







1、爬虫相关:
TED-Talks的视频(www.ted.com/talks) 云集了曾踏上过TED讲坛、举世闻名的思想家、艺术家和科技专家。在TED.com网站上,我们可以免费下载这些视频。视频包含了可以互动的英文讲稿以及多达80多个语种的字幕。
这次的爬取场景是将某个演讲视频下英语和匈牙利语的字幕稿给抽取出来并一一对应后写入文件,并利用Selenium随机点击下一个视频,不断执行上述操作。
英语字幕稿: 例子链接:https://www.ted.com/talks/fabio_pacucci_could_the_earth_be_swallowed_by_a_black_hole/transcript
匈牙利语字幕稿: 例子链接=英文链接+?language=hu
点击下一个: 每个视频右边都会有一列推荐视频,只要用selenium进行随机某一个进入下一个视频就行。
2、需解决的问题:
- 有些视频没有匈牙利语字幕:每次点击视频时,视频默认下方是英语字幕,但可能没有匈牙利语字幕;如果没有匈牙利语字幕,在英文加完?language=hu会得到404的相应。而selenium随机点击后都是默认英文字幕,所以得在链接后?language=hu看selenium能不能捕捉到元素,如果捕捉不到,就说明此视频没有匈牙利语字幕就得跳回视频的英文字幕链接,并直接随机点推荐视频,直到某个视频有匈牙利语字幕才开始抽取字幕。
- 爬取速度过慢: 换成无头浏览器,不用PhantomJS的原因是PhantomJS已停止开发,谷歌浏览器已不支持。
options.add_argument('--headless') - 异常捕捉
3、环境:
- Python 3.6 版本
- Python的selenium库
4、项目结构:
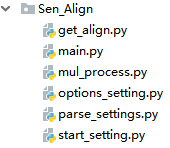
- get_align.py: 实现爬虫
- main.py : 实现用户调用,略过
- mul_process.py :多进程,略过
- options_settings.py : webdriver参数配置文件
- parse_settings.py : 解析语句文件
- start_setting.py : 项目基础配置文件
1、爬虫实现代码
'''
这里是 import
'''
__author = 'cyy'
local = threading.local()
id = 0
local.id = id
class Get_Align(object):
'''
获得对齐句对
'''
def __init__(self,num,frequecy):
self.__num = num
self.__path = text_path[self.__num-1]
self.frequecy = frequecy
self.driver = None
self.hu_behind = behind
self.en_texts = []
self.hu_texts = []
self.start_url = start_urls[self.__num - 1]
@property
def num(self):
return self.__num
@num.setter
def num(self,value):
self.__num=value
def __call__(self, *args, **kwargs):
return self.get_align()
def get_align(self):
f = open(self.__path,'a',encoding='utf-8')
self.driver = webdriver.Chrome(chrome_options=options)
self.driver.maximize_window()
self.driver.get(self.start_url + self.hu_behind)
hu = self.driver.find_elements_by_css_selector(text)
for h in hu:
self.hu_texts.append(h.text)
self.driver.get(self.start_url)
en = self.driver.find_elements_by_css_selector(text)
for e in en:
self.en_texts.append(e.text)
for i in range(len(self.hu_texts)):
try:
f.writelines(self.en_texts[i]+'\n')
f.writelines(self.hu_texts[i]+'\n' + '\n')
except IndexError as e:
break
f.close()
local.id += 1
print(local.id)
self.get_align_continue()
def check_hu(self):
'''
检查视频是否有匈牙利字幕
:return:
'''
ne = self.driver.find_elements_by_xpath(click)
if not ne:
local.id -= 1
self.driver.back()
ne = self.driver.find_elements_by_xpath(click)
ra = random.choice(ne)
ra.click()
return self.check_hu()
else:
pass
def get_align_continue(self):
next = self.driver.find_element_by_xpath(click).click()
for i in range(2, self.frequecy):
f = open(self.__path, 'a', encoding='utf-8')
self.en_texts , self.hu_texts = [] , []
en_url = self.driver.current_url
self.driver.get(self.driver.current_url + '/transcript' + self.hu_behind)
self.check_hu()
hu = self.driver.find_elements_by_css_selector(text)
for h in hu:
self.hu_texts.append(h.text)
self.driver.get(en_url + '/transcript')
en = self.driver.find_elements_by_css_selector(text)
for e in en:
self.en_texts.append(e.text)
try:
for i in range(len(self.hu_texts)):
f.writelines(self.en_texts[i] + '\n')
f.writelines(self.hu_texts[i] + '\n' + '\n')
except IndexError as e:
print(e.args)
f.close()
local.id += 1
print(local.id)
try:
next = self.driver.find_elements_by_xpath(click)
choice=random.choice(next)
choice.click()
except IndexError as e:
next = self.driver.find_element_by_xpath(click)
next.click()
self.driver.close()
2、有关配置
- options_settings.py:webdriver参数配置文件
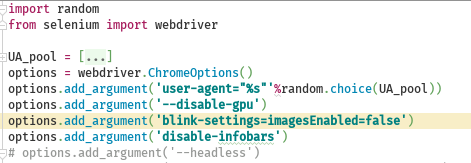
- parse_settings.py : 解析语句文件

- start_setting.py : 项目基础配置文件

3、运行效果

















 2419
2419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









