






集合分类:
1,集合:
集合又称为容器,用于存储、提取、删除数据。JDK提供的集合API都包含在 java.util 包内。
集合框架两大分支:Collection接口和Map接口


2,集合可以分为单值和双值
单值
list:arrayList,LinkedList
set:HashSet,TreeSet
(set集合就是map集合的一部分: key)
双值的
map:Hashmap, treemap
浅析
List
有序(有元素的插入顺序),可重复的集合
ArrayList
底层实现: 数组
数组的扩容: 数组的元素个数超过10个的时候开始扩容的工作
数组扩容----数组的拷贝的过程 消耗资源的过程
下述数据来源
如果使用无参构造,初始化数组的长度0
第一次添加元素的时候开始 长度10
以后的每次扩容 1.5倍进行扩容
1000
10 15 22 33 50 75 112 。。。。
数组扩容----数组的拷贝的过程 消耗资源的过程
使用有参构造 参数:代表的是我们数组初始化的长度
参数500---750----1000+
当arraylist中元素个数很多的时候 ,最好使用有参构造,减少底层数组的扩容的次数,提升性能
分析下边代码执行过程:
List list=new ArrayList();
for (int i = 0; i < 20; i++) {
list.add(i);
}
1,创建对象,调用无参构造方法
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
2,elementData 是成员变量
transient Object[] elementData;
3,DEFAULTCAPACITY_EMPTY_ELEMENTDATA初始值为一个空集合,没有元素,长度为0.
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
4,add方法执行,其实是调用了ArrayList中的add方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
5,size为int类型,是成员变量,则默认值为0.
private int size;
6,ensureCapacityInternal方法
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {//判断
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//取两者中的最大值。
}
ensureExplicitCapacity(minCapacity);
}
7,ensureExplicitCapacity方法
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
8,重点为grow方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
数组特点:
查询快 增删慢
因为数组是有索引的,通过下标直接访问
LinkedList
线性链表:
单向链表:
只有一个方向的链表,上一个元素知道下一个元素,但是下一个元素不知道上一个元素的,访问的时候只能从一端开始
双向链表:
两个方向的链表,每一个元素,都知道自己的上一个元素和下一个元素是谁,可以从两个方向访问
链表结构中的每一个元素 就叫做node 对象
node的结构为
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
add方法执行过程体现扩容规则
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}
扩容机制:
由于它的底层是用双向链表实现的,所以它对元素的增加、删除效率比ArrayList好;
它是一个双向链表,没有初始化大小,也没有扩容的机制,就是一直在前面或者后面新增。
优点:
增删快 查询慢
Set
set集合:无序(没有插入顺序的),不可重复的
set集合就是map集合的一部分(key部分)
HashSet
HashSet:HashMap中k-v中的k部分(可先查看底部map讲解)
底层结构: 数组(初始容量16)+链表(单向的)+树(红黑树)
元素存储的时候先对元素(key)取hash值,见博客
数组扩容的节点:
数组进行扩容的阀值 ,数组的容量达到整个数组的0.75就会进行数组的扩容的操作 :每次扩容 扩大2倍 :16*0.75=12。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
newCap = oldCap << 1
TreeSet
1,TreeSet : TreeMap中k-v中的k部分
特点:有序(元素值是排序的) 不可重复的
底层结构:红黑树
排序方式:自然排序
要求:我们的set集合中存放的元素是有排序能力的(如果是自定义对象,需要实现compare比较器)
2,TreeSet使用,实现比较器简述:
add方法:此处main方法省略
Set set=new TreeSet();
set.add(12);
set.add(3);
set.add(7);
set.add(45);
set.add(67);
set.add(33);
for (Object o : set) {
System.out.print(o+",");
}
输出有顺序
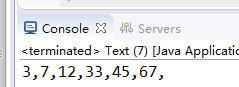
例, 实现比较器,重写比较方法:
创建student类
public class Student implements Comparable<Student>{
private String number;
private String name;
private int scores;
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScores() {
return scores;
}
public void setScores(int scores) {
this.scores = scores;
}
public Student(String number, String name, int i) {
super();
this.number = number;
this.name = name;
this.scores = i;
}
@Override
public String toString() { //重写tostring方法。
return "Student [number=" + number + ", name=" + name + ", scores=" + scores + "]";
}
@Override //重写比较方法
public int compareTo(Student o) {
if(o!=null) {//scores指定了比较元素。
//return this.scores-o.scores==0;//如果只是该行语句return this.scores-o.scores;会将重复的数去掉。对分数相同的学生,我们比较学号。
//return this.scores-o.scores==0?this.number.compareTo(o.name):this.scores-o.scores;//实现的compareTo方法,从小到大排序。
return o.scores-this.scores==0?this.number.compareTo(o.name):o.scores-this.scores;//从大到小排序。
}
return 0;//返回0,说明两个数相等,按照set集合的比较规则,相同的数只是输出一个。返回正数说明this.scores大于o.scores.
}
}
测试类中代码如下:
import java.util.Set;
import java.util.TreeSet;
public class Text {
public static void main(String[] args) {
Set<Student> set=new TreeSet<Student>();//可以指定Student泛型。
set.add(new Student("20150130","tom",77));
set.add(new Student("20150132","tim",73));
set.add(new Student("20150134","jim",67));
set.add(new Student("20150135","jack",67));
set.add(new Student("20150136","lucy",97));
for (Student student : set) {
System.out.println(student);// 直接输出报错:spring.Student cannot be cast to java.lang.Comparable,因为对象不具有比较性。实现比较接口,重写比较方法。
}
}
}
输出结果如下:
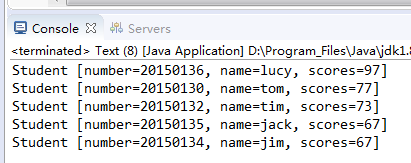
Map
以kv键值对的形式对元素进行存储
HashMap
底层结构:数组(16)+链表(单向链表)+树(红黑树)
默认的初始化容量(底层数组)1<<4 – 16
链表结构转换为树结构的最大阀值:8(1.8之后的)
树结构转换为链表结构的阀值:6
默认的最大容量:1<<30 2的30次方
加载因子:0.75 (存储到数组0.75后就会2倍扩容)
数组扩容的节点:
数组进行扩容的阀值 数组的容量达到整个数组的0.75就会进行数组的扩容的操作(每次扩容 ,扩大2倍) 16*0.75=12
static final float DEFAULT_LOAD_FACTOR = 0.75f;
newCap = oldCap << 1















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









