









讨论第三种用于比较新旧两组子节点的方式:快速Diff 算法。正如其名,该算法的实测速度非常快。该算法最早应用于 ivi 和 inferno 这两个框架,Vue.js 3 借鉴并扩展了它。
下图比较了 ivi、inferno 以及 Vue.js 2 的性能:
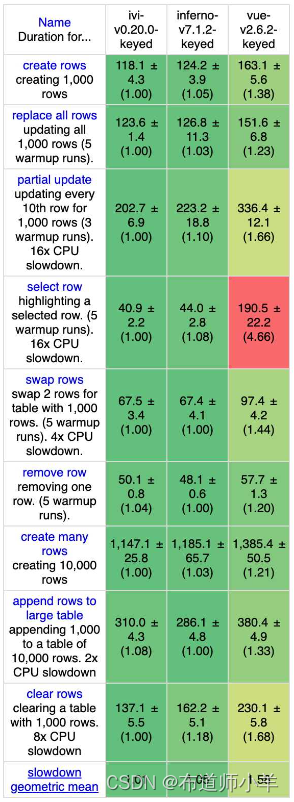
上图来自 js-framework-benchmark,从中可以看出,在DOM 操作的各个方面,ivi 和 inferno 所采用的快速 Diff 算法的性能都要稍优于 Vue.js 2 所采用的双端 Diff 算法。既然快速Diff 算法如此高效,我们有必要了解它的思路。接下来,我们就着重讨论快速 Diff 算法的实现原理。
1、相同的前置元素和后置元素
不同于简单 Diff 算法和双端 Diff 算法,快速 Diff 算法包含预处理步骤,这其实是借鉴了纯文本 Diff 算法的思路。在纯文本Diff 算法中,存在对两段文本进行预处理的过程。例如,在对两段文本进行 Diff 之前,可以先对它们进行全等比较:
01 if (text1 === text2) return
这也称为快捷路径。如果两段文本全等,那么就无须进入核心Diff 算法的步骤了。除此之外,预处理过程还会处理两段文本相同的前缀和后缀。假设有如下两段文本:
01 TEXT1: I use vue for app development
02 TEXT2: I use react for app development
通过肉眼可以很容易发现,这两段文本的头部和尾部分别有一段相同的内容,如下图所示:

上图突出显示了 TEXT1 和 TEXT2 中相同的内容。对于内容相同的问题,是不需要进行核心 Diff 操作的。因此,对于TEXT1 和 TEXT2 来说,真正需要进行 Diff 操作的部分是:
01 TEXT1: vue
02 TEXT2: react
这实际上是简化问题的一种方式。这么做的好处是,在特定情况下我们能够轻松地判断文本的插入和删除,例如:
01 TEXT1: I like you
02 TEXT2: I like you too
经过预处理,去掉这两段文本中相同的前缀内容和后缀内容之后,它将变成:
01 TEXT1:
02 TEXT2: too
可以看到,经过预处理后,TEXT1 的内容为空。这说明 TEXT2在 TEXT1 的基础上增加了字符串 too。相反,我们还可以将这两段文本的位置互换:
01 TEXT1: I like you too
02 TEXT2: I like you
这两段文本经过预处理后将变成:
01 TEXT1: too
02 TEXT2:
由此可知,TEXT2 是在 TEXT1 的基础上删除了字符串 too。
快速 Diff 算法借鉴了纯文本 Diff 算法中预处理的步骤。以下图给出的两组子节点为例:
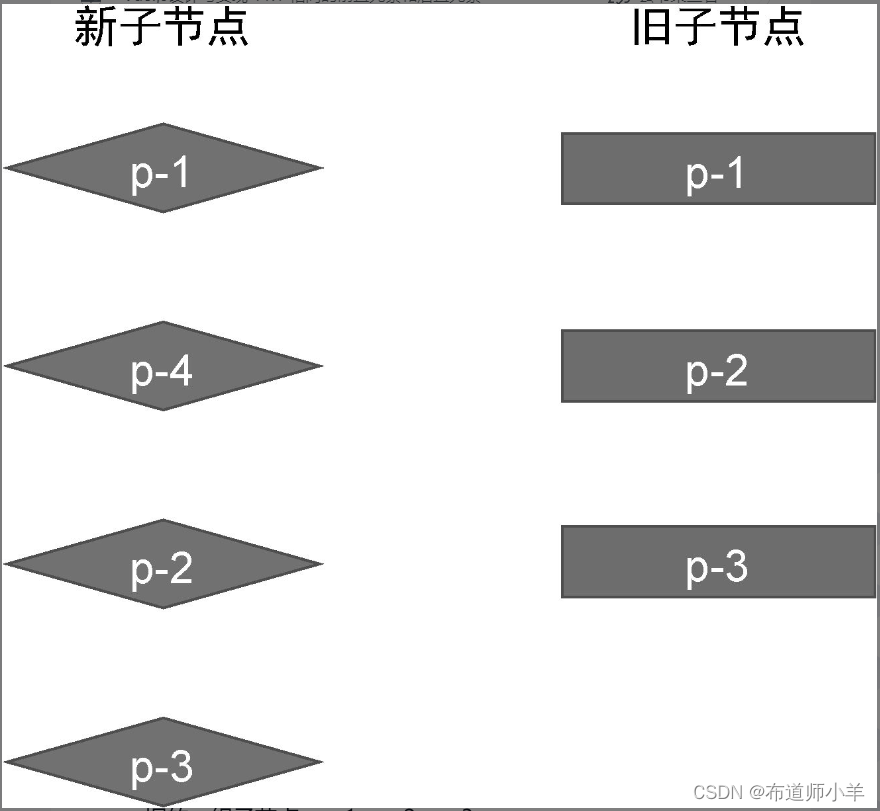
这两组子节点的顺序如下:
- 旧的一组子节点:p-1、p-2、p-3。
- 新的一组子节点:p-1、p-4、p-2、p-3。
通过观察可以发现,两组子节点具有相同的前置节点 p-1,以及相同的后置节点 p-2 和 p-3,如下图所示:
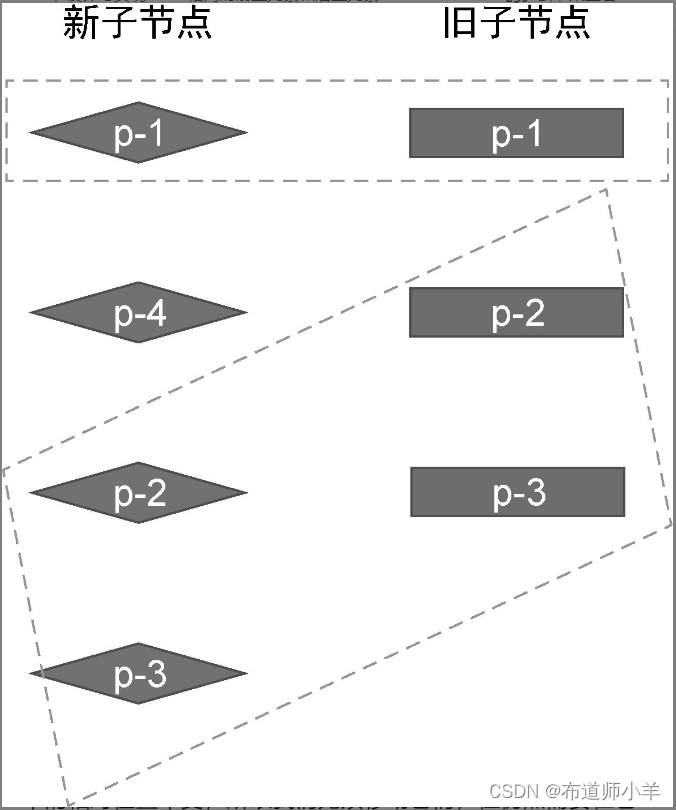
对于相同的前置节点和后置节点,由于它们在新旧两组子节点中的相对位置不变,所以我们无须移动它们,但仍然需要在它们之间打补丁。
对于前置节点,我们可以建立索引 j,其初始值为 0,用来指向两组子节点的开头,如下图所示:

然后开启一个 while 循环,让索引 j 递增,直到遇到不相同的节点为止,如下面 patchKeyedChildren 函数的代码所示:
01 function patchKeyedChildren(n1, n2, container) {
02 const newChildren = n2.children
03 const oldChildren = n1.children
04 // 处理相同的前置节点
05 // 索引 j 指向新旧两组子节点的开头
06 let j = 0
07 let oldVNode = oldChildren[j]
08 let newVNode = newChildren[j]
09 // while 循环向后遍历,直到遇到拥有不同 key 值的节点为止
10 while (oldVNode.key === newVNode.key) {
11 // 调用 patch 函数进行更新
12 patch(oldVNode, newVNode, container)
13 // 更新索引 j,让其递增
14 j++
15 oldVNode = oldChildren[j]
16 newVNode = newChildren[j]
17 }
18
19 }
在上面这段代码中,我们使用 while 循环查找所有相同的前置节点,并调用 patch 函数进行打补丁,直到遇到 key 值不同的节点为止。这样,我们就完成了对前置节点的更新。在这一步更新操作过后,新旧两组子节点的状态如下图所示:
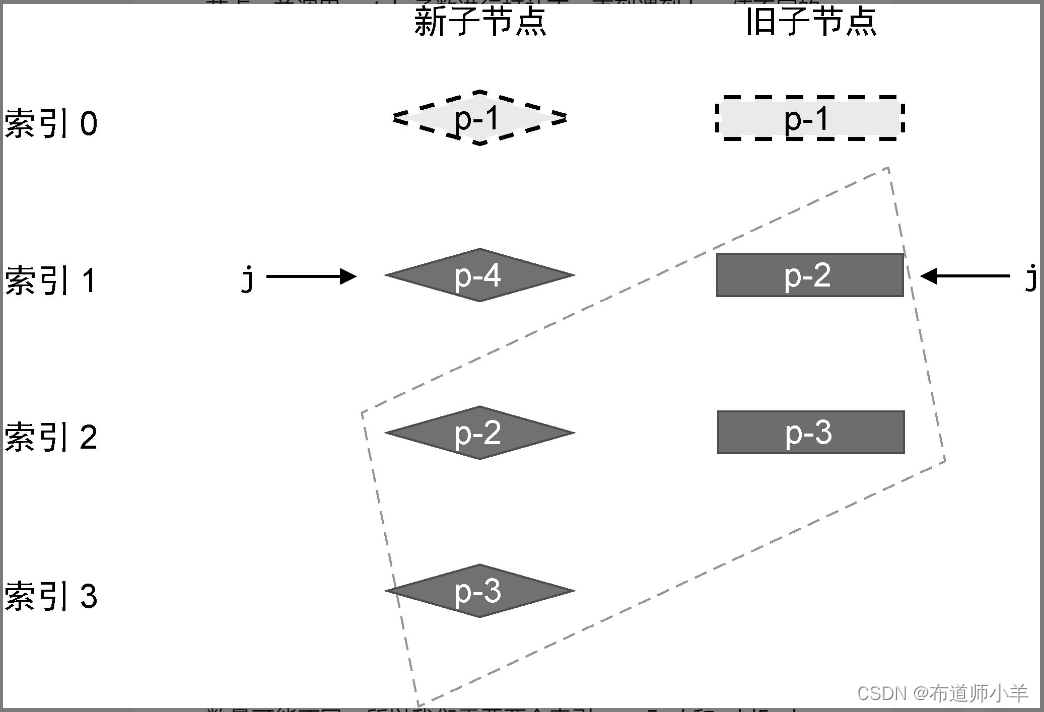
这里需要注意的是,当 while 循环终止时,索引 j 的值为 1。接下来,我们需要处理相同的后置节点。由于新旧两组子节点的数量可能不同,所以我们需要两个索引 newEnd 和 oldEnd,分别指向新旧两组子节点中的最后一个节点,如下图所示:
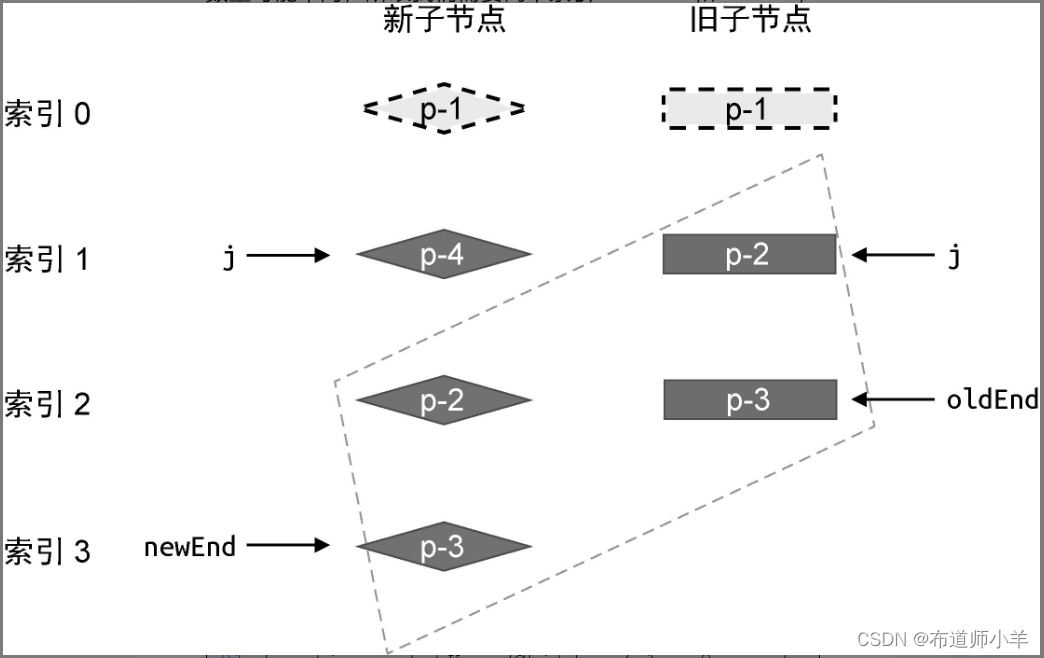
然后,再开启一个 while 循环,并从后向前遍历这两组子节点,直到遇到 key 值不同的节点为止,如下面的代码所示:
01 function patchKeyedChildren(n1, n2, container) {
02 const newChildren = n2.children
03 const oldChildren = n1.children
04 // 更新相同的前置节点
05 let j = 0
06 let oldVNode = oldChildren[j]
07 let newVNode = newChildren[j]
08 while (oldVNode.key === newVNode.key) {
09 patch(oldVNode, newVNode, container)
10 j++
11 oldVNode = oldChildren[j]
12 newVNode = newChildren[j]
13 }
14
15 // 更新相同的后置节点
16 // 索引 oldEnd 指向旧的一组子节点的最后一个节点
17 let oldEnd = oldChildren.length - 1
18 // 索引 newEnd 指向新的一组子节点的最后一个节点
19 let newEnd = newChildren.length - 1
20
21 oldVNode = oldChildren[oldEnd]
22 newVNode = newChildren[newEnd]
23
24 // while 循环从后向前遍历,直到遇到拥有不同 key 值的节点为止
25 while (oldVNode.key === newVNode.key) {
26 // 调用 patch 函数进行更新
27 patch(oldVNode, newVNode, container)
28 // 递减 oldEnd 和 nextEnd
29 oldEnd--
30 newEnd--
31 oldVNode = oldChildren[oldEnd]
32 newVNode = newChildren[newEnd]
33 }
34
35 }
与处理相同的前置节点一样,在 while 循环内,需要调用patch 函数进行打补丁,然后递减两个索引 oldEnd、newEnd 的值。在这一步更新操作过后,新旧两组子节点的状态如下图所示:
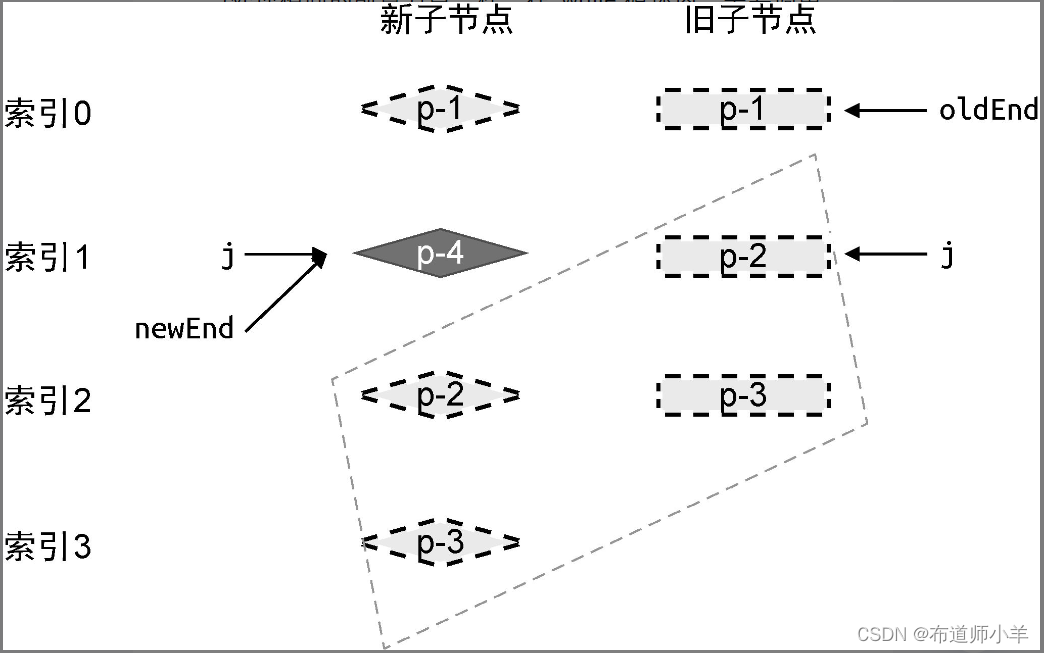
由上图可知,当相同的前置节点和后置节点被处理完毕后,旧的一组子节点已经全部被处理了,而在新的一组子节点中,还遗留了一个未被处理的节点 p-4。其实不难发现,节点 p-4是一个新增节点。那么,如何用程序得出“节点 p-4 是新增节点”这个结论呢?这需要我们观察三个索引 j、newEnd 和oldEnd 之间的关系:
- 条件一 oldEnd < j 成立:说明在预处理过程中,所有旧子节点都处理完毕了。
- 条件二 newEnd >= j 成立:说明在预处理过后,在新的一组子节点中,仍然有未被处理的节点,而这些遗留的节点将被视作新增节点。
如果条件一和条件二同时成立,说明在新的一组子节点中,存在遗留节点,且这些节点都是新增节点。因此我们需要将它们挂载到正确的位置,如下图所示:
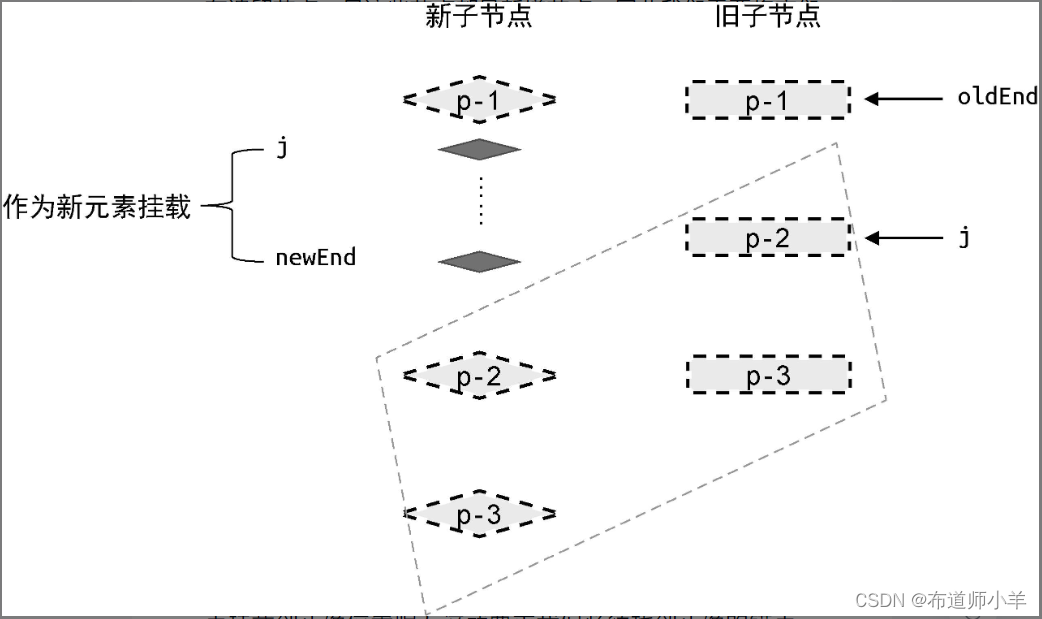
在新的一组子节点中,索引值处于 j 和 newEnd 之间的任何节点都需要作为新的子节点进行挂载。那么,应该怎样将这些节点挂载到正确位置呢?这就要求我们必须找到正确的锚点元素。观察上图 中新的一组子节点可知,新增节点应该挂载到节点 p-2 所对应的真实 DOM 前面。所以,节点 p-2 对应的真实 DOM 节点就是挂载操作的锚点元素。有了这些信息,我们就可以给出具体的代码实现了,如下所示:
01 function patchKeyedChildren(n1, n2, container) {
02 const newChildren = n2.children
03 const oldChildren = n1.children
04 // 更新相同的前置节点
05 // 省略部分代码
06
07 // 更新相同的后置节点
08 // 省略部分代码
09
10 // 预处理完毕后,如果满足如下条件,则说明从 j --> newEnd 之间的节点应作为新节点插入
11 if (j > oldEnd && j <= newEnd) {
12 // 锚点的索引
13 const anchorIndex = newEnd + 1
14 // 锚点元素
15 const anchor = anchorIndex < newChildren.length ? newChildren[anchorIndex].el : null
16 // 采用 while 循环,调用 patch 函数逐个挂载新增节点
17 while (j <= newEnd) {
18 patch(null, newChildren[j++], container, anchor)
19 }
20 }
21
22 }
在上面这段代码中,首先计算锚点的索引值(即anchorIndex)为 newEnd + 1。如果小于新的一组子节点的数量,则说明锚点元素在新的一组子节点中,所以直接使用newChildren[anchorIndex].el 作为锚点元素;否则说明索引newEnd 对应的节点已经是尾部节点了,这时无须提供锚点元素。有了锚点元素之后,我们开启了一个 while 循环,用来遍历索引 j 和索引 newEnd 之间的节点,并调用 patch 函数挂载它们。
上面的案例展示了新增节点的情况,我们再来看看删除节点的情况,如下图所示:
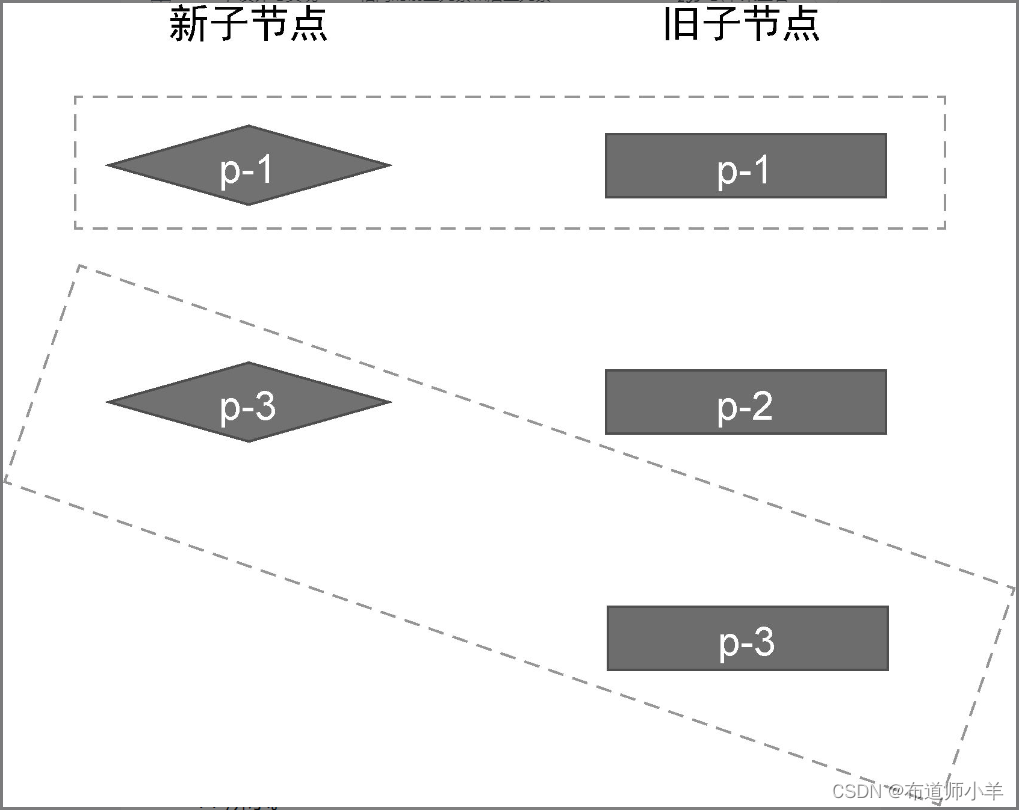
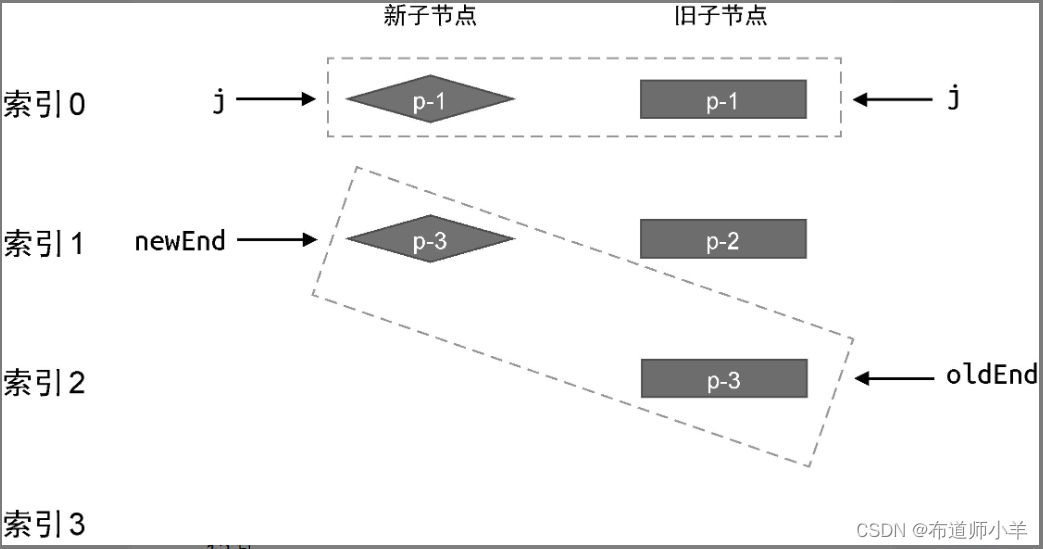
在这个例子中,新旧两组子节点的顺序如下:
- 旧的一组子节点:p-1、p-2、p-3。
- 新的一组子节点:p-1、p-3。
我们同样使用索引 j、oldEnd 和 newEnd 进行标记,如下图所示:
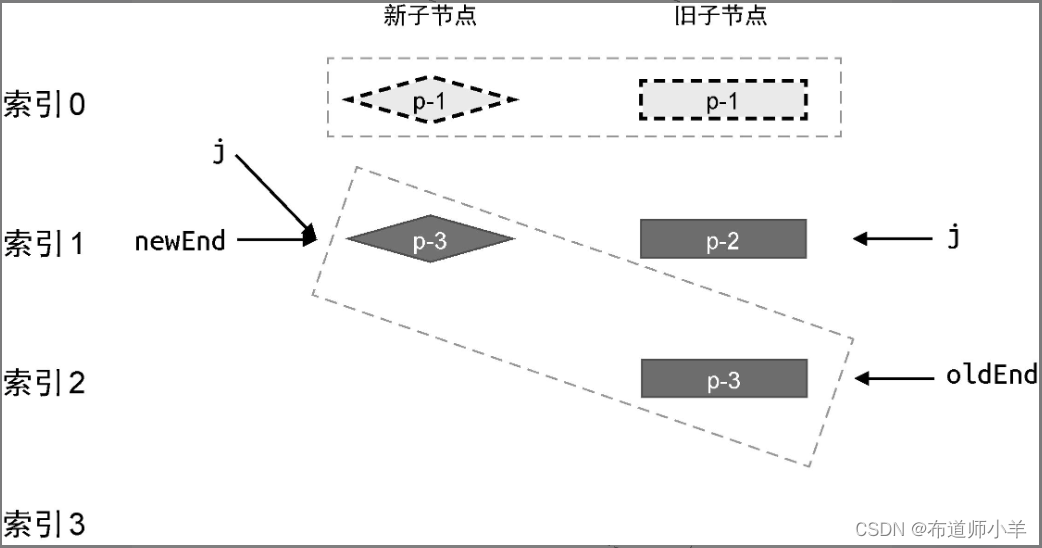
接着,对相同的前置节点进行预处理,处理后的状态如下图所示:
然后,对相同的后置节点进行预处理,处理后的状态如下图所示:
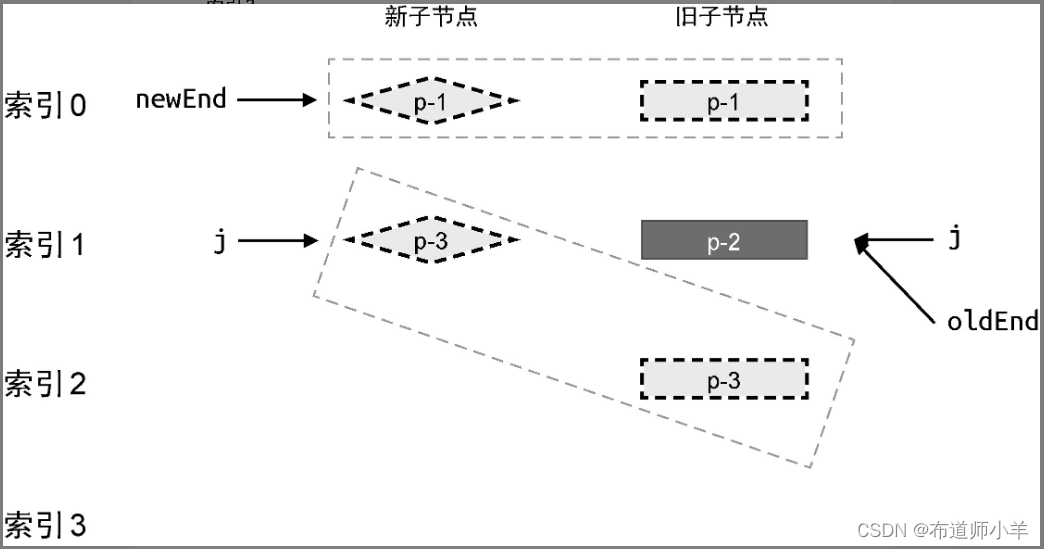
由上图可知,当相同的前置节点和后置节点全部被处理完毕后,新的一组子节点已经全部被处理完毕了,而旧的一组子节点中遗留了一个节点 p-2。这说明,应该卸载节点 p-2。实际上,遗留的节点可能有多个,如下图所示:

索引 j 和索引 oldEnd 之间的任何节点都应该被卸载,具体实现如下:
01 function patchKeyedChildren(n1, n2, container) {
02 const newChildren = n2.children
03 const oldChildren = n1.children
04 // 更新相同的前置节点
05 // 省略部分代码
06
07 // 更新相同的后置节点
08 // 省略部分代码
09
10 if (j > oldEnd && j <= newEnd) {
11 // 省略部分代码
12 } else if (j > newEnd && j <= oldEnd) {
13 // j -> oldEnd 之间的节点应该被卸载
14 while (j <= oldEnd) {
15 unmount(oldChildren[j++])
16 }
17 }
18
19 }
在上面这段代码中,我们新增了一个 else…if 分支。当满足条件j > newEnd && j <= oldEnd 时,则开启一个 while 循环,并调用 unmount 函数逐个卸载这些遗留节点。
2、判断是否需要进行 DOM 移动操作
在上一节中,我们讲解了快速 Diff 算法的预处理过程,即处理相同的前置节点和后置节点。但是,上一节给出的例子比较理想化,当处理完相同的前置节点或后置节点后,新旧两组子节点中总会有一组子节点全部被处理完毕。在这种情况下,只需要简单地挂载、卸载节点即可。但有时情况会比较复杂,如下图中给出的例子:
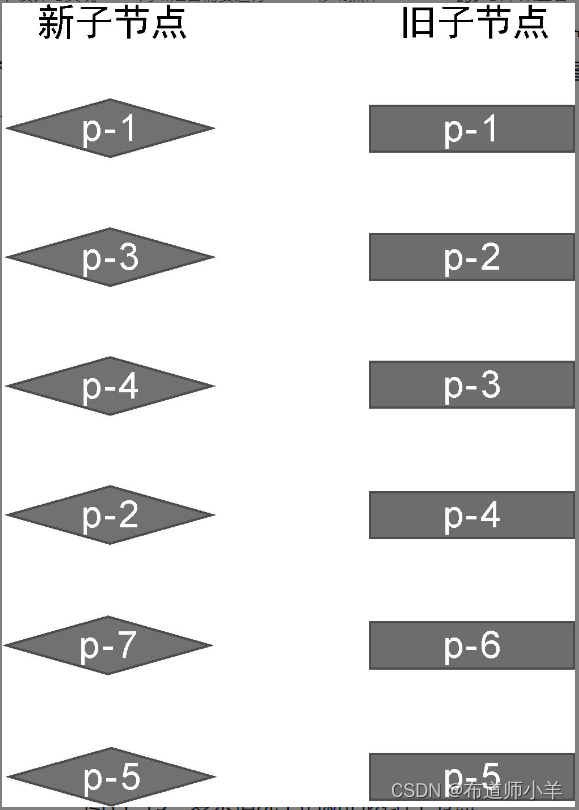
在这个例子中,新旧两组子节点的顺序如下:
- 旧的一组子节点:p-1、p-2、p-3、p-4、p-6、p-5。
- 新的一组子节点:p-1、p-3、p-4、p-2、p-7、p-5。
可以看到,与旧的一组子节点相比,新的一组子节点多出了一个新节点 p-7,少了一个节点 p-6。这个例子并不像上一节给出的例子那样理想化,我们无法简单地通过预处理过程完成更新。在这个例子中,相同的前置节点只有 p-1,而相同的后置节点只有 p-5,如下图所示:

下图给出了经过预处理后两组子节点的状态:
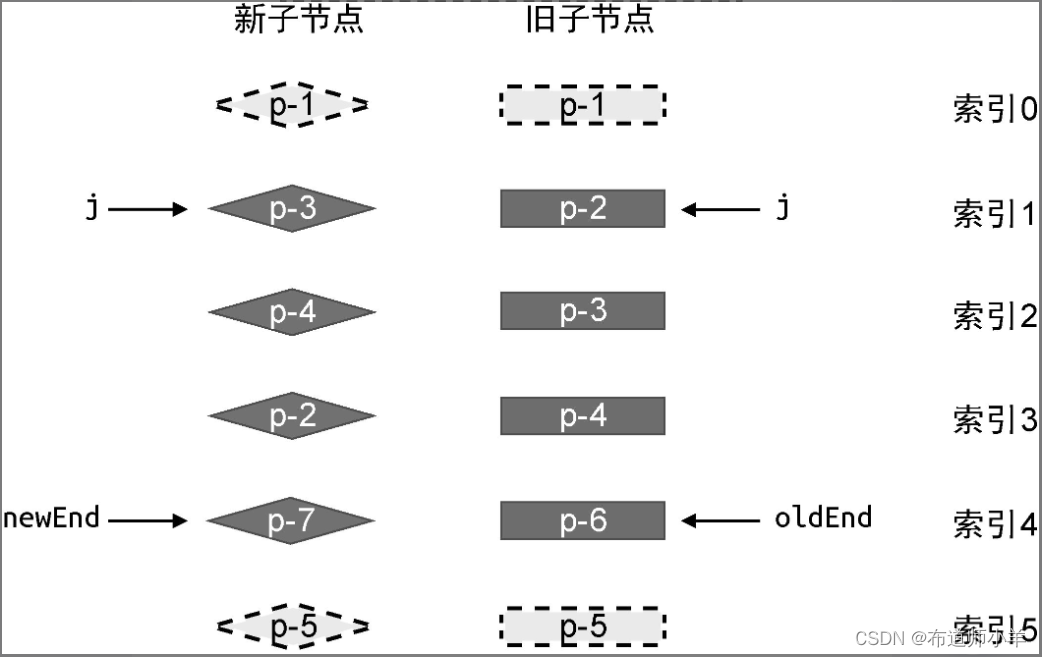
可以看到,经过预处理后,无论是新的一组子节点,还是旧的一组子节点,都有部分节点未经处理。这时就需要我们进一步处理。怎么处理呢?其实无论是简单 Diff 算法,还是双端 Diff 算法,抑或本章介绍的快速 Diff 算法,它们都遵循同样的处理规则:
- 判断是否有节点需要移动,以及应该如何移动;
- 找出那些需要被添加或移除的节点。
所以接下来我们的任务就是,判断哪些节点需要移动,以及应该如何移动。观察下图可知,在这种非理想的情况下,当相同的前置节点和后置节点被处理完毕后,索引 j、newEnd 和oldEnd 不满足下面两个条件中的任何一个:
- j > oldEnd && j <= newEnd
- j > newEnd && j <= oldEnd
因此,我们需要增加新的 else 分支来处理上图所示的情况,如下面的代码所示:
01 function patchKeyedChildren(n1, n2, container) {
02 const newChildren = n2.children
03 const oldChildren = n1.children
04 // 更新相同的前置节点
05 // 省略部分代码
06
07 // 更新相同的后置节点
08 // 省略部分代码
09
10 if (j > oldEnd && j <= newEnd) {
11 // 省略部分代码
12 } else if (j > newEnd && j <= oldEnd) {
13 // 省略部分代码
14 } else {
15 // 增加 else 分支来处理非理想情况
16 }
17
18 }
后续的处理逻辑将会编写在这个 else 分支内。知道了在哪里编写处理代码,接下来我们讲解具体的处理思路。首先,我们需要构造一个数组 source,它的长度等于新的一组子节点在经过预处理之后剩余未处理节点的数量,并且 source 中每个元素的初始值都是 -1,如下图所示:

我们可以通过下面的代码完成 source 数组的构造:
01 if (j > oldEnd && j <= newEnd) {
02 // 省略部分代码
03 } else if (j > newEnd && j <= oldEnd) {
04 // 省略部分代码
05 } else {
06 // 构造 source 数组
07 // 新的一组子节点中剩余未处理节点的数量
08 const count = newEnd - j + 1
09 const source = new Array(count)
10 source.fill(-1)
11 }
XXXXXXXXXXXXXXXXXXXXX
3、如何移动元素
4、总结
快速 Diff 算法在实测中性能最优。它借鉴了文本 Diff 中的预处理思路,先处理新旧两组子节点中相同的前置节点和相同的后置节点。当前置节点和后置节点全部处理完毕后,如果无法简单地通过挂载新节点或者卸载已经不存在的节点来完成更新,则需要根据节点的索引关系,构造出一个最长递增子序列。最长递增子序列所指向的节点即为不需要移动的节点。
















 3268
3268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









