







感知机属于线性分类模型,1957年由Rosenblatt提出,可以看成单层的神经网络。
感知机虽然简单,但是其工作原理、模型选择方式,仍然适用于后来复杂的神经网络如CNN,RNN等身上。从进化角度说,感知机可能相当于草履虫,但是我们如今地球上复杂的高等生物不也是从低等生物上慢慢进化来的么。
模型结构
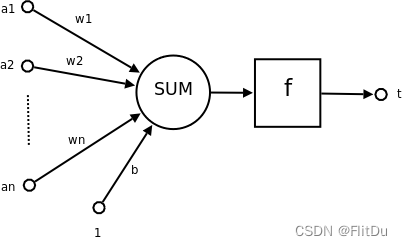

学习方法
损失函数 L 为误分类点到超平面的距离
L ( w , b ) = − Σ y i ( w ∗ x i + b ) L(w, b) = -\Sigma{y_{i}(w*x_{i} + b)} L(w,b)=−Σyi(w∗xi+b)
l >=0时,更新参数
l<0 不更新
属于误分类驱动
更新算法采用随机梯度下降
代码实现
初级
定义模型
class Perceptron:
def __init__(self):
self.w = torch.zeros_like(w0,requires_grad=True)
self.b = torch.zeros_like(b0,requires_grad=True)
#正向传播
def forward(self,x):
return x@self.w + self.b
def _sign(self, value):
# 分类预测函数
if value< 0:
return -1
return 1
# 损失函数
def loss_func(self,y_pred,y_true):
return -y_true * y_pred
model = Perceptron()
# 训练模型
def train_step(model, features, labels):
predictions = model.forward(features)
loss = model.loss_func(predictions,labels)
print(f'loss:{loss}')
if loss>=0:
print('更新梯度')
print(f'更新前 w:{model.w}')
print(f'更新前 b:{model.b}')
# 反向传播求梯度
loss.backward()
# 使用torch.no_grad()避免梯度记录,也可以通过操作 model.w.data 实现避免梯度记录
with torch.no_grad():
# 梯度下降法更新参数
model.w -= 1*model.w.grad
model.b -= 1*model.b.grad
# 梯度清零
model.w.grad.zero_()
model.b.grad.zero_()
return loss
参考 p40 例2.1, 最终得到的分类曲线如下 :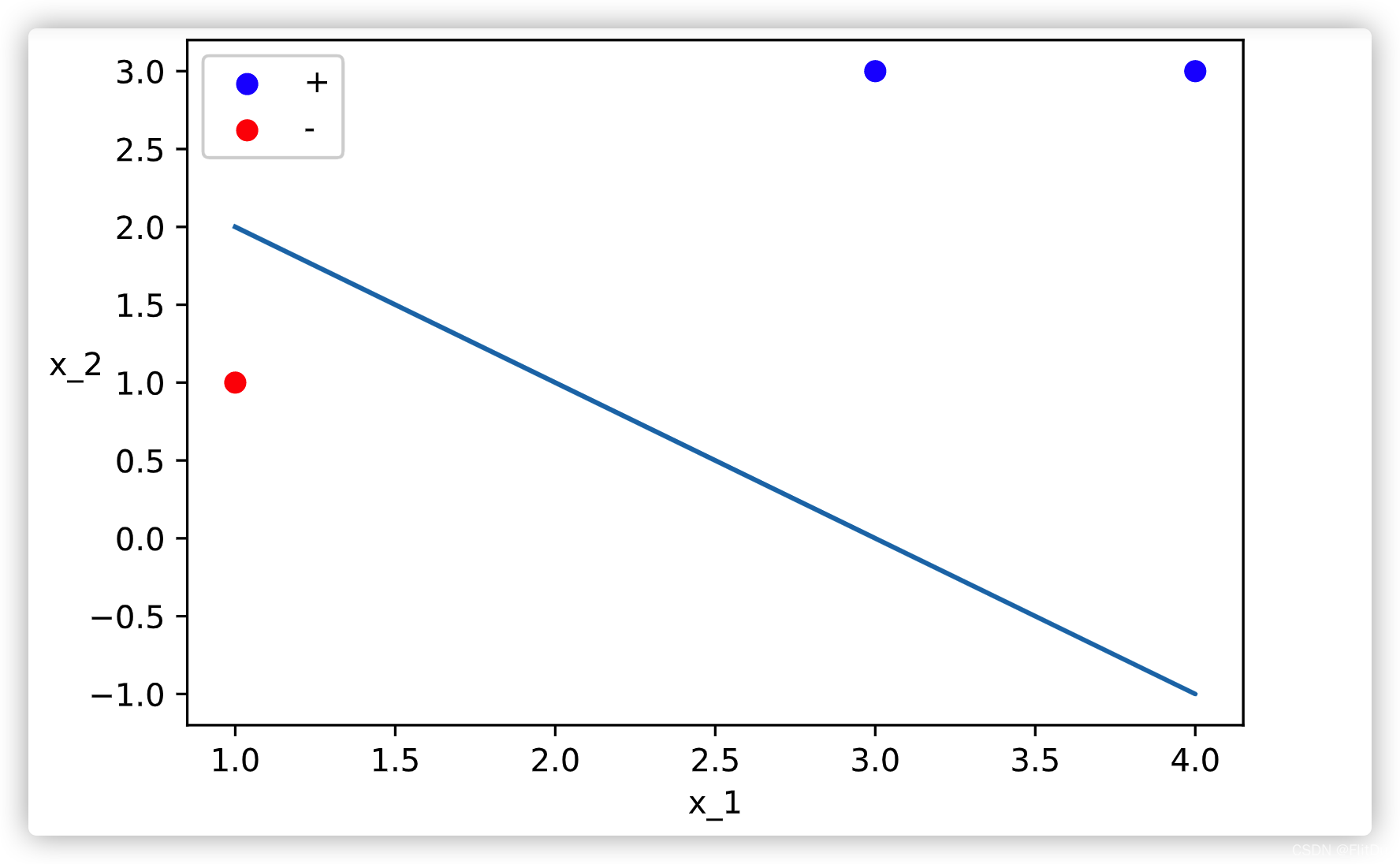
API 调用
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.fc1 = nn.Linear(2,1)
self._init_parameters()
# 正向传播
def forward(self,x):
y = self.fc1(x)
return y
# 损失函数
def loss_func(self,y_pred,y_true):
return -y_true * y_pred
# 优化器
@property
def optimizer(self):
return torch.optim.SGD(self.parameters(),lr = 1)
def _init_parameters(self):
# 自定义参数初始化
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.zeros_(m.weight.data)
nn.init.constant_(m.bias.data, 0)
model = ToyModel()















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









