














 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









