






前言
HashMap最早在出现在JDK1.2中,底层基于散列算法实现。HashMap允许出现null键和null值,当出现null键时,相对应的值为0,在HashMap中,键值对的顺序并不固定。而且HashMap是非线程安全类,在多线程环境下容易出现安全问题。
提示:以下是本篇文章正文内容,下面案例可供参考
一、实现简单的HashMap
给定7个字符串,存放到数组中,要求查询字符串的时间复杂度为O(1),因此,不能通过循环的方式遍历数组,所以需要为每个字符串赋予一个ID值,根据ID可定位到字符串在数组中的位置。
如何赋予每个字符串一个ID呢?可以想到使用HashCode来获取字符串的数字信息,但HashCode的范围在[-2147483648, 2147483647],对字符串求HashCode后得到的数字不适合作为ID,那么进一步对HashCode进行处理,使其与数组长度做与运算,将得到一个数组下标,如果两个字符串得到了相同的数组下标,那么此下标下的数组则存储这两个字符串,以此类推。
@Test
public void test_128hash() {
// 初始化一组字符串
List<String> list = new ArrayList<>();
list.add("itsu");
list.add("lsnt");
list.add("wuqx");
list.add("sdhu");
list.add("xmeu");
list.add("zxms");
list.add("asxb");
// 定义要存放的数组
String[] tab = new String[8];
// 循环存放
for (String key : list) {
int idx = key.hashCode() & (tab.length - 1); // 计算索引位置
System.out.println(String.format("key值=%s Idx=%d", key, idx));
if (null == tab[idx]) {
tab[idx] = key;
continue;
}
tab[idx] = tab[idx] + "->" + key;
}
// 输出测试结果
System.out.println("测试结果:" + JSON.toJSONString(tab));
}
测试结果如下所示:
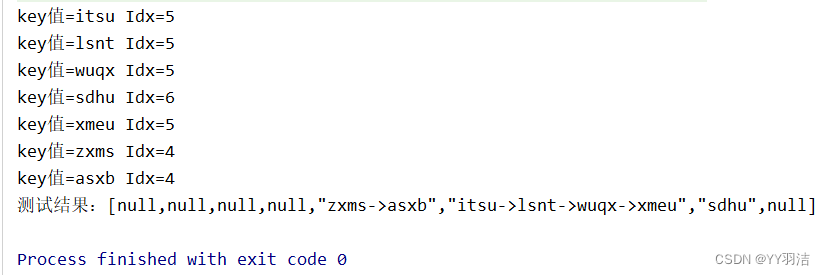
可以看到,数组有的位置中甚至存储了四个字符串,而5个位置却没有存储任何字符串,数组的利用率很低。
在实验中,定义了数组的长度为8,即2的3次幂,这样的好处是可以提高位运算能力。因为HashCode和数组长度做与运算,若数组长度为2的次幂,那么Hash % length == Hash &(length-1),相对于%,&操作可以提高运算效率。
虽然以上实现了一个简单的HashMap,但实验表明,数据并不是很好地散列分布,碰撞严重,其实是失去了散列表存放的意义。另外,既然需要初始化数组的大小为2的幂次方,那么如何初始化。而且,随着链表长度的增加,如何去优化。最后,如果需要对数组进行扩容,原有的元素如何拆分到新的位置上。
二、扰动函数
以下是java8的散列值扰动函数,用于优化散列效果:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
2.1扰动函数的作用
HashMap源码这里使用位移运算,将哈希值右移16位,得到的值即为哈希值长度的一半,接着与原哈希值做异或运算,这样处理混合了哈希值的高位和低位,增大了随机性,使数据更加均衡地散列,减少碰撞的几率。
2.2扰动函数实验
扰动函数使用哈希值的高位和低位做异或操作,来加大低位的随机性,以下实验来验证扰动函数的作用。
实验准备:
1.十万个单词的单词库
2.长度为128的数组
3.分别使用扰动函数和不使用扰动函数,统计十万个单词被分配到数组的每个格子的数量。
4.根据每个格子数量,绘制波动曲线,观察扰动函数的作用。
扰动函数
public class Disturb {
public static int disturbHashIdx(String key, int size) {
return (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
}
public static int hashIdx(String key, int size) {
return (size - 1) & key.hashCode();
}
}
测试函数
// 10万单词已经初始化到words中
@Test
public void test_disturb() {
Map<Integer, Integer> map = new HashMap<>(16);
for (String word : words) {
// 使用扰动函数
int idx = Disturb.disturbHashIdx(word, 128);
// 不使用扰动函数
// int idx = Disturb.hashIdx(word, 128);
if (map.containsKey(idx)) {
Integer integer = map.get(idx);
map.put(idx, ++integer);
} else {
map.put(idx, 1);
}
}
System.out.println(map.values());
}
三、初始化容量和负载因子
上文提到散列数组需要一个2的幂次方的长度,那么初始化的时候如何处理呢?
3.1HashMap的初始化
HashMap初始化方法
public HashMap(int initialCapacity, float loadFactor) {
...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
阈值threshold通过tableSizeFor进行计算,tableSizeFor方法如下所示
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
其中,MAXIMUM_CAPACITY = 1 << 30,为HashMap的最大容量,通过将n不断右移,是为了将二进制的各个位置都填上1,这样将会得到2的幂次方减1,再将结果加1返回。
3.2负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
在HashMap中,负载因子决定了数据量达到多少时,HashMap将进行扩容。可能会出现这样的情况, 当数据量比数组容量大时,数组依然可能没有被占满,而是会在某些位置出现碰撞,于是将在数组的某一位置用链表存放,这失去了Map的数组的能力。
因此,当容量已经占满3/4时,数组就需要进行扩容了。
3.2扩容元素拆分
当数组长度不足,则需要进行扩容。jdk1.7中需要重新计算hash值,而jdk1.8中不需要重新计算,通过下面的实验来探索其中的原理。
@Test
public void test_hashMap() {
List<String> list = new ArrayList<>();
list.add("jlkk");
list.add("lopi");
list.add("jmdw");
list.add("e4we");
list.add("io98");
list.add("nmhg");
list.add("vfg6");
list.add("gfrt");
list.add("alpo");
list.add("vfbh");
list.add("bnhj");
list.add("zuio");
list.add("iu8e");
list.add("yhjk");
list.add("plop");
list.add("dd0p");
for (String key : list) {
int hash = key.hashCode() ^ (key.hashCode() >>> 16);
System.out.println("字符串:" + key + " \tIdx(16):" + ((16 - 1) & hash) + " \tBit值:" + Integer.toBinaryString(hash) + " - " + Integer.toBinaryString(hash & 16) + " \t\tIdx(32):" + ((
System.out.println(Integer.toBinaryString(key.hashCode()) +" "+ Integer.toBinaryString(hash) + " " + Integer.toBinaryString((32 - 1) & hash));
}
}

从实验结果中可以观察到,当hash值与原容量做与运算时,当结果为0时,扩容后的下标不变,当不为0时,扩容后的下标为原来的下标加上新增的扩容长度。
这里是引用:小傅哥bugstack虫洞栈















 2156
2156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









