






01引言
数据量的爆炸式增长让许多系统面临前所未有的性能挑战,尤其是当单表数据量达到千万级别时,传统的数据库设计往往难以应对,导致查询变慢、写入延迟、甚至系统崩溃。本文将分享一个真实的案例,通过搭建数据库读写分离集群并结合分库分表技术,成功解决了大规模数据存储与高效访问的难题,实现了系统性能的显著提升。
02案例背景
某国企单位的内部信息系统的数据表突破千万后,系统性能开始告急。用户在执行复杂查询操作时,响应时间从毫秒级飙升到秒级。运维团队每天都要面对大量的慢查询告警,数据库维护成本也居高不下。显然,单表设计已经无法满足业务需求,需要从数据库层面对系统进行优化。
03问题分析
经过深入分析,我们发现单表数据量过大是导致性能问题的根本原因。具体表现为:
(1) 索引效率下降:随着数据量增加,B+树索引的深度变深,查询时需要更多的磁盘I/O。
(2) 查询性能恶化:全表扫描的时间成本呈线性增长,复杂查询的响应时间难以接受。
(3) 数据库维护成本高:备份、恢复和索引重建等操作耗时耗力。
04解决方案
为了解决上述问题,我们决定在项目中引入 ShardingSphere-JDBC 技术,结合数据库读写分离和水平分库分表的方案,对单表数据量超过一千万的测评结果表进行优化。ShardingSphere-JDBC 是 Apache ShardingSphere 生态系统中的一个轻量级 Java 框架,专注于为关系型数据库提供 分库分表、读写分离 和 分布式事务 等能力。它通过透明化的方式,将单库单表的操作路由到多个数据库或表中,从而提升系统的扩展性和性能。
05实施过程
(1)依赖引用:我们在实施中引入shardingsphere-jdbc-core-spring-boot-starter,shardingsphere-jdbc-core-spring-boot-starter 是 Apache ShardingSphere 提供的一个 Spring Boot Starter依赖,用于简化在 Spring Boot 项目中集成 ShardingSphere-JDBC 的配置和使用。它提供了数据分片、读写分离、分布式事务等功能,满足了我们的业务需求。

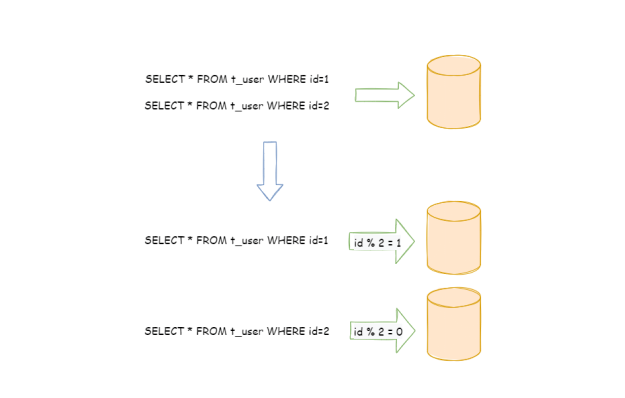
(2)拆分规则:结合系统业务需求,我们选用了水平分片,水平分片又称为横向拆分。相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
(3)分片字段选用:在分片字段的选择上,我们最初计划根据数据主题的发起年份进行水平分片。然而,结合数据结果表的结构,我们发现现有字段中并不存在符合该要求的字段。此外,若新增该字段,所需修改的内容较多,影响范围较大。因此,我们调整了思路,决定将数据结果表中的数据主题ID作为分片字段,并通过数据主题ID查询其发起的年份,从而实现动态路由的效果。
(4)分片表主键生成策略:在分片表的主键生成策略上,我们采用了分布式唯一ID生成机制,以确保在分片环境中主键的全局唯一性和有序性。具体实现上,我们结合了时间戳、分片标识和序列号,通过雪花算法(Snowflake Algorithm)生成主键。这种策略不仅能够避免单点故障,还能在高并发场景下保证主键生成的效率和性能。同时,我们为每个分片表设置了独立的主键生成规则,以防止跨分片的主键冲突,确保数据的完整性和一致性。

(5)自定义分片算法:在自定义分片算法的实现中,我们根据业务需求和数据特点,设计了灵活且高效的分片策略。
自定义分片算法配置类

(6)基于ShardingSphere-JDBC实现读写分离,采用一主两从的架构设计。主库负责处理写操作(如 INSERT、UPDATE、DELETE),两个从库负责分担读操作(如 SELECT),从而有效提升数据库的并发处理能力和系统性能。通过ShardingSphere-JDBC的自动路由机制,读写请求能够智能分发到主库或从库,同时确保数据在主从之间的实时同步,兼顾性能与数据一致性。


(7)最后,还需要将需要分片的数据表加入配置中,同时编写相关方法动态获取真实的表名称列表

(8)效果验证:
查看运行日志发现一主两从数据源对象均初始化成功。
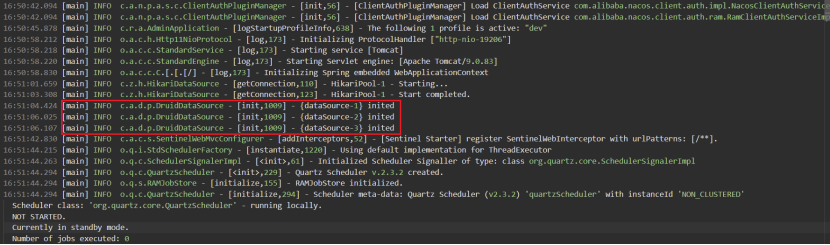
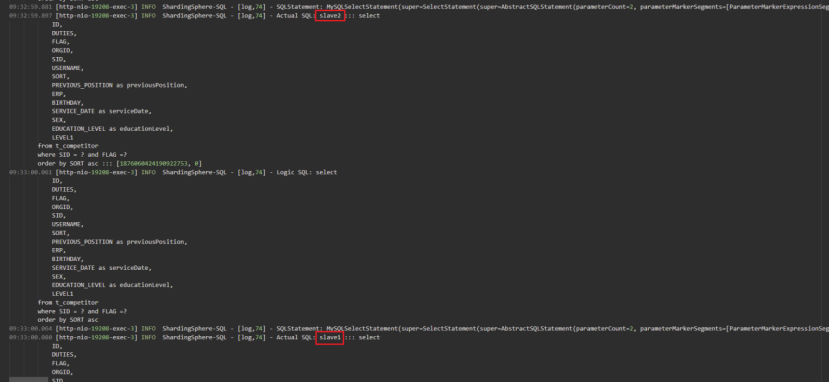
执行查询操作,因为我们配置的负载策略是ROUND_ROBIN,所以请求被均匀的分发到两个从库上。
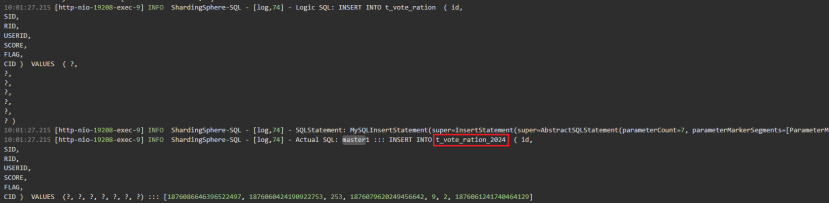
在执行分片表的写入操作时,我们观察到自定义分片算法已成功生效。ShardingSphere-JDBC 对 SQL 进行了拦截,并通过 SQL 重写机制,将数据根据分片规则准确路由至目标表 2024 中。
06结语万级
通过引入 ShardingSphere-JDBC,我们成功解决了千万级数据量带来的性能瓶颈,让系统重新焕发活力。具体成果如下:
(1) 数据量优化:单表数据量从3000万+ 降低到每个分片600万条+,显著减轻了单表压力。
(2) 查询性能提升:复杂查询的接口响应时间从5秒以上降低到1秒以内,用户体验大幅改善。
(3) 写入效率提高:高并发写入场景下的延迟从1秒降低到100 毫秒,系统吞吐量显著提升。
(4) 运维成本降低:备份和索引重建时间缩短了70%,系统维护更加高效。
这一案例充分证明了分库分表和读写分离在大数据场景下的价值。通过 ShardingSphere-JDBC 的灵活配置和高效路由,我们不仅解决了当前问题,还为未来的业务扩展奠定了坚实的基础。
在大数据时代,面对海量数据的挑战,分库分表无疑是提升系统性能的一把利器。希望本文的案例和经验能为面临类似问题的读者提供参考和启发。同时,我们也鼓励每一位技术人深入学习和实践,探索更多高效的数据处理方案,为业务发展提供强有力的技术支撑。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









