









文章目录
- 1、重要概念
- 2、Java的内存模型(JMM)
- 3、多线程协作同步控制
1、重要概念
现在,并行计算显然已经成为一门正式的学科。也许很多人(包括Linus在内)都觉得并行计算或者说并行算法是多么的奇葩。但现在我们也不得不承认,在某些领域,这些算法还是有用武之地的。既然说服务端编程还是需要大量并行计算的,而Java也主要占领着服务端市场,那么对Java并行计算的研究就显得非常必要。但我想在这里先介绍几个重要的相关概念。
1.1、同步(Synchronous)和异步(Asynchronous)
同步和异步通常用来形容一次方法调用。同步方法调用一旦开始,调用者必须等到方法调用返回后,才能继续后续的行为。异步方法调用更像一个消息传递,一旦开始,方法调用就会立即返回,调用者就可以继续后续的操作。而异步方法通常会在另外一个线程中“真实”地执行。整个过程,不会阻碍调用者的工作。下图显示了同步方法调用和异步方法调用的区别。
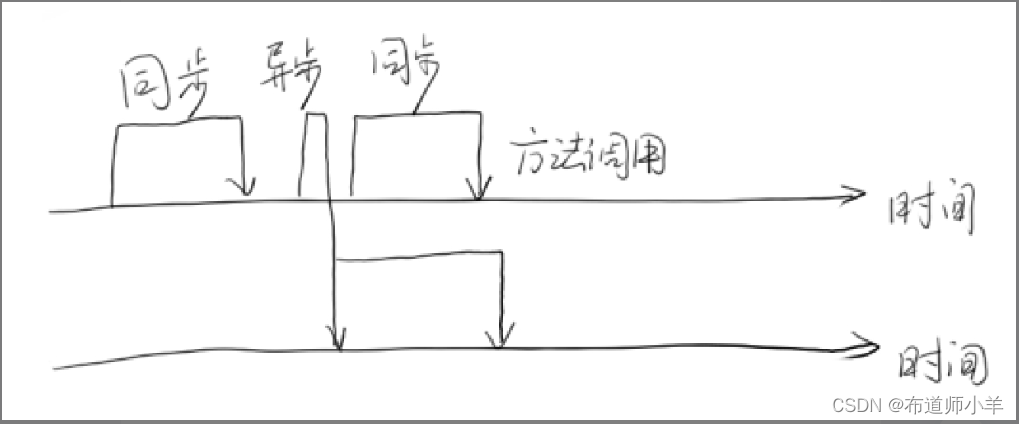
对于调用者来说,异步方法调用似乎是一瞬间就完成的。如果异步方法调用需要返回结果,那么当这个异步方法调用真实完成时,则会通知调用者。
1.2、并发(Concurrency)和并行(Parallelism)
并发和并行是两个非常容易被混淆的概念。它们都可以表示两个或者多个任务一起执行,但是侧重点有所不同。并发偏重于多个任务交替执行,而多个任务之间有可能还是串行的,而并行是真正意义上的“同时执行”,下图很好地诠释了这点。
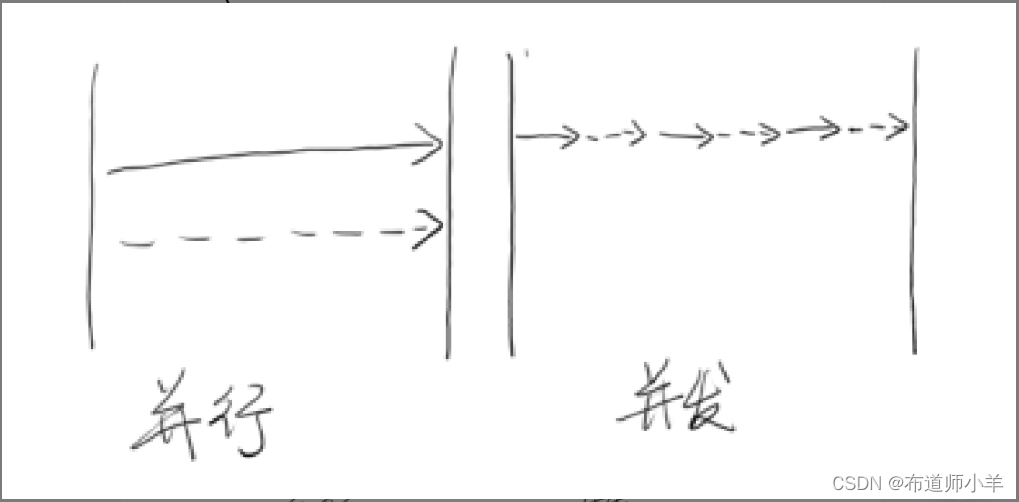
从严格意义上来说,并行的多个任务是真的同时执行,而对于并发来说,这个过程只是交替的,一会儿执行任务A,一会儿执行任务B,系统会不停地在两者之间切换。但对于外部观察者来说,即使多个任务之间是串行并发的,也会产生多任务并行执行的错觉。
实际上,如果系统内只有一个CPU,而使用多进程或者多线程任务,那么真实环境中这些任务不可能是真实并行的,毕竟一个CPU一次只能执行一条指令,在这种情况下多进程或者多线程就是并发的,而不是并行的(操作系统会不停地切换多个任务)。真实的并行也只可能出现在拥有多个CPU的系统中(比如多核CPU)。
1.3、临界区
临界区用来表示一种公共资源或者说共享数据,可以被多个线程使用。但是每一次只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源就必须等待。
比如,在一个办公室里有一台打印机,打印机一次只能执行一个任务。如果小王和小明同时需要打印文件,很显然,如果小王先下发了打印任务,打印机就开始打印小王的文件。小明的任务就只能等待小王打印结束后才能被执行。这里的打印机就是一个临界区的例子。
在并行程序中,临界区资源是保护的对象,如果意外出现打印机同时执行两个打印任务的情况,那么最可能的结果就是打印出来的文件是损坏的文件。它既不是小王想要的,也不是小明想要的。
1.4、阻塞(Blocking)和非阻塞(Non-Blocking)
阻塞和非阻塞通常用来形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其他所有需要这个资源的线程就必须在这个临界区中等待。等待会导致线程挂起,这种情况就是阻塞。此时,如果占用资源的线程一直不愿意释放资源,那么其他所有阻塞在这个临界区上的线程都不能工作。
非阻塞的意思与之相反,它强调没有一个线程可以妨碍其他线程执行,所有的线程都会尝试不断向前执行。
1.5、死锁(Deadlock)、饥饿(Starvation)和活锁(Livelock)
死锁、饥饿和活锁都属于多线程的活跃性问题。如果发现上述几种情况,那么相关线程可能就不再活跃,也就是说它可能很难再继续往下执行了。
死锁应该是最糟糕的一种情况了(当然,其他几种情况也好不到哪里去),下图显示了死锁的发生:
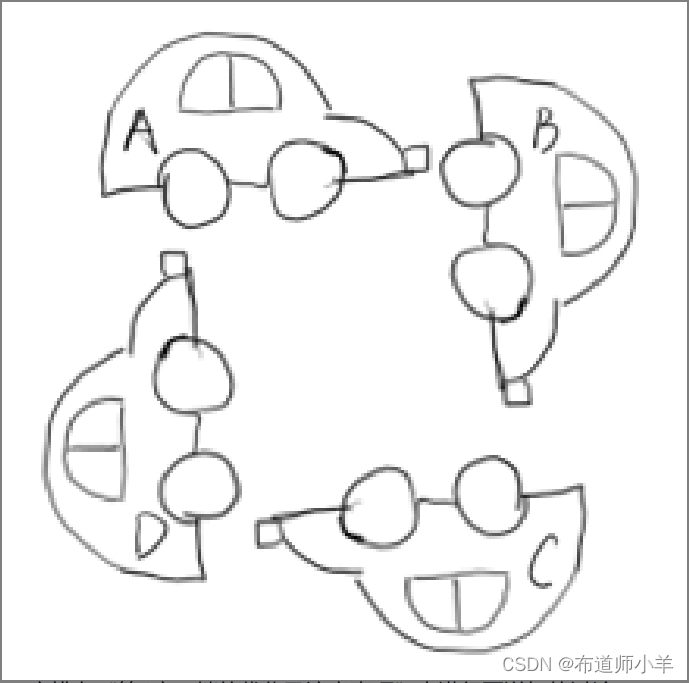
A、B、C、D四辆小车在这种情况下都无法继续行驶了,它们彼此之间占用了其他车辆的车道,如果大家都不愿意释放自己的车道,那么这个状态将永远持续下去,谁都不可能通过。死锁是一个很严重的并且应该避免和时时小心的问题。
饥饿是指某一个或者多个线程因为种种原因无法获得所需要的资源,导致一直无法执行。比如,它的线程优先级可能太低,而高优先级的线程不断抢占它需要的资源,导致低优先级线程无法工作。在自然界中,母鸟给雏鸟喂食时很容易出现这种情况。由于雏鸟很多,食物有限,雏鸟之间的食物竞争可能非常厉害,经常抢不到食物的雏鸟有可能会被饿死。线程的饥饿与这种情况非常类似。此外,某一个线程一直占着关键资源不放,导致其他需要这个资源的线程无法正常执行,这种情况也是饥饿的一种。与死锁相比,饥饿还是有可能在未来一段时间内解决的(比如,高优先级的线程已经完成任务,不再疯狂执行)。
活锁是一种非常有趣的情况。不知道大家是否遇到过这么一种场景,当你要坐电梯下楼时,电梯到了,门开了,这时你正准备出去,但很不巧的是,门外一个人挡着你的去路,他想进来。于是,你很礼貌地靠左走,避让对方。同时,对方也非常礼貌地靠右走,希望避让你。结果,你们俩就又撞上了。于是乎,你们都意识到了问题,希望尽快避让对方,你立即向右边走,同时,他立即向左边走。结果,又撞上了!不过介于人类的智力,我相信这个动作重复两三次后,你应该可以顺利解决这个问题。因为这时候,大家都会本能地对视,进行交流,保证这种情况不再发生。
但如果这种情况发生在两个线程之间可能就不会那么幸运了。如果线程的智力不够,且都秉承着“谦让”的原则,主动将资源释放给他人使用,那么就会导致资源不断地在两个线程间跳动,从而没有一个线程可以同时拿到所有资源。这种情况就是活锁。
1.6、并发级别
由于临界区的存在,多线程之间的并发必须受到控制。根据控制并发的策略,我们可以把并发的级别分为阻塞、无饥饿、无障碍、无锁、无等待等。
1.6.1、阻塞
一个线程是阻塞的,那么在其他线程释放资源之前,当前线程无法继续执行。当我们使用synchronized关键字或者重入锁时,我们得到的就是阻塞线程。
synchronized关键字和重入锁都试图在执行后续代码前,得到临界区的锁,如果得不到,线程就会被挂起,直到占有了所需资源为止。
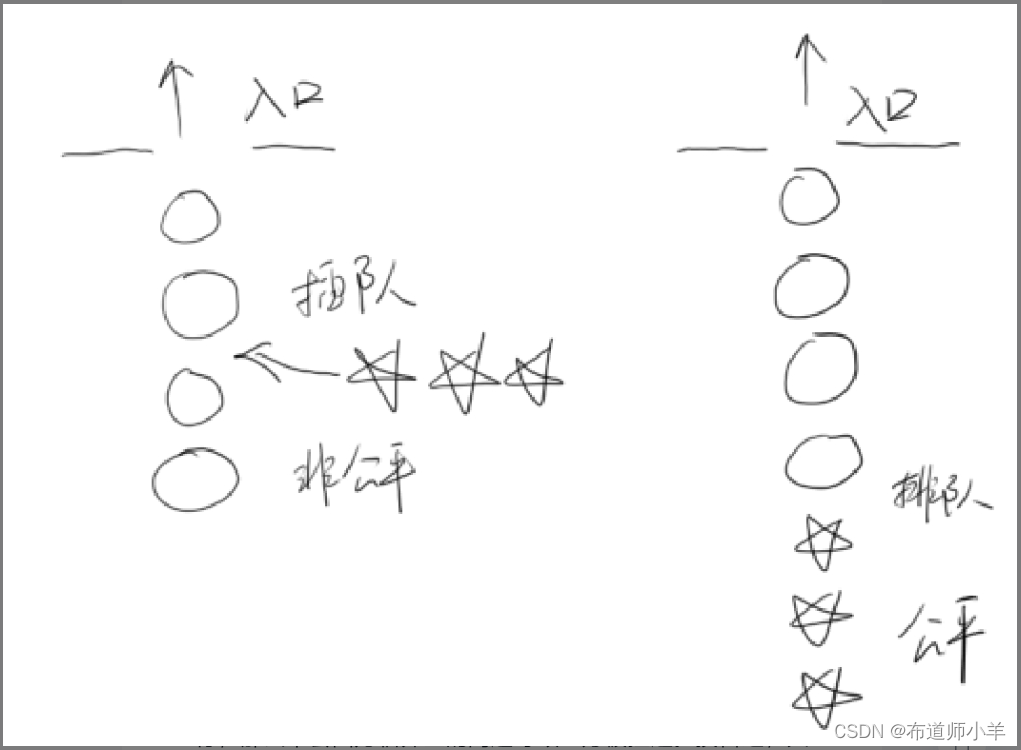
1.6.2、无饥饿(Starvation-Free)
如果线程之间是有优先级的,那么线程调度的时候总是会倾向于先满足高优先级的线程。也就说是,系统对于同一个资源的分配是不公平的!下图显示了非公平锁与公平锁两种情况(五角星表示高优先级线程):
1.6.3、无障碍(Obstruction-Free)
无障碍是一种最弱的非阻塞调度。两个线程如果无障碍地执行,那么不会因为临界区的问题导致一方被挂起。换言之,大家都可以大摇大摆地进入临界区。那么大家一起修改共享数据,把数据改坏了怎么办呢?对于无障碍的线程来说,一旦检测到这种情况,它就会立即对自己所做的修改进行回滚,以确保数据安全。但如果没有数据竞争发生,那么线程就可以顺利地完成自己的工作,走出临界区。
如果说阻塞的控制方式是悲观策略(系统认为两个线程之间很有可能发生不幸的冲突,因此以保护共享数据为第一优先级),相对来说,非阻塞的调度就是一种乐观的策略。它认为多个线程之间很有可能不会发生冲突,或者说发生冲突的概率不大。因此大家都应该无障碍地执行,但是一旦检测到冲突,就应该回滚。
从这个策略中也可以看到,无障碍的多线程程序并不一定能顺畅执行。因为当临界区中存在严重的冲突时,所有的线程可能都会不断地回滚自己的操作,而没有一个线程可以走出临界区。这种情况会影响系统的正常运行。所以,我们可能会非常希望在一堆线程中,至少有一个线程能够在有限的时间内完成自己的操作,从而退出临界区。至少这样可以保证系统不会在临界区中进行无限的等待。
一种可行的无障碍实现可以依赖一个“一致性标记”来实现。在操作之前,线程先读取并保存这个标记,在操作完成后,再次读取这个标记,检查这个标记是否被更改过。如果两者是一致的,则说明资源访问没有冲突。如果不一致,则说明可能在操作过程中与其他线程冲突,需要重试操作。任何对资源有修改操作的线程,在修改数据前,都需要更新这个“一致性标记”,表示数据不再安全。
1.6.4、无锁(Lock-Free)
无锁的并行都是无障碍的。在无锁的情况下,所有的线程都能尝试对临界区进行访问,不同的是,无锁的并发必然有一个线程能够在有限步内完成操作并离开临界区。
在无锁的调用中,一个典型的特点是它可能会包含一个无穷循环。在这个循环中,线程会不断尝试修改共享变量。如果没有冲突,修改成功,那么程序退出,否则线程会继续尝试修改。但无论如何,无锁的并行总能保证有一个线程是可以胜出的,不至于全军覆没。至于临界区中竞争失败的线程,它们必须不断重试,直到自己获胜。如果运气很不好,总是尝试不成功,则会出现类似饥饿的现象,线程会停止。
下面就是一段无锁的示意代码,如果修改不成功,那么循环永远不会停止:

1.6.5、无等待(Wait-Free)
无锁只要求有一个线程可以在有限步内完成操作,而无等待则在无锁的基础上更进一步扩展,它要求所有的线程都必须在有限步内完成,这样就不会引起饥饿问题。如果限制这个步骤的上限,还可以进一步分解为有界无等待和与线程数无关的无等待等,它们之间的区别只是对循环次数的限制不同。
一种典型的无等待结构就是RCU(Read Copy Update)。它的基本思想是,对数据的读可以不加控制,因此所有的读线程都是无等待的,它们既不会被锁定等待也不会引起任何冲突。但在写数据的时候,先取得原始数据的副本,接着只修改副本数据(这就是为什么读可以不加控制),修改完成后,在合适的时机回写数据。
1.7、线程的基本操作
1.7.1、新建线程
新建线程很简单。只要使用new关键字创建一个线程对象,并且将它“start()”起来即可:

那么线程“start()”后,会干什么呢?这才是问题的关键。线程Thread中有一个run()方法,start()方法会新建一个线程并让这个线程执行run()方法。
注意:不要用run()方法来开启新线程,它只会在当前线程中串行执行run()方法中的代码。
Thread类有一个非常重要的构造方法:

它传入一个Runnable接口的实例,在调用start()方法时,新的线程就会执行Runnable.run()方法。实际上,默认的Thread.run()方法就是这么做的:

注意:默认的Thread.run()方法就是直接调用内部的Runnable接口。因此,使用Runnable接口告诉线程该做什么更为合理。

上述代码实现了Runnable接口,并将该实例传入线程Thread中。这样避免了重写Thread.run()方法,单纯使用接口来定义线程Thread也是最常用的做法。
1.7.2、终止线程
一般来说,线程执行完毕就会关闭,无须手动关闭。但是,凡事都有例外。一些服务端的后台线程可能会常驻系统,它们通常不会正常终止。比如,它们的执行体本身就是一个大大的无穷循环,用于提供某些服务。
那么如何正常地终止一个线程呢?查阅JDK,你不难发现线程Thread提供了一个stop()方法。如果你使用stop()方法,就可以立即将一个线程终止,非常方便。但如果你使用Eclipse之类的IDE写代码,就会发现stop()方法是一个被标注为废弃的方法。也就是说,将来JDK可能会移除该方法。
为什么stop()方法被废弃而不推荐使用呢?原因是stop()方法过于暴力,强行把执行到一半的线程终止,可能会引起一些数据不一致的问题。
stop()方法在结束线程时,会直接终止线程,并立即释放这个线程所持有的锁,而这些锁恰恰是用来维持对象一致性的。如果此时,写线程正写到一半,强行终止线程对象就会被写坏。同时,由于锁已经被释放,另外一个等待该锁的读线程就顺理成章地读到了这个被写坏的对象,悲剧也就此发生。整个过程如下图所示:

如果需要终止一个线程,那么应该怎么做呢?其实方法很简单,只需要由我们自行决定线程何时退出就可以了。
1.7.3、线程中断
在Java中,线程中断是一种重要的线程协作机制。从表面上理解,中断就是让目标线程停止执行的意思,实际上并非完全如此。在上一节中,我们已经详细讨论了使用stop()方法终止线程的坏处,并且使用了一套自有的机制完善线程终止的功能。JDK中是否会提供更强大的支持呢?答案是肯定的,那就是线程中断。
严格地讲,线程中断并不会使线程立即关闭,而是给线程发送一个通知,告知目标线程,有人希望你关闭啦!至于目标线程接到通知后如何处理,则完全由目标线程自行决定。这点很重要,如果中断后,线程立即无条件关闭,我们就会又遇到stop()方法的老问题。有三个方法与线程中断有关,这三个方法看起来很像,可能会发生误用,希望大家注意:

Thread.interrupt()方法是一个实例方法。它通知目标线程中断,也就是设置中断标志位。中断标志位表示当前线程已经被中断了。Thread.isInterrupted()方法也是实例方法,它判断当前线程是否被中断(通过检查中断标志位)。最后的静态方法Thread.interrupted()也可用来判断当前线程的中断状态,但同时会清除当前线程的中断状态。
1.7.4、等待(wait)和通知(notify)
为了支持多线程之间的协作,JDK提供了两个非常重要的接口线程:等待方法wait()和通知方法notify()。这两个方法并不在Thread类中,而在输出的Object类中。这也意味着任何对象都可以调用这两个方法。
这两个方法的签名如下:

1.7.5、挂起(suspend)和继续执行(resume)线程
如果你阅读JDK有关Thread类的API文档,可能还会发现两个看起来非常有用的接口,即线程挂起(suspend)和继续执行(resume)。这两个操作是一对相反的操作,被挂起的线程,必须要等到执行resume()方法后,才能继续执行。乍看,这对操作就像stop()方法一样好用。但如果你仔细阅读说明文档,会发现它们也早已被标注为废弃方法,并不推荐使用。
不推荐使用suspend()方法挂起线程是因为suspend()方法在暂停线程的同时,并不会释放任何锁资源。此时,其他任何线程想要访问被它占用的锁,都会被牵连,导致无法正常继续运行(如下图所示):

1.7.6、等待线程结束(join)和谦让(yield)
在很多情况下,线程之间的协作和人与人之间的协作非常类似。一种常见的合作方式就是分工合作。以我们非常熟悉的软件开发为例,在一个项目中,总是应该有几位号称“需求分析师”的同事,先对系统的需求和功能点进行整理和总结,以书面形式给出一份需求说明或者类似的参考文档,然后,软件设计师、研发工程师才会一拥而上,进行软件开发。如果缺少需求分析师的工作输出,那么软件研发的难度可能会比较大。因此,作为一名软件研发人员,总是喜欢等待需求分析师完成他应该完成的任务后才投身工作。简单地说,就是软件研发人员需要等待需求分析师完成他的工作后才能进行研发。
将这个关系对应到多线程应用中,很多时候,一个线程的输入可能非常依赖于另外一个或者多个线程的输出,此时,这个线程就需要等待依赖线程执行完毕,才能继续执行。JDK提供了join()方法来实现这个功能。join()方法如下所示:

第一个join()方法表示无限等待,它会一直阻塞当前线程,直到目标线程执行完毕。第二个join()方法给出了一个最大等待时间,如果超过给定时间,目标线程还在执行,则当前线程也会因为“等不及了”而继续往下执行。
join通常是加入的意思,这个意思用在这里也非常贴切。因为一个线程要加入另外一个线程,最好的方法就是等着它一起走。
2、Java的内存模型(JMM)
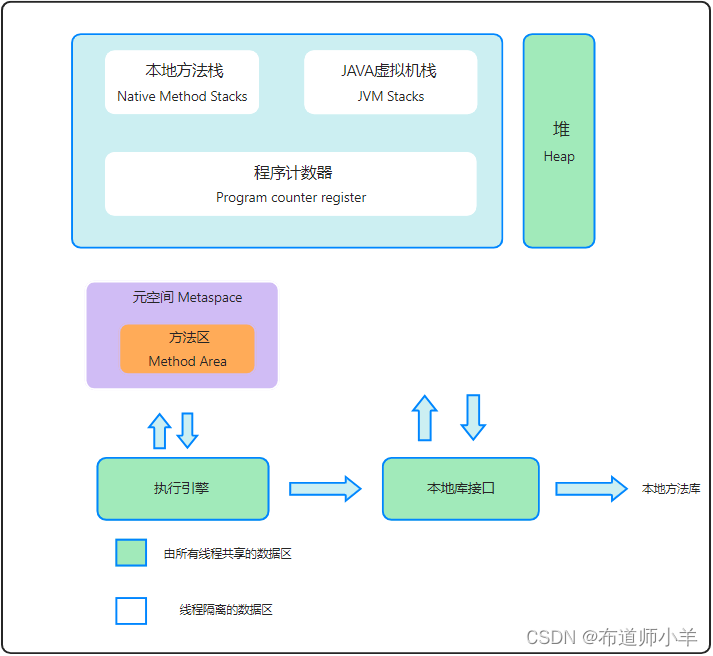
由于并行程序要比串行程序复杂很多,其中一个重要原因是并行程序中数据访问的一致性和安全性将会受到严重挑战。如何保证一个线程可以看到正确的数据呢?这个问题看起来很白痴,但对于串行程序来说,根本就是小菜一碟。如果你读取一个变量,这个变量的值是1,那么你读到的一定是1,就是这么简单的问题在并行程序中居然变得复杂起来。事实上,如果不加控制地任由线程胡乱并行,即使原本是1的数值,你也有可能读到2。因此,我们需要在深入了解并行机制的前提下,再定义一种规则,保证多个线程可以有效地、正确地协同工作。而JMM也就是为此而生的。
JMM的关键技术点都是围绕着多线程的原子性、可见性和有序性来建立的。因此,我们首先必须了解这些概念。
2.1、原子性(Atomicity)
原子性是指一个操作是不可中断的。即使在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
比如,对于一个静态全局变量int i,两个线程同时对它赋值,线程A给它赋值为1,线程B给它赋值为-1。那么不管这两个线程以何种方式、何种步调工作,i的值要么是1,要么是-1。线程A和线程B之间是没有干扰的。这就是原子性的一个特点——不可被中断。
但如果我们不使用int型数据而使用long型数据,可能就没有那么幸运了。对于32位系统来说,long型数据的读写不是原子性的(因为long型数据有64位)。也就是说,如果两个线程同时对long型数据进行写入(或者读取),则线程之间是有干扰的。
2.2、可见性(Visibility)
可见性是指当一个线程修改了某个共享变量的值时,其他线程是否能够立即知道这个修改。显然,对于串行程序来说,可见性问题是不存在的。因为你在任何一个操作步骤中修改了某个变量的值,在后续的步骤中读取这个变量的值时,读取的一定是修改后的新值。
但是这个问题存在于并行程序中。如果一个线程修改了某个全局变量的值,那么其他线程未必可以马上知道这个改动。下图展示了发生可见性问题的一种可能:

如果在CPU1和CPU2上各运行了一个线程,它们共享变量t,由于编译器优化或者硬件优化的缘故,在CPU1上的线程将变量t进行了优化,然后将其缓存在cache中或者寄存器里。在这种情况下,如果在CPU2上的某个线程修改了变量t的实际值,那么CPU1上的线程可能无法知道这个改动,依然会读取cache中或者寄存器里的数据。因此,就产生了可见性问题。外在表现为:变量t的值被修改,但是CPU1上的线程依然会读到一个旧值。可见性问题也是并行程序开发中需要重点关注的问题之一。
可见性问题是一个综合性问题。除上面提到的缓存优化或者硬件优化(有些内存读写可能不会立即触发,而会先进入一个硬件队列等待)会导致可见性问题,指令重排(这个问题将在下一节中详细讨论)及编辑器的优化,也有可能导致一个线程的修改不会立即被其他线程察觉。
下面来看一个简单的例子:

上述两个线程并行执行,分别有1、2、3、4四条指令。其中指令1、2属于线程1,而指令3、4属于线程2。
从指令的执行顺序上看,r22并且r11似乎是不可能出现的。但实际上,我们并没有办法从理论上保证这种情况不出现。因为编译器可能将指令重排成:

在这种执行顺序中,就有可能出现刚才看似不可能出现的r22并且r11的情况。
这个例子就说明,在一个线程中观察另外一个线程的变量,它们的值是否能观测到、何时能观测到是没有保证的。
再来看一个稍微复杂一些的例子:

这里假设在初始时,pq并且p.x0。对于大部分编译器来说,可能会对线程1进行向前替换的优化,也就是r5=r1.x这条指令会被直接替换成r5=r2。由于它们都读取了r1.x,又发生在同一个线程中,因此,编译器很可能认为第2次读取是完全没有必要的。因此,上述指令可能会变成:

现在思考这么一种场景。假设线程2中的r6.x=3发生在r2=r1.x和r4=r3.x之间,而编译器又打算重用r2来表示r5,那么就有可能出现非常奇怪的现象。你看到的r2是0,r4是3,但是r5还是0。因此,如果从线程1来看就是:p.x的值从0变成了3(因为r4是3),接着又变成了0(这是不是算一个非常怪异的问题呢?)。
2.3、有序性(Ordering)
有序性问题可能是三个问题中最难理解的了。对于一个线程的执行代码而言,我们总是习惯性地认为代码是从前往后依次执行的。这么理解也不能说完全错误,因为就一个线程内而言,确实会表现成这样。但是,在并行时,程序的执行可能就会出现乱序。给人的直观感觉就是:写在前面的代码,会在后面执行。听起来有些不可思议,是吗?出现有序性问题的原因是,程序在执行时可能会进行指令重排,重排后的指令与原指令的顺序未必一致。下面来看一个简单的例子:
public class OrderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1;
flag = true;
}
public void reader() {
if (flag) {
int i = a + 1;
......
}
}
}
假设线程A首先执行writer()方法,接着线程B执行reader()方法,如果发生指令重排,那么线程B在代码第10行时,不一定能看到a已经被赋值为1了,如下图所示:
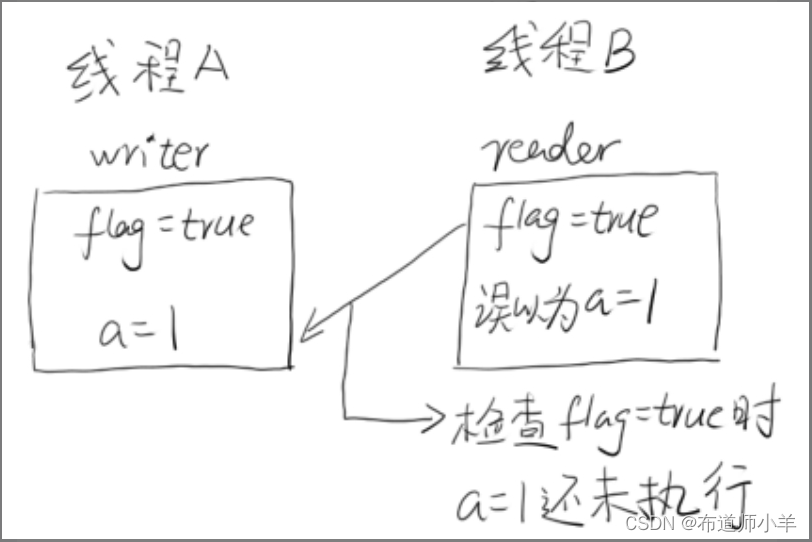
这确实是一个看起来很奇怪的问题,但是它确实可能存在。
注意: 这里说的是可能存在。因为如果指令没有重排,这个问题就不存在了,但是指令是否发生重排、如何重排,恐怕是我们无法预测的。因此,对于这类问题,我认为比较严谨的描述是:线程A的指令执行顺序在线程B看来是没有保证的。如果运气好的话,线程B也许真的可以看到和线程A一样的执行顺序。
不过这里还需要强调一点,对于一个线程来说,它看到的指令执行顺序一定是一致的(否则应用根本无法正常工作)。也就是说指令重排是有一个基本前提的,就是保证串行语义的一致性。指令重排不会使串行语义逻辑发生问题。因此,在串行代码中,大可不必担心。
注意:指令重排可以保证串行语义一致,但是没有义务保证多线程的语义也一致。
那么,好奇的你可能马上就会在脑海里闪出一个疑问——为什么要进行指令重排呢?一步一步执行多好呀,也不会有那么多奇葩的问题。
之所以那么做,完全是出于性能考虑。我们知道,一条指令的执行是可以分为很多步的。简单地说,可以分为以下几步:
- 取指IF。
- 译码和取寄存器操作数ID。
- 执行或者有效地址计算EX。
- 存储器访问MEM。
- 写回WB。
我们的汇编指令也不是一步就可以执行完毕的,在CPU中实际工作时,它是需要分为多个步骤依次执行的。当然,每个步骤所涉及的硬件也可能不同。比如,取指时会用到PC寄存器和存储器,译码时会用到指令寄存器组,执行时会使用ALU,写回时需要寄存器组。
注意:ALU指算术逻辑单元。它是CPU的执行单元,也是CPU的核心组成部分,主要功能是进行二进制算术运算。
由于每一个步骤都可能使用不同的硬件完成,因此,聪明的工程师们就发明了流水线技术来执行指令。下图显示了指令流水线的工作原理:

可以看到,当指令2执行时,指令1其实并未执行完,确切地说指令1还没开始执行,只是刚刚完成了取指操作而已。这样的好处非常明显,假如这里每一个步骤都需要花费1毫秒,那么指令2等待指令1完全执行后再执行,则需要等待5毫秒,而使用流水线后,指令2只需要等待1毫秒就可以执行了。如此大的性能提升,当然让人眼红。更何况,实际的商业CPU的流水线级别甚至可以达到10级以上,性能提升更加明显。
有了流水线,CPU才能真正高效地执行,但是,别忘了一点,流水线总是害怕被中断的。流水线满载时,性能确实相当不错,但是一旦被中断,所有的硬件设备都会进入一个停顿期,再次满载又需要几个周期,因此,性能损失会比较大。所以,我们必须要想办法尽量不让流水线被中断!
那么答案就来了,之所以需要做指令重排,就是为了尽量少地中断流水线。当然了,指令重排只是减少中断的一种技术,实际上,在CPU的设计中,我们还会使用更多的软硬件技术来防止中断。
让我们来仔细看一个例子。下图展示了A=B+C这个操作的执行过程:

写在左边的指令就是汇编指令。LW表示load,其中LW R1,B表示把B的值加载到R1寄存器中。ADD指令就是加法,例子中把R1、R2的值相加,并存放到R3中。SW表示store——存储,例子中就是将R3寄存器的值保存到变量A中。
右边就是流水线的情况。注意,在ADD指令上,有一个大叉,表示一个中断。也就是说ADD在这里停顿了一下。为什么ADD会在这里停顿呢?原因很简单,R2中的数据还没有准备好,所以,ADD操作必须等待。由于ADD的延迟,导致其后所有的指令都要慢一拍。
理解了上面这个例子,我们就可以来看一下更加复杂的情况:
a=b+c
d=e-f
上述代码的执行过程如下图所示:

由于ADD和SUB都需要等待上一条指令的结果,因此,在这里插入了不少停顿。那么对于这段代码,是否有可能消除这些停顿呢?显然是可以的,如下图所示:

显示了指令重排消除停顿的方法。我们只需要将LW Re, e和LW Rf, f移动到前面执行即可。思路很简单,先加载e和f对程序是没有影响的。既然在ADD的时候一定要停顿一下,那么停顿的时间还不如去做点有意义的事情。
重排后的指令如下图所示。可以看到,所有的停顿都已经消除,流水线已经顺畅了:

由此可见,指令重排对于提高CPU性能是十分必要的。虽然确实带来了乱序的问题,但是这点牺牲是完全值得的。
2.4、哪些指令不能重排:Happen-Before规则
前文已经介绍了指令重排,虽然Java虚拟机和执行系统会对指令进行一定的重排,但是指令重排是有原则的,并非所有的指令都可以随便改变执行位置。以下罗列了一些基本原则,这些原则是指令重排不可违背的:
- 程序顺序原则:在一个线程内保证语义的串行性。
- volatile规则:volatile变量的写先于读发生,这保证了volatile变量的可见性。
- 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前。
- 传递性:A先于B, B先于C,那么A必然先于C。
- 线程的start()方法先于它的每一个动作。
- 线程的所有操作先于线程的终结(Thread.join())。
- 线程的中断(interrupt())先于被中断线程的代码。
- 对象的构造函数的执行、结束先于finalize()方法。
以程序顺序原则为例,重排后的指令绝对不能改变原有的串行语义,比如:
a=1;
b=a+1;
由于第二条语句依赖第一条语句的执行结果。如果贸然交换两条语句的执行顺序,那么程序的语义就会改变。因此这种情况是绝对不允许发生的,这也是指令重排的一条基本原则。
此外,锁规则强调,unlock操作必然发生在后续的对同一个锁的lock之前。也就是说,如果对一个锁解锁后再加锁,那么加锁的动作绝对不能重排到解锁的动作之前。很显然,如果这么做,则加锁行为是无法获得这把锁的。
其他几条原则也是类似的,这些原则都是为了保证指令重排不会破坏原有的语义。
2.5、volatile与Java内存模型(JMM)
Java内存模型都是围绕着原子性、有序性和可见性展开的。为了在适当的场合,确保线程的有序性、可见性和原子性,Java使用了一些特殊的操作或者关键字来声明、告诉虚拟机。这里要尤其注意,不能随意变动优化目标指令。关键字volatile就是其中之一。
如果你在英文字典中查阅volatile的解释,你会看到最常用的解释是“易变的、不稳定的”。这也正是关键字volatile的语义。
当你用关键字volatile声明一个变量时,就等于告诉虚拟机,这个变量极有可能会被某些程序或者线程修改。为了确保这个变量被修改后,应用程序范围内的所有线程都能够“看到”这个改动,虚拟机就必须采用一些特殊的手段,保证这个变量的可见性等特点。
比如,根据编译器的优化规则,如果不使用关键字volatile声明变量,那么这个变量被修改后,其他线程可能并不会知道,甚至在别的线程中,看到变量的修改顺序都会是反的。一旦使用关键字volatile,虚拟机就会特别小心地处理这种情况。
关键字volatile对于保证操作的原子性是有非常大的帮助的。但是需要注意的是,关键字volatile并不能代替锁,它也无法保证一些复合操作的原子性。比如下面的例子,通过关键字volatile无法保证i++的原子性:
/**
* @title TestVolatile
* @description
* @author: yangyongbing
* @date: 2024/2/7 11:32
*/
public class TestVolatile {
static volatile int i = 0;
public static class PlusTask implements Runnable {
@Override
public void run() {
for (int k = 0; k < 1000; k++) {
// 保证不了原子性
i++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[10];
for(int i=0;i<10;i++){
threads[i] = new Thread(new PlusTask());
threads[i].start();
}
for (int j = 0; j < 10; j++) {
threads[j].join();
}
System.out.println(i);
}
}
执行上述代码,如果i++是原子性的,那么最终的值应该是100000(10个线程各累加10000次)。但实际上,上述代码的输出总是会小于100000。
此外,关键字volatile也能保证数据的可见性和有序性。下面再来看一个简单的例子:

上述代码中,ReaderThread线程只有在数据准备好时(ready为true),才会打印number的值。它通过ready变量判断是否应该打印。在主线程中,开启ReaderThread后,就为number和ready赋值,并期望ReaderThread能够看到这些变化并将数据输出。
执行这个程序时,由于系统优化的结果,ReaderThread线程无法“看到”主线程中的修改,导致ReaderThread永远无法退出(因为代码第7行中的判断条件永远不会成立),这显然不是我们想看到的结果。这个问题就是一个典型的可见性问题。
注意:在一些陈旧的JDK版本中,可以使用-client参数让虚拟机运行在客户端模式下,在这种情况下,虚拟机不会进行太多的优化,因此还是可以发现ready的值发生了变化。但无论如何,我们不能期待在一个线程中可以看到另外一个线程对一个变量的修改,除非对这个变量进行同步或者使用volatile关键字修饰。
和原子性问题一样,我们只要简单地使用关键字volatile来声明ready变量,告诉Java虚拟机“这个变量可能会在不同的线程中被修改”,就可以顺利地解决这个问题了。
3、多线程协作同步控制
同步控制是并发程序必不可少的。关键字synchronized就是一种最简单的控制方法,它决定了一个线程是否可以访问临界区资源。同时,Object.wait()方法和Object.notify()方法起到了让线程等待和通知的作用。这些工具对于实现复杂的多线程协作起到了重要的作用。
3.1、关键字synchronized
并行程序开发的一大重点就是线程安全。一般来说,程序并行化是为了获得更高的执行效率,但前提是,高效率不能以牺牲正确性为代价。如果程序并行化后,连基本的执行结果的正确性都无法保证,那么并行化本身也就没有任何意义了。因此,线程安全就是并行程序的根基。volatile关键字并不能真正保证线程安全,它只能确保一个线程修改了数据后,其他线程能够看到这个改动。但当两个线程同时修改某一个数据时,依然会产生冲突。
下面的代码演示了一个计数器,两个线程同时对i进行累加操作:
/**
* @title AccountingVol
* @description 无锁
* @author: yangyongbing
* @date: 2024/2/7 12:14
*/
public class AccountingVol implements Runnable{
static AccountingVol instance=new AccountingVol();
static volatile int i=0;
public static void increase(){
i++;
}
@Override
public void run() {
for (int j = 0; j < 10000000; j++) {
increase();
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
各执行10000000次。我们期望的执行结果当然是最终i的值可以达到20000000,但事实并非总是如此。如果你多执行几次代码就会发现,在很多时候,i的最终值会小于20000000。
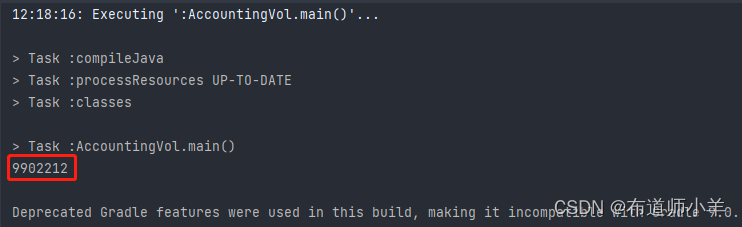
这是因为两个线程同时对i进行写入时,其中一个线程的结果会覆盖另外一个线程的结果(虽然这个时候i被声明为volatile变量)。
下图展示了这种可能的冲突,这就是多线程不安全的恶果。线程1和线程2同时读取i,并各自计算得到i=1,先后写入这个结果,因此,虽然i++被执行了两次,但是实际i的值只增加了1。

要从根本上解决这个问题,我们就必须保证多个线程在对i进行操作时做到完全同步。也就是说,当线程A在写入时,线程B不仅不能写,还不能读。因为在线程A写完之前,线程B读取的一定是一个过期数据。Java提供了一个重要的关键字synchronized来实现这个功能。
关键字synchronized的作用是实现线程的同步。它的工作是对同步的代码加锁,使得每一次只能有一个线程进入同步块,从而保证线程的安全性。
关键字synchronized有多种用法,这里做一个简单的整理:
- 指定加锁对象:对给定对象加锁,进入同步代码前要获得给定对象的锁。
- 直接作用于实例方法:相当于对当前实例加锁,进入同步代码前要获得当前实例的锁。
- 直接作用于静态方法:相当于对当前类加锁,进入同步代码前要获得当前类的锁。
下述代码将关键字synchronized作用于一个给定对象instance,每次当线程进入被关键字synchronized包裹的代码段,就都会要求请求instance实例的锁。如果当前有其他线程正持有这把锁,那么新到的线程就必须等待。这样,就保证了每次只能有一个线程执行i++操作。
public class AccountingVol implements Runnable {
static AccountingVol instance = new AccountingVol();
static int i = 0;
@Override
public void run() {
for (int j = 0; j < 10000000; j++) {
// 对当前实例instance加锁
synchronized (instance) {
i++;
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}

当然,上述代码也可以写成如下形式,两者是等价的:
public class AccountingVol implements Runnable{
static AccountingVol instance=new AccountingVol();
static int i=0;
public synchronized void increase(){
i++;
}
@Override
public void run() {
for (int j = 0; j < 10000000; j++) {
increase();
}
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
在上述代码中,关键字synchronized作用于一个实例方法。这就是说在进入increase()方法前,线程必须获得当前对象实例的锁。在本例中就是instance对象。我不厌其烦地给出main函数的实现,是想强调 Thread t1 = new Thread(instance); Thread t2 = new Thread(instance);这两行代码,也就是Thread的创建方式。这里使用Runnable接口创建两个线程,并且这两个线程都指向同一个Runnable接口实例(instance对象),这样才能保证两个线程在工作时能够关注同一个对象锁,从而保证线程安全。
一种错误的同步方式如下:
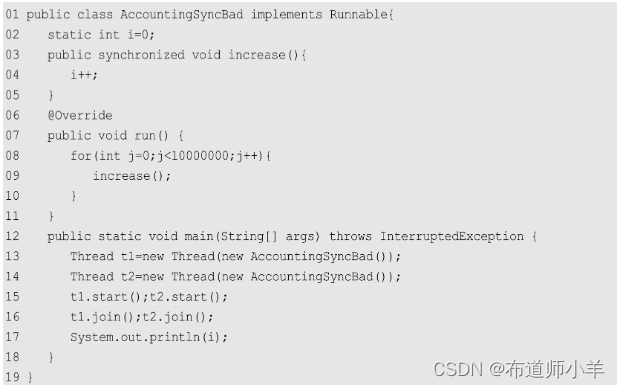
上述代码犯了一个严重的错误。虽然在第3行的increase()方法中声明了这是一个同步方法,但很不幸的是,执行这段代码的两个线程指向了不同的Runnable实例。由第13、14行代码可以看到,这两个线程的Runnable实例并不是同一个对象。因此,线程t1会在进入同步方法前加锁自己的Runnable实例,而线程t2也关注自己的对象锁。换言之,这两个线程使用的是两把不同的锁,因此线程安全无法保证。
我们只要简单地修改上述代码,就能使其正确执行,那就是使用关键字synchronized的第三种用法,将其作用于静态方法。将increase()方法修改如下:

这样,即使两个线程指向不同的Runnable对象,但由于方法需要请求的是当前类的锁,而非当前实例,因此,线程间还是可以正确同步。
除了用于线程同步、确保线程安全,关键字synchronized还可以保证线程间的可见性和有序性。就可见性而言,关键字synchronized可以完全替代关键字volatile的功能,只是使用上没有那么方便。就有序性而言,由于关键字synchronized限制每次只有一个线程可以访问同步块,因此,无论同步块内的代码如何被乱序执行,只要保证串行语义一致,那么执行结果总是一样的。而其他访问线程,又必须在获得锁后方能进入代码块读取数据,因此,它们看到的最终结果并不取决于代码的执行过程,有序性问题自然就得到了解决(换言之,被关键字synchronized限制的多个线程是串行执行的)。
3.2、可重入锁——ReentrantLock
重入锁可以完全替代关键字synchronized。在JDK 5.0之前的版本中,重入锁的性能远远优于关键字synchronized,但从JDK 6.0开始,JDK对关键字synchronized做了大量的优化,使得两者的性能差距并不大。
重入锁使用java.util.concurrent.locks.ReentrantLock类来实现。下面是一个最简单的重入锁使用案例:
import java.util.concurrent.locks.ReentrantLock;
/**
* @title Count
* @description
* @author: yangyongbing
* @date: 2024/2/18 9:51
*/
public class CountThread implements Runnable {
public static ReentrantLock lock = new ReentrantLock();
static int i=0;
@Override
public void run() {
for(int j=0;j<10000;j++){
lock.lock();
try {
i++;
}finally {
lock.unlock();
}
}
}
public static void main(String[] args) throws InterruptedException {
CountThread countThread = new CountThread();
Thread threadOne = new Thread(countThread);
Thread threadTwo = new Thread(countThread);
threadOne.start();
threadTwo.start();
threadOne.join();
threadTwo.join();
System.out.println(i);
}
}
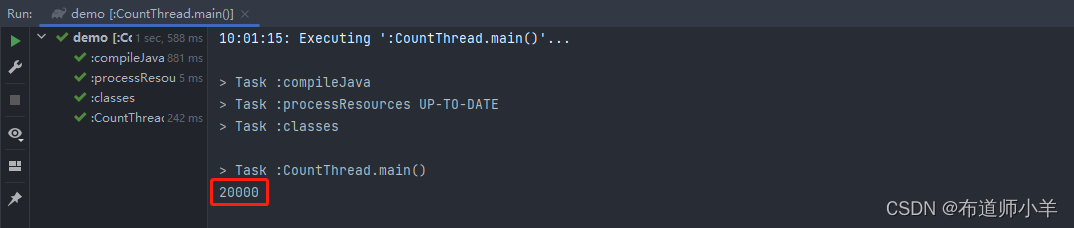
上述代码使用重入锁保护临界区资源i,确保多线程对i操作的安全性。从这段代码可以看到,与关键字synchronized相比,重入锁有着显式的操作过程。开发人员必须手动指定何时加锁,何时释放锁。也正因为这样,重入锁的逻辑控制灵活性要远远优于关键字synchronized。但值得注意的是,在退出临界区时,必须释放锁,否则,其他线程就没有机会再访问临界区了。
你可能会对重入锁的名字感到奇怪:锁前面为什么要加上“重入”两个字呢?从类的命名上看,Re-Entrant-Lock翻译成重入锁非常贴切。之所以这么叫,是因为这种锁可以反复进入。当然,这里的反复仅仅局限于一个线程。上述加锁的代码可以写成下面的形式:
for(int j=0;j<10000;j++){
lock.lock();
lock.lock();
try {
i++;
}finally {
lock.unlock();
lock.unlock();
}
}
在这种情况下,一个线程连续两次获得同一把锁是被允许的。如果不允许这么操作,那么同一个线程在第2次获得锁时,将会和自己产生死锁,程序就会“卡死”在第2次获得锁的过程中。但需要注意的是,如果同一个线程多次获得锁,那么也必须释放相同次数的锁。如果释放锁的次数多了,那么会得到一个java.lang.IllegalMonitorStateException异常,反之,如果释放锁的次数少了,那么相当于线程还持有这个锁,其他线程无法进入临界区。
除使用上的灵活性以外,重入锁还提供了一些高级功能。比如,重入锁可以提供中断处理的能力。
3.2.1、中断响应
对于关键字synchronized来说,如果一个线程在等待锁,那么结果只有两种情况,要么它获得这把锁继续执行,要么它继续等待。而使用重入锁,则提供了另一种可能,那就是线程可以被中断。也就是在等待锁的过程中,程序可以根据需要取消对锁的请求。有些时候,这么做是非常有必要的。比如,你和朋友约好一起去打球,如果你等了半个小时朋友还没有到,你突然接到一个电话,对方说由于突发情况不能如约前来了,那么你一定会扫兴地打道回府。中断正是提供了一套类似的机制。如果一个线程正在等待锁,那么它依然可以收到一个通知,被告知无须等待,可以停止工作。这种情况对于处理死锁是有一定帮助的。
下面的代码产生了一个死锁,但得益于锁中断,我们可以很轻易地处理这个死锁:
import java.util.concurrent.locks.ReentrantLock;
/**
* @title IntThread
* @description
* @author: yangyongbing
* @date: 2024/2/18 10:31
*/
public class IntThread implements Runnable {
public static ReentrantLock lockOne = new ReentrantLock();
public static ReentrantLock lockTwo = new ReentrantLock();
int i;
/**
* 控制加锁顺序,方便构造死锁
* @param i
*/
public IntThread(int i) {
this.i = i;
}
@Override
public void run() {
try {
if (i == 1) {
lockOne.lockInterruptibly();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
lockTwo.lockInterruptibly();
}
} else {
lockTwo.lockInterruptibly();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
lockOne.lockInterruptibly();
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 如果当前线程持有该锁,则为true,否则为false
if (lockOne.isHeldByCurrentThread()) {
lockOne.unlock();
}
if (lockTwo.isHeldByCurrentThread()) {
lockTwo.unlock();
}
System.out.println(Thread.currentThread().getId() + ":线程退出!");
}
}
public static void main(String[] args) throws InterruptedException {
IntThread intThreadOne = new IntThread(1);
IntThread intThreadTwo = new IntThread(2);
Thread threadOne = new Thread(intThreadOne);
Thread threadTwo = new Thread(intThreadTwo);
threadOne.start();
threadTwo.start();
Thread.sleep(1000);
// 中断其中一个线程
threadTwo.interrupt();
}
}
t1和t2线程启动后,t1线程先占用lock1,再请求lock2;t2线程先占用lock2,再请求lock1。因此,很容易形成t1和t2线程之间相互等待。在这里,对锁的请求,统一使用lockInterruptibly()方法。这是一个可以对中断进行响应的锁请求动作,即在等待锁的过程中,可以中断响应。
主线程main处于休眠状态,此时,两个线程处于死锁状态由于t2线程被中断,故t2线程会放弃对lock1的请求,同时释放已获得的lock2。这个操作导致t1线程可以顺利得到lock2而继续执行下去。
执行上述代码,将输出:
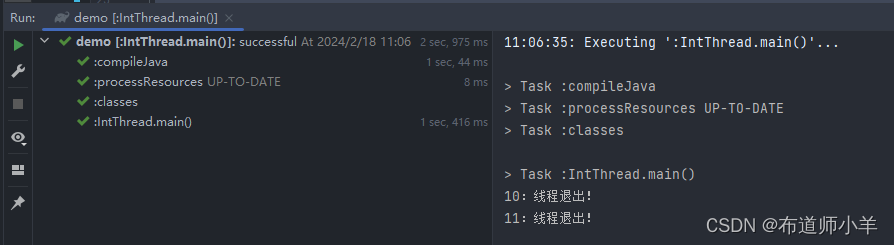
可以看到,中断后两个线程双双退出,但真正完成工作的只有t1线程,而t2线程则放弃了任务直接退出,释放资源。
3.2.2、限时等待
除了等待外部通知,要避免死锁还有另一种方法,那就是限时等待。依然以约朋友打球为例,如果朋友迟迟不来,又无法联系到他,那么在等待一两个小时后,我想大部分人都会扫兴离去。对线程来说也是这样。通常,我们无法判断为什么一个线程迟迟拿不到锁,也许是因为死锁,也许是因为产生了饥饿现象。如果给定一个等待时间,让线程自动放弃,那么对系统来说就是有意义的。我们可以使用tryLock()方法进行一次限时等待。
下面这段代码展示了限时等待锁的使用:
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
/**
* @title TimeLock
* @description
* @author: yangyongbing
* @date: 2024/2/18 11:30
*/
public class TimeLock implements Runnable {
public static ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
try {
if (lock.tryLock(5, TimeUnit.SECONDS)) {
Thread.sleep(60000);
} else {
System.out.println("get lock failed");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
public static void main(String[] args) {
TimeLock timeLock = new TimeLock();
Thread threadOne = new Thread(timeLock);
Thread threadTwo = new Thread(timeLock);
threadOne.start();
threadTwo.start();
}
}
在这里,tryLock()方法接收两个参数,一个表示等待时长,另一个表示计时单位。这里将计时单位设置为秒,时长为5,表示线程在这个锁请求中最多等待5秒。如果超过5秒还没有得到锁,就会返回false;如果成功获得锁,就会返回true。
在本例中,由于占用锁的线程会持有锁长达6秒,故另一个线程无法在5秒的等待时间内获得锁,因此请求锁会失败。
ReentrantLock.tryLock()方法也可以不带参数直接运行。在这种情况下,当前线程会尝试获得锁。如果锁并未被其他线程占用,则获得锁成功,并立即返回true。如果锁被其他线程占用,则当前线程不会等待,而是立即返回false。这时不会出现线程等待,因此也不会产生死锁。
3.2.3、公平锁
在大多数情况下,锁的请求都是非公平的。也就是说,线程1首先请求了锁A,接着线程2也请求了锁A。那么当锁A可用时,线程1可以获得锁还是线程2可以获得锁呢?答案是不一定,系统只会从这个锁的等待队列中随机挑选一个,因此不能保证公平性。这就好比买票不排队,大家都围在售票窗口前,售票员忙得焦头烂额,也顾不上谁先谁后,随便找个人出票就完事了。而公平的锁则不是这样的,它会按照时间的先后顺序保证先到者先得,后到者后得。公平锁的一大特点是,它不会产生饥饿现象。只要你排队,最终都可以等到资源。如果我们使用synchronized关键字进行锁控制,那么产生的锁就是非公平的。重入锁允许我们设置其公平性,它的构造函数如下:
/**
* Creates an instance of {@code ReentrantLock} with the
* given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
当参数fair为true时,表示锁是公平的。公平锁看起来很优美,但是要实现公平锁必然要求系统维护一个有序队列,因此公平锁的实现成本比较高,性能却非常低下。因此,在默认情况下,锁是非公平的。如果没有特别的需求,则不需要使用公平锁。公平锁和非公平锁在线程调度表现上也是非常不一样的。下面的代码可以很好地突出公平锁的特点:
import java.util.concurrent.locks.ReentrantLock;
/**
* @title FairLock
* @description 公平锁
* @author: yangyongbing
* @date: 2024/2/18 11:52
*/
public class FairLock implements Runnable {
public static ReentrantLock fairLock = new ReentrantLock(true);
@Override
public void run() {
while (true) {
try {
fairLock.lock();
System.out.println(Thread.currentThread().getName() + ":获得锁!");
} finally {
fairLock.unlock();
}
}
}
public static void main(String[] args) {
FairLock fairLock = new FairLock();
Thread threadOne = new Thread(fairLock, "ThreadOne");
Thread threadTwo = new Thread(fairLock, "threadTwo");
threadOne.start();
threadTwo.start();
}
}
指定锁是公平的。接着,由t1和t2两个线程分别请求这把锁,并且在得到锁后,进行控制台输出,表示自己得到了锁。在使用公平锁的情况下,得到的输出通常如下所示:

由于代码会产生大量输出,这里只截取部分进行说明。在这个输出中,可以看到,很明显两个线程基本上是交替获得锁的,几乎不会发生同一个线程连续多次获得锁的情况,从而保证了公平性。如果不使用公平锁,那么情况会完全不一样,下面是使用非公平锁时的部分输出:

可以看到,根据系统的调度,一个线程会倾向于再次获取已经持有的锁,这种分配方式是高效的,但是无公平性可言。
ReentrantLock的几个重要方法整理如下:
- lock():获得锁,如果锁已经被占用,则等待。
- lockInterruptibly():获得锁,但优先响应中断。
- tryLock():尝试获得锁,如果成功则返回true,如果失败则返回false。该方法不等待,立即返回。
- tryLock(long time, TimeUnit unit):在给定时间内尝试获得锁。
- unlock():释放锁。
就重入锁的实现来看,它主要集中在Java层面。在重入锁的实现中,主要包含3个要素:
- 第一,原子状态。原子状态使用CAS操作来存储当前锁的状态,判断锁是否已经被别的线程持有了。
- 第二,等待队列。所有没有请求到锁的线程,会进入等待队列等待。待有线程释放锁后,系统就能从等待队列中唤醒一个线程,继续工作。
- 第三,阻塞原语park()和unpark()。阻塞原语用来挂起和恢复线程。没有得到锁的线程将会被挂起。
3.3、重入锁的好搭档:Condition
如果大家理解了wait()方法和notify()方法,就能很容易地理解Condition对象。Condition对象与wait()方法和notify()方法的作用是大致相同的,但是wait()方法和notify()方法是与synchronized关键字配合使用的,而Condition对象是与重入锁相关联的。通过lock接口(重入锁就实现了这一个接口)的Condition.newCondition()方法可以生成一个与当前重入锁绑定的Condition实例。利用Condition对象,我们就可以让线程在合适的时间等待,或者在某一个特定的时间得到通知,继续执行。
Condition接口提供的基本方法如下:

以上方法的含义如下:
- await()方法会使当前线程等待,同时释放当前锁,当其他线程中使用signal()方法或者signalAll()方法时,线程会重新获得锁并继续执行。当线程被中断时,也能跳出等待。该方法和wait()方法相似。
- awaitUninterruptibly()方法与await()方法基本相同,但是它不会在等待过程中响应中断。
- signal()方法用于唤醒一个在等待中的线程,signalAll()方法会唤醒所有在等待中的线程。该方法和notify()方法相似。
下面的代码简单地演示了Condition的功能:
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/**
* @title ReentrantLockCondition
* @description
* @author: yangyongbing
* @date: 2024/2/18 12:25
*/
public class ReentrantLockCondition implements Runnable {
public static ReentrantLock lock = new ReentrantLock();
public static Condition condition = lock.newCondition();
@Override
public void run() {
try {
lock.lock();
System.out.println(Thread.currentThread().getName()+":已拿到锁!");
condition.await();
System.out.println("Thread is going go");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
ReentrantLockCondition reentrantLockCondition = new ReentrantLockCondition();
Thread threadOne = new Thread(reentrantLockCondition,"threadOne");
threadOne.start();
Thread.sleep(2000);
// main线程通知threadOne线程继续执行
lock.lock();
condition.signal();
lock.unlock();
}
}

第3行代码通过lock生成一个与之绑定的Condition对象。第8行代码要求线程在Condition对象上等待。第23行代码由主线程main发出通知,告知等待在Condition上的线程可以继续执行了。
与wait()方法和notify()方法一样,当线程使用Condition.await()方法时,要求线程持有相关的重入锁,在调用Condition.await()方法后,这个线程会释放这把锁。同理,在调用Condition.signal()方法时,也要求线程先获得相关的锁。在调用signal()方法后,系统会从当前Condition对象的等待队列中唤醒一个线程。一旦线程被唤醒,就会重新尝试获得与之绑定的重入锁,一旦成功获取,就可以继续执行了。因此,在调用signal()方法之后,一般需要释放相关的锁,让给被唤醒的线程,让它可以继续执行。比如,在本例中,第24行代码就释放了重入锁。如果省略第24行,那么,虽然已经唤醒了t1线程,但是由于它无法重新获得锁,因而也就无法真正地继续执行。
在JDK内部,重入锁和Condition对象被广泛使用,以ArrayBlockingQueue为例,它的put()方法实现如下(不同JDK版本实现略有差异,但总体实现类似):

同理,对应的take()方法实现如下:

3.4、允许多个线程同时访问:信号量(Semaphore)
在了解信号量之前,先来了解两个基本思想:基于许可的多线程控制,排他(exclusive)锁和共享(shared)锁。
3.4.1、基于许可的多线程控制
为了控制多个线程访问共享资源,我们需要为每个访问共享区间的线程派发一个许可,拿到许可的线程才能进入共享区间活动。当线程完成工作后,离开共享区间时,必须归还许可,以确保后续的线程可以正常取得许可。如果许可用完了,那么线程进入共享区间时,就必须等待。这就是控制多线程并行的基本思想。
打个比方,一大群孩子去游乐场玩摩天轮,摩天轮上只能坐20个孩子,但是却来了100个小孩,那么许可个数就是20。也就是说,一次只有20个小孩可以上摩天轮玩,其他的孩子必须排队等待。只有等摩天轮上的孩子离开位置时,其他小孩才能上去玩。使用许可控制线程行为和排队玩摩天轮差不多是一个意思。
3.4.2、排他锁和共享锁
第二个重要的概念是排他锁和共享锁。顾名思义,在排他模式下,只有一个线程可以访问共享变量,而在共享模式下,则允许多个线程同时访问共享变量。简单地说,重入锁是排他的,信号量是共享的。用摩天轮来打比方,排他锁就是虽然我这里有20个位置,但是小朋友也只能一个一个上。多出来的位置怎么办呢?可以空着,也可以让摩天轮上唯一的小孩换着坐,他想坐哪儿就坐哪儿,1分钟换一个位置也没有关系。而共享锁,就是正常的玩摩天轮的方式。
信号量正是基于以上两种思想的线程控制方法。它为多线程协作提供了更为强大的控制方法。从广义上说,信号量是对锁的扩展。无论是内部锁synchronized还是重入锁ReentrantLock,一次都只允许一个线程访问一个资源,而信号量却可以指定多个线程,同时访问某一个资源。信号量主要提供了以下构造函数:

在构造信号量对象时,必须指定信号量的准入数,即同时能申请多少个许可。当每个线程每次只申请一个许可时,就相当于指定了同时有多少个线程可以访问某一个资源。信号量的主要逻辑方法有:

acquire()方法尝试获得一个准入的许可。若无法获得,则线程会等待,直到有线程释放许可或者当前线程被中断。acquireUninterruptibly()方法和acquire()方法类似,但是不响应中断。tryAcquire()方法尝试获得一个许可,如果成功则返回true,如果失败则返回false,它不会等待,立即返回。release()方法用于在线程访问资源结束后释放许可,以使其他等待许可的线程可以获得许可并进行资源访问。
在JDK的官方Javadoc中,就有一个有关信号量使用的简单实例,有兴趣的可以自行翻阅,这里给出一个更加简单的例子:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* @title SemaphoreDemo
* @description 信号量
* @author: yangyongbing
* @date: 2024/2/18 13:15
*/
public class SemaphoreDemo implements Runnable{
final Semaphore semaphore=new Semaphore(5);
@Override
public void run() {
try {
semaphore.acquire();
Thread.sleep(2000);
System.out.println(Thread.currentThread().getId()+": done!");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
semaphore.release();
}
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(20);
final SemaphoreDemo semaphoreDemo = new SemaphoreDemo();
for (int i=0;i<20;i++){
executorService.submit(semaphoreDemo);
}
}
}
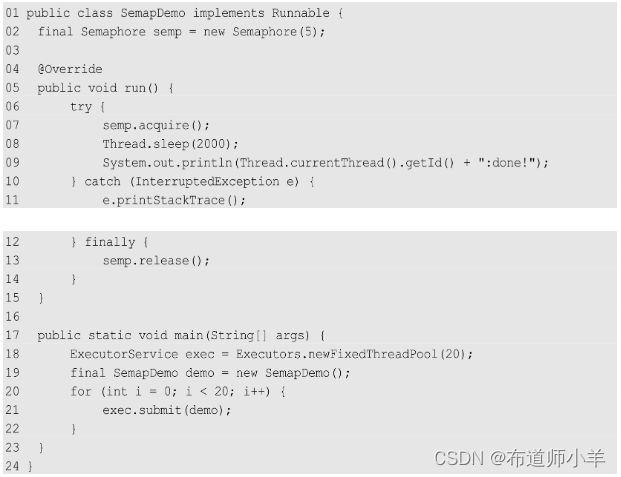
第2行代码声明了一个包含5个许可的信号量。这就意味着同时可以有5个线程进入代码段第7~9行。第7~9行为临界区管理代码,程序会限制执行这段代码的线程数。申请信号量使用acquire()方法操作,在离开时,务必使用release()方法释放信号量(代码第13行)。这和释放锁是一个道理。如果不幸发生了信号量的泄漏(请求了但没有释放),那么可以进入临界区的线程数量就会越来越少,直到所有的线程均不可访问。在本例中,同时开启了20个线程。观察这段代码的输出,你就会发现系统以5个线程为一组,依次输出带有线程ID的提示文本。
3.5、ReadWriteLock读写锁
ReadWriteLock是JDK 5中提供的读写锁,也就是读写分离锁。读写分离锁可以有效地减少锁竞争,提升系统性能。用锁分离的机制来提升性能非常容易理解,比如,A1、A2、A3线程进行写操作,B1、B2、B3线程进行读操作,如果使用重入锁或者内部锁,从理论上说所有读与读之间、读与写之间、写与写之间都是串行操作的。当B1线程进行读取时,B2、B3线程则需要等待锁。由于读操作并不对数据的完整性造成破坏,这种等待显然是不合理的。因此,读写锁就有了发挥作用的地方。
在这种情况下,读写锁允许多个线程同时读,使得B1、B2、B3线程之间实现真正的并行。但是,考虑到数据完整性,写与写之间和读与写之间的操作依然是需要相互等待和持有锁的。总的来说,读写锁的访问约束情况如下:
- 读与读不互斥:读与读之间非阻塞。
- 读与写互斥:读阻塞写,写也会阻塞读。
- 写与写互斥:写与写之间阻塞。
如果在系统中,读操作的次数远远大于写操作的次数,则读写锁就可以发挥最大的功效,提升系统的性能。这里我给出一个稍微夸张点的案例来说明读写锁对性能的帮助:
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @title ReadWriteLockDemo
* @description 读写分离锁
* @author: yangyongbing
* @date: 2024/2/18 13:35
*/
public class ReadWriteLockDemo {
private static Lock lock = new ReentrantLock();
private static ReentrantReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private static Lock readLock = readWriteLock.readLock();
private static Lock writeLock = readWriteLock.writeLock();
private int value;
public Object handleRead(Lock lock) throws InterruptedException {
try {
lock.lock(); // 模拟读操作
Thread.sleep(1000); // 读操作的耗时越多,读写锁的优势就越明显
return value;
} finally {
lock.unlock();
}
}
public void handleWrite(Lock lock, int index) throws InterruptedException {
try {
lock.lock(); // 模拟读操作
Thread.sleep(1000);
value = index;
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
final ReadWriteLockDemo demo = new ReadWriteLockDemo();
Runnable readRunnable = () -> {
try {
demo.handleRead(readLock); // 写锁
// demo.handleRead(lock); // 普通的可重入锁
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Runnable wrteRunnable = () -> {
try {
demo.handleWrite(writeLock,new Random().nextInt()); // 读锁
// demo.handleWrite(lock,new Random().nextInt()); // 普通的可重入锁
} catch (InterruptedException e) {
e.printStackTrace();
}
};
// 读线程
for(int i=0;i<18;i++){
new Thread(readRunnable).start();
}
// 读线程
for(int i=18;i<20;i++){
new Thread(wrteRunnable).start();
}
}
}


上述代码中,第11行和第21行分别模拟了一个非常耗时的操作,让线程耗时1秒,它们分别对应读耗时和写耗时。第34行和第45行分别是读线程和写线程。在这里,第34行使用读锁,第35行使用写锁。第53~55行开启了18个读线程,第57~59行开启了两个写线程。由于这里使用了读写分离,因此读线程完全并行,而写线程会阻塞读线程,因此,实际上这段代码大约运行2秒就能结束(写线程之间实际是串行的)。而如果使用第35行代替第34行,使用第46行代替第45行,执行上述代码,即使用普通的重入锁代替读写锁,则所有的读线程和写线程之间也都必须相互等待,因此整个程序的执行时间将超过20秒。
3.6、倒计数器:CountDownLatch
CountDownLatch是一个非常实用的多线程控制工具类。Count Down在英文中意为倒计数,Latch意为门闩。如果翻译成倒计数门闩,我想大家都会不知所云吧!因此,这里简单地称之为倒计数器。在这里,门闩的含义是把门锁起来,不让里面的线程跑出来。因此,这个工具通常用来控制线程等待,它可以让某一个线程等到倒计数结束再开始执行。
对于倒计数器,一种典型的场景就是火箭发射。在火箭发射前,为了保证万无一失,往往还要对各项设备、仪器进行检查。只有等所有检查都完成后,引擎才能点火。这种场景就非常适合使用CountDownLatch,它可以使点火线程等待所有检查线程全部完工后再执行。
CountDownLatch的构造函数接收一个整数作为参数,即当前这个计数器的计数个数:
public CountDownLatch(int count)
下面这个简单的示例演示了CountDownLatch的使用方法:

上述代码第2行生成了一个CountDownLatch实例,计数数量为10,这表示10个线程完成任务后,等待在CountDownLatch上的线程才能继续执行。代码第10行使用了CountDownLatch.countDown()方法,也就是通知CountDownLatch,一个线程已经完成了任务,倒计数器减1。第21行使用CountDownLatch.await()方法,要求主线程等10个任务全部完成后,才能继续执行。
3.7、循环栅栏:CyclicBarrier
CyclicBarrier是另一种多线程并发控制工具。和CountDownLatch非常类似,它也可以实现线程间的计数等待,但它的功能比CountDownLatch更加复杂且强大。
CyclicBarrier可以理解为循环栅栏。栅栏是一种障碍物,比如,通常在私人宅邸的周围会围上一圈栅栏,阻止闲杂人等入内。CyclicBarrier当然就是用来阻止线程继续执行的,要求线程在栅栏外等待。前面的Cyclic意为循环,也就是说这个计数器可以反复使用。比如,我们将计数器设置为10,那么凑齐第一批10个线程后,计数器就会归零,接着凑齐下一批10个线程,这就是循环栅栏内在的含义。
CyclicBarrier的使用场景也很丰富。比如,司令下达命令,要求10个士兵一起去完成一项任务。这时就会要求10个士兵先集合报到,接着,一起雄赳赳、气昂昂地去执行任务。只有10个士兵把自己手上的任务都执行完了,司令才能对外宣布任务完成!
CyclicBarrier比CountDownLatch略微强大一些,它可以接收一个参数作为barrierAction。所谓barrierAction就是计数器完成一次计数后系统会执行的动作。CyclicBarrier构造函数如下,其中,parties表示计数总数,也就是参与的线程总数:
下面的示例使用CyclicBarrier演示了上述司令命令士兵完成任务的场景:
import java.util.Random;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* @title CyclicBarrierDemo
* @description 循环栅栏
* @author: yangyongbing
* @date: 2024/2/18 14:14
*/
public class CyclicBarrierDemo {
public static class Soldier implements Runnable{
private String soldier;
private final CyclicBarrier cyclicBarrier;
public Soldier(String soldier, CyclicBarrier cyclicBarrier) {
this.soldier = soldier;
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
try {
// 等待所有士兵到齐
cyclicBarrier.await();
doWork();
// 等待所有士兵完成任务
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
void doWork(){
try {
Thread.sleep(Math.abs(new Random().nextInt()%10000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(soldier+":完成任务");
}
}
public static class BarrierRun implements Runnable{
boolean flag;
int N;
public BarrierRun(boolean flag, int n) {
this.flag = flag;
N = n;
}
@Override
public void run() {
if(flag){
System.out.println("报告司令:【士兵"+N+"个,完成任务!】");
}else {
System.out.println("报告司令:【士兵"+N+"个,集合完毕!】");
flag=true;
}
}
}
public static void main(String[] args) {
final int N=10;
Thread[] allSoldier=new Thread[N];
boolean flag=false;
CyclicBarrier cyclic=new CyclicBarrier(N,new BarrierRun(flag,N));
// 设置屏障点,主要是为了执行这个方法
System.out.println("集合队伍");
for(int i=0;i<N;++i){
System.out.println("士兵"+i+"报道!");
allSoldier[i]=new Thread(new Soldier("士兵"+i,cyclic));
allSoldier[i].start();
}
}
}


上述代码第57行创建了CyclicBarrier实例,并将计数器设置为10,要求在计数器达到指标时,执行第43行的run()方法。每一个士兵线程都会执行第11行定义的run()方法。在第14行,每一个士兵线程都会等待,直到所有的士兵都集合完毕。集合完毕意味着CyclicBarrier的一次计数完成,当再一次调用CyclicBarrier.await()方法时,会进行下一次计数。第15行模拟了士兵的任务。如果一个士兵任务执行完,就会要求CyclicBarrier开始下一次计数,这次计数主要目的是监控是否所有的士兵都已经完成了任务。一旦任务全部完成,第35行定义的BarrierRun就会被调用,打印相关信息。
执行上述代码的输出如下:

CyclicBarrier.await()方法可能会抛出两个异常。一个是InterruptedException,也就是在等待过程中,线程被中断,应该说这是一个非常常见的异常。大部分迫使线程等待的方法都可能会抛出这个异常,使得线程在等待时依然可以响应外部紧急事件。另一个异常则是CyclicBarrier特有的BrokenBarrierException。一旦遇到这个异常,则表示当前的CyclicBarrier已经破损了,可能系统没有办法等待所有线程到齐了。如果继续等待,就可能徒劳无功,因此,还是“打道回府”吧!上述代码第18~22行处理了这两个异常。
我们在上述代码的第63行后,插入以下代码,使得第5个士兵线程产生中断:

如果这样做,就很可能得到1个InterruptedException和9个BrokenBarrierException。其中,InterruptedException是被中断线程抛出的,而其他9个BrokenBarrierException则是等待在当前CyclicBarrier上的线程抛出的。InterruptedException可以避免其他9个线程进行永久的、无谓的等待(因为其中一个线程已经被中断,所以等待是没有结果的)。
3.8、线程阻塞工具类:LockSupport
LockSupport是一个非常方便实用的线程阻塞工具,它可以在线程内任意位置让线程阻塞。与Thread.suspend()方法相比,它弥补了由于resume()方法导致线程无法继续执行的情况。和Object.wait()方法相比,它不需要先获得某个对象的锁,也不会抛出InterruptedException异常。
LockSupport的静态方法park()可以阻塞当前线程,类似的还有parkNanos()、parkUntil()等方法,它们实现了一个限时等待。

注意,这里只是将原来的suspend()方法和resume()方法用park()方法和unpark()方法做了替换。当然,我们依然无法保证unpark()方法发生在park()方法之后。但是执行这段代码时,你会发现,它自始至终都可以正常地结束,不会因为park()方法而导致线程被永久挂起。
这是因为LockSupport类使用了类似信号量的机制。它为每一个线程准备了一个许可,如果许可可用,那么park()方法会立即返回,并且消费这个许可(也就是将许可变为不可用),如果许可不可用,就会阻塞,而unpark()方法则会使一个许可变为可用(和信号量不同的是,许可不能累加,你不可能拥有超过一个许可,它永远只有一个)。
这个特点使得:即使unpark()方法发生在park()方法之前,它也可以使下一次的park()方法立即返回。这也就是上述代码可顺利结束的主要原因。
同时,处于park()方法挂起状态的线程不会像suspend()方法那样给出一个令人费解的RUNNABLE状态,它会非常明确地给出一个WAITING状态,甚至还会标注是park()方法引起的:

这使得我们在分析问题时格外方便。此外,如果你使用park(Object)方法,那么还可以为当前线程设置一个阻塞对象。这个阻塞对象会出现在线程Dump中。这样,在分析问题时就更加方便了。
比如,我们将上述代码第14行的park()方法改为:

那么在线程“Dump”时,你可能会看到如下信息:
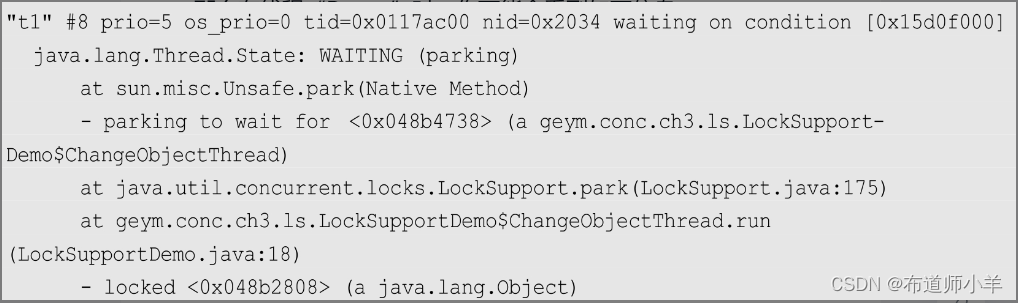
注意,在堆栈中,我们甚至还看到了当前线程等待的对象,这就是ChangeObjectThread实例。
除了有定时阻塞的功能,LockSupport.park()方法还能支持中断响应。但是和其他接受中断的方法很不一样,LockSupport.park()方法不会抛出InterruptedException异常,它只会默默返回,我们可以从Thread.interrupted()等方法中获得中断标记:

注意,上述代码在第27行中断了处于park()方法状态的t1,之后,t1可以马上响应这个中断,并且返回。t1返回后,在外面等待的t2才可以进入临界区,并最终通过LockSupport.unpark(t2)操作使其执行结束:

3.9、深入理解锁:AbstractQueuedSynchronizer
我们已经知道,重入锁(ReentrantLock)和信号量(Semaphore)是两个极其重要的并发控制工具。它们很好用,但是它们内部是如何实现的呢?首先来看下图:
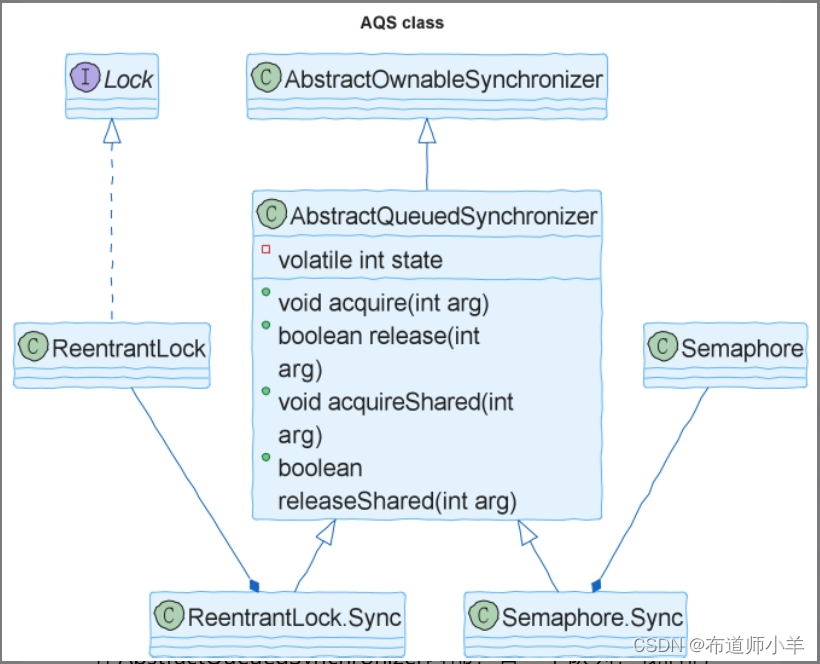
可以看到,重入锁和信号量都在自己内部实现了一个AbstractQueuedSynchronizer的子类。子类的名字都是Sync。而这个Sync类,正是重入锁和信号量的核心实现。子类Sync中的代码比较少,其核心算法都由AbstractQueuedSynchronizer提供。因此,可以说,只要了解了AbstractQueuedSynchronizer,就能清楚地知道重入锁和信号量的实现原理。
3.9.1、AbstractQueuedSynchronizer的内部数据结构
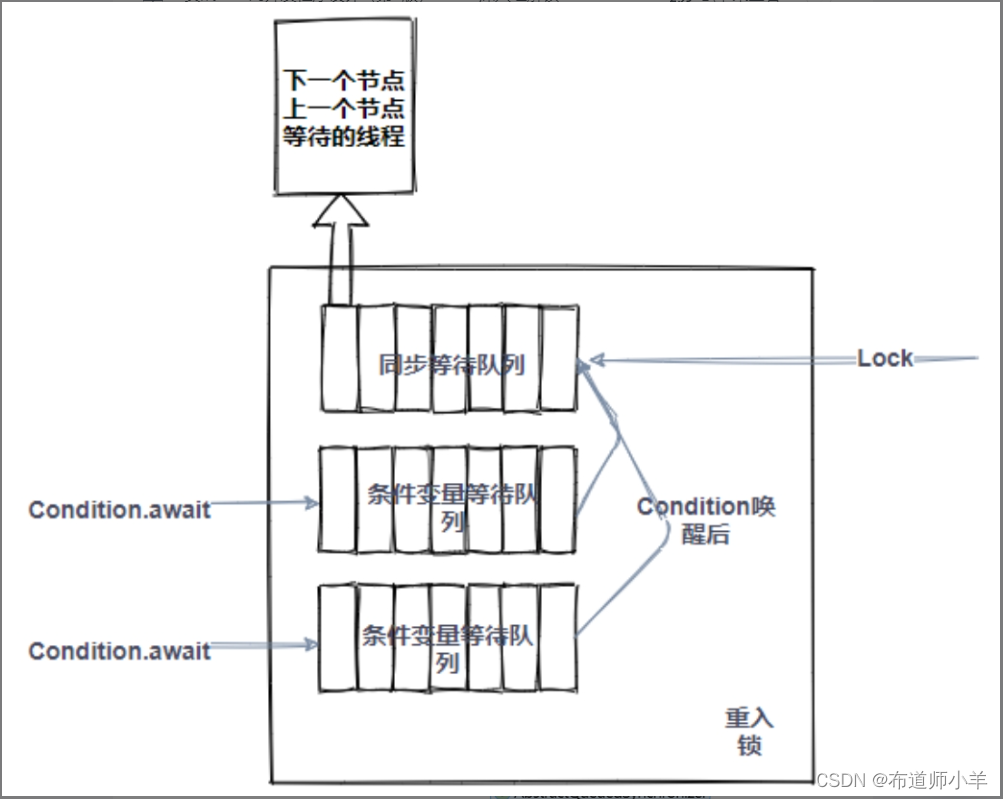
在AbstractQueuedSynchronizer内部,有一个队列,我们把它叫作同步等待队列。它的作用是保存等待在这个锁上的线程(由lock()操作引起的等待)。此外,为了维护等待在条件变量上的等待线程,AbstractQueuedSynchronizer又需要维护一个条件变量等待队列,也就是那些由Condition.await()方法引起阻塞的线程。由于一个重入锁可以生成多个条件变量对象,因此一个重入锁就可能有多个条件变量等待队列。实际上,每个条件变量对象内部都维护了一个等待列表。其内部逻辑结构如下图所示:
下图展示了代码层面的具体实现:
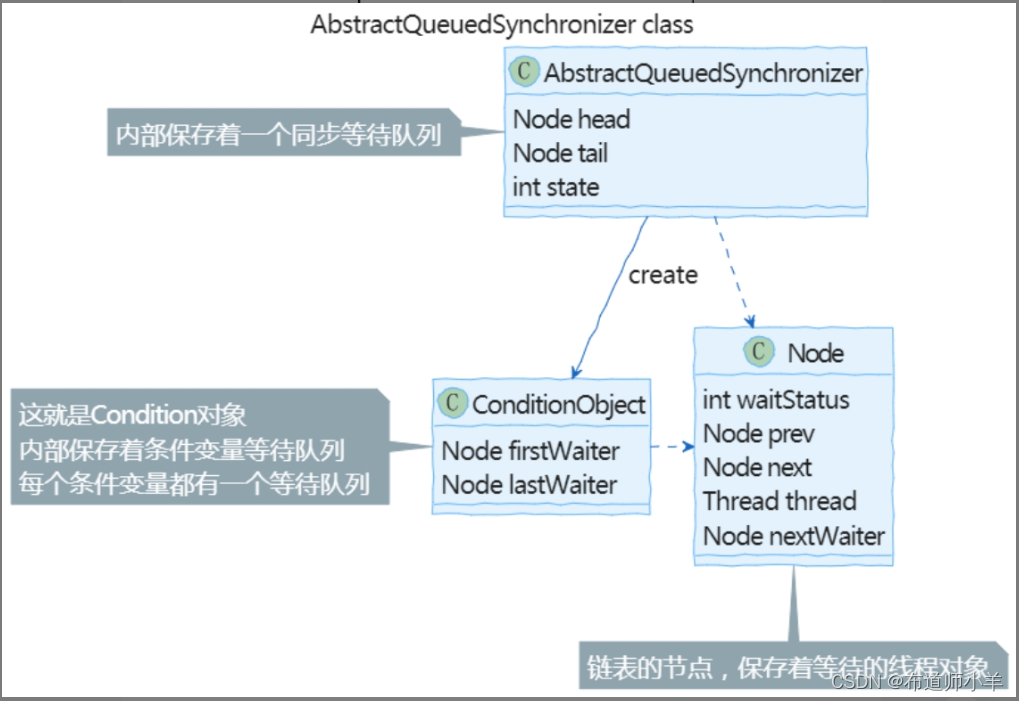
可以看到,无论是同步等待队列,还是条件变量等待队列,都使用同一个Node类作为链表的节点。对于同步等待队列,Node中包括链表的上一个元素prev、下一个元素next和线程对象thread。对于条件变量等待队列,还使用了nextWaiter表示下一个在条件变量队列中等待的节点。
Node节点的另一个重要成员是waitStatus,表示节点在队列中的等待状态,可选值如下:
- CANCELLED:表示线程取消了等待。如果在获得锁的过程中发生了一些异常,则可能出现取消等待的情况,比如等待过程中出现了中断异常或者出现了timeout。
- SIGNAL:表示后续节点需要被唤醒。
- CONDITION:线程在条件变量队列中等待。
- PROPAGATE:在共享模式下,无条件传播releaseShared状态。早期的JDK并没有这个状态,乍看之下,这个状态是多余的。引入这个状态是为了解决由共享锁并发释放导致线程挂起的BUG 6801020。(随着JDK的不断完善,它的代码也越来越难懂,就和我们自己的工程代码一样,BUG修多了,细节就显得越来越晦涩。)
- 0:初始状态。
其中CANCELLED=1,SIGNAL=-1,CONDITION=-2,PROPAGATE=-3。在具体的实现中,可以简单地通过waitStatus是否小于或等于0来判断是否是CANCELLED状态。
3.9.2、排他锁的核心实现
在了解了AbstractQueuedSynchronizer的核心数据结构和基本实现思路后,下面我们就来揭开AbstractQueuedSynchronizer的庐山真面目吧!
首先是请求锁的实现:

我们进一步看一下tryAcquire()方法。该方法的作用是尝试获得一个许可。对于AbstractQueuedSynchronizer来说,这是一个未实现的抽象方法,具体实现在子类中。在重入锁、读写锁和信号量等具体类中,都有各自的实现。
如果tryAcquire()方法执行成功,则acquire()直接返回成功。如果失败,就用addWaiter()方法将当前线程加入同步等待队列中:

接着,对已经在队列中的线程请求锁,使用acquireQueued()方法,其参数node必须是一个已经在队列中等待的节点。它的功能就是为已经在队列中的节点请求一个许可。这个方法大家要好好看看,因为无论是普通的lock()方法,还是条件变量的await()方法,都会使用这个方法:

接着来看一下条件变量等待的实现方法。如果调用Condition.await()方法,那么线程也会进入等待,下面是它的代码和实现原理说明:

相应地,当Condition对象得到通知时,就会在条件队列中等待按照FIFO原则执行。首先选择第一个节点:

释放排他锁:

在了解了排他锁后,再来看一下共享锁的实现。与排他锁相比,共享锁的实现略微复杂一点。这也很好理解,因为排他锁的场景很简单——单进单出,而共享锁就不一样了,可能是N进M出,处理起来要麻烦一些。但是,它们的核心思想还是一致的。共享锁的典型应用有信号量和读写锁中的读锁。
首先来看一下共享锁的请求。为了实现共享锁,AbstractQueuedSynchronizer中有一套专门针对共享锁的方法。
使用acquireShared()方法获得共享锁:




释放共享锁:

AbstractQueuedSynchronizer是一个比较复杂的实现,要完全理解其中的细节还需要慢慢品味。但不可否认,深入理解AbstractQueuedSynchronizer,对大家认识重入锁、信号量和读写锁会有较大的帮助。
3.10、Guava和RateLimiter限流
Guava是Google的一个核心库,提供了一大批设计精良、使用方便的工具类。许多Java项目都使用Guava作为其基础工具库来提升开发效率,我们可以认为Guava是JDK标准库的重要补充。在这里,将给大家介绍Guava中的一款限流工具RateLimiter。
任何应用和模块组件都有一定的访问速率上限,如果请求速率突破了这个上限,那么不但多余的请求无法处理,甚至会压垮系统,使所有的请求均无法有效处理。因此,对请求进行限流是非常必要的。RateLimiter正是这样一款限流工具。
一种简单的限流算法就是给出一个单位时间,然后使用一个计数器counter统计单位时间内收到的请求数量,当请求数量超过已设定的阈值时,丢弃余下的请求或者等待。这种简单的算法有一个严重的问题,就是很难控制边界时间上的请求。假设时间单位是1秒,每秒请求数不超过10,如果在这1秒的前半秒没有请求,而后半秒有10个请求,下1秒的前半秒又有10个请求,那么在这中间的1秒内,就会合理处理20个请求,而这明显违反了限流的基本需求。这是一种简单粗暴的总数量限流而不是平均限流,如下图所示:

因此,更为一般化的限流算法有两种:漏桶算法和令牌桶算法。
漏桶算法的基本思想是:利用一个缓存区,当有请求进入系统时,无论请求的速率如何,都先保存在缓存区内,然后以固定的流速流出缓存区并加以处理,如下图所示:

漏桶算法的特点是无论外部请求压力如何,漏桶算法总是以固定的流速处理数据。漏桶的容积和流出速率是该算法的两个重要参数。
令牌桶算法是一种反向的漏桶算法。在令牌桶算法中,桶中存放的不再是请求,而是令牌。处理程序只有拿到令牌后,才能对请求进行处理。如果没有令牌,那么处理程序要么丢弃请求,要么等待可用的令牌。为了限制流速,该算法在每个单位时间产生一定量的令牌存入桶中。比如,要限定应用每秒只能处理1个请求,那么令牌桶就会每秒产生1个令牌。通常,桶的容量是有限的,比如,当令牌没有被消耗掉时,只能累计有限单位时间内的令牌数量,其基本原理如下图所示:

RateLimiter正是采用了令牌桶算法,下例展示了RateLimiter的使用方法:
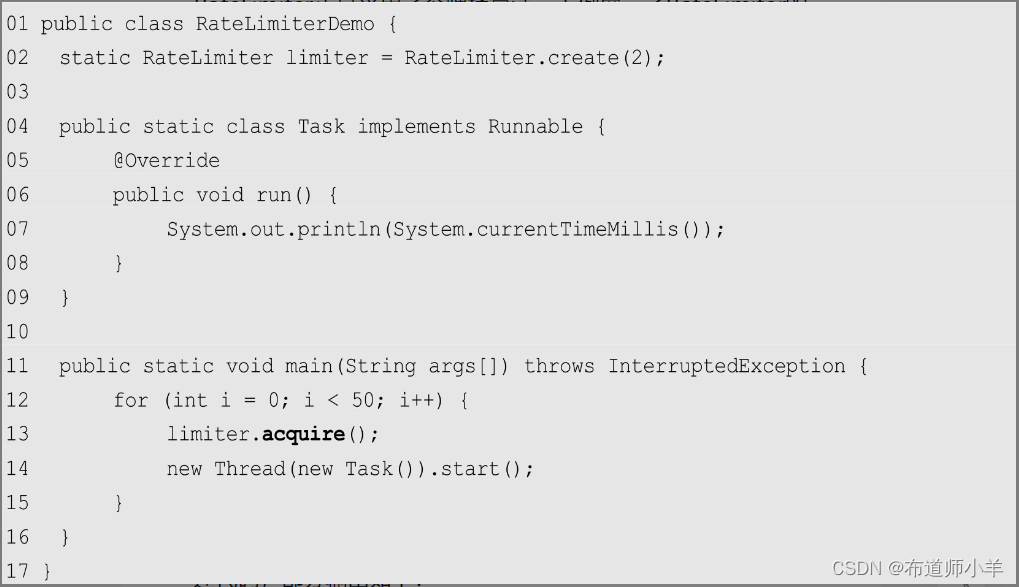
上述代码第2行限制了RateLimiter,每秒只能处理两个请求。在第13行调用RateLimiter的acquire()方法来控制流量。执行上述代码,部分输出如下:

从输出的时间戳可以看到每秒最多输出两条记录,起到了流量控制的效果。当使用acquire()方法时,过剩的流量调用会等待,直到有机会执行。
但在有些场景中,如果系统无法处理请求,为了保证服务质量,则更倾向于直接丢弃过载请求,从而避免可能的系统崩溃。此时,可以使用tryAcquire()方法,如下所示:

当请求成功时,tryAcquire()方法返回true,否则返回false,该方法不会阻塞。在本段代码中,如果访问数据量超过限制,则直接丢弃超出部分,不再处理。根据前面的描述,limiter仅支持1秒调用两次,也就是每500毫秒可以产生一个令牌。显然,由于for循环本身的执行效率很高,完全可以在500毫秒内完成,因此本段代码最终只产生一个输出,其余请求全部被丢弃:

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









