







代码结构分析
- 代码来源:GitHub
examples-hacker_news
执行顺序

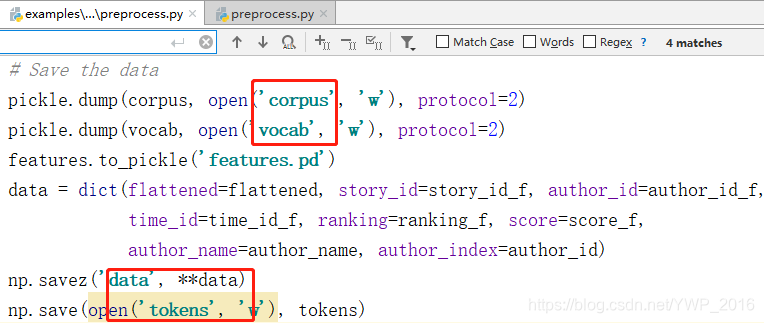
- 以examples-hacker_news(新闻)为例。据我观察,首先,应当运行data-preprocess.py(此代码同时包括用于下载数据的代码),进行数据预处理工作,处理完成后保存产物(如下图):
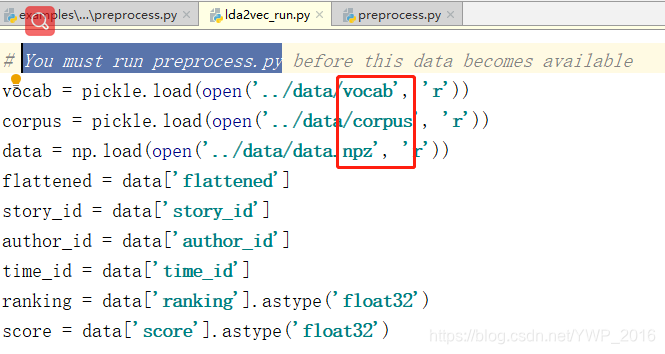
- 随后,运行examples\hacker_news\lda2vec-lda2vec_run.py,正式跑模型。(该程序用到了预处理产物,生成lda2vec.hdf5)
注意事项
- 慎用"print"
调试代码时常加入大量print 监测每一步的输出。但是对于大批量数据处理,print 往往增加几十倍的耗时,严重影响效率。
- 进度条
#参考:https://blog.csdn.net/The_Time_Runner/article/details/87735801
#通过sys.stdout.write()实现进度条(直接粘到代码ok)
import time,sys
for i in range(100):
percent = i / 100
sys.stdout.write("\r{0}{1}".format("|"*i , '%.2f%%' % (percent * 100)))
sys.stdout.flush()
time.sleep(1)
preprocess.py
# Author: Chris Moody <chrisemoody@gmail.com>
# License: MIT
# This example loads a large 800MB Hacker News comments dataset
# and preprocesses it. This can take a few hours, and a lot of
# memory, so please be patient!
from lda2vec import preprocess, Corpus
import numpy as np
import pandas as pd
import logging
import cPickle as pickle
import os.path
logging.basicConfig()
max_length = 250 # Limit of 250 words per comment
min_author_comments = 50 # Exclude authors with fewer comments
nrows = None # Number of rows of file to read; None reads in full file
fn = "hacker_news_comments.csv"
url = "https://zenodo.org/record/45901/files/hacker_news_comments.csv"
if not os.path.exists(fn):
import requests
response = requests.get(url, stream=True, timeout=2400)
with open(fn, 'w') as fh:
# Iterate over 1MB chunks
for data in response.iter_content(1024**2):
fh.write(data)
features = []
# Convert to unicode (spaCy only works with unicode)
features = pd.read_csv(fn, encoding='utf8', nrows=nrows)
# Convert all integer arrays to int32
for col, dtype in zip(features.columns, features.dtypes):
if dtype is np.dtype('int64'):
features[col] = features[col].astype('int32')
# Tokenize the texts
# If this fails it's likely spacy. Install a recent spacy version.
# Only the most recent versions have tokenization of noun phrases
# I'm using SHA dfd1a1d3a24b4ef5904975268c1bbb13ae1a32ff
# Also try running python -m spacy.en.download all --force
texts = features.pop('comment_text').values
tokens, vocab = preprocess.tokenize(texts, max_length, n_threads=4,
merge=True)
del texts
# Make a ranked list of rare vs frequent words
corpus = Corpus()
corpus.update_word_count(tokens)
corpus.finalize()
# The tokenization uses spaCy indices, and so may have gaps
# between indices for words that aren't present in our dataset.
# This builds a new compact index
compact = corpus.to_compact(tokens)
# Remove extremely rare words
pruned = corpus.filter_count(compact, min_count=10)
# Words tend to have power law frequency, so selectively
# downsample the most prevalent words
clean = corpus.subsample_frequent(pruned)
print "n_words", np.unique(clean).max()
# Extract numpy arrays over the fields we want covered by topics
# Convert to categorical variables
author_counts = features['comment_author'].value_counts()
to_remove = author_counts[author_counts < min_author_comments].index
mask = features['comment_author'].isin(to_remove).values
author_name = features['comment_author'].values.copy()
author_name[mask] = 'infrequent_author'
features['comment_author'] = author_name
authors = pd.Categorical(features['comment_author'])
author_id = authors.codes
author_name = authors.categories
story_id = pd.Categorical(features['story_id']).codes
# Chop timestamps into days
story_time = pd.to_datetime(features['story_time'], unit='s')
days_since = (story_time - story_time.min()) / pd.Timedelta('1 day')
time_id = days_since.astype('int32')
features['story_id_codes'] = story_id
features['author_id_codes'] = story_id
features['time_id_codes'] = time_id
print "n_authors", author_id.max()
print "n_stories", story_id.max()
print "n_times", time_id.max()
# Extract outcome supervised features
ranking = features['comment_ranking'].values
score = features['story_comment_count'].values
# Now flatten a 2D array of document per row and word position
# per column to a 1D array of words. This will also remove skips
# and OoV words
feature_arrs = (story_id, author_id, time_id, ranking, score)
flattened, features_flat = corpus.compact_to_flat(pruned, *feature_arrs)
# Flattened feature arrays
(story_id_f, author_id_f, time_id_f, ranking_f, score_f) = features_flat
# Save the data
pickle.dump(corpus, open('corpus', 'w'), protocol=2)
pickle.dump(vocab, open('vocab', 'w'), protocol=2)
features.to_pickle('features.pd')
data = dict(flattened=flattened, story_id=story_id_f, author_id=author_id_f,
time_id=time_id_f, ranking=ranking_f, score=score_f,
author_name=author_name, author_index=author_id)
np.savez('data', **data)
np.save(open('tokens', 'w'), tokens)















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









