







🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇
⭐ HTTP ⭐
🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇🎇
今日推荐歌曲: 念旧 -—— 姜铭杨 🎵🎵
系列文章目录
【网络原理 2】UDP 协议的报文结构和注意事项-CSDN博客
【网络原理 3】TCP协议的相关特性(三次握手,四次挥手)(万字详解)看完必懂 !-CSDN博客
【网络原理 4 】应用层中 服务器和客户端的传输-CSDN博客
【网络原理 5 】网络层中的 ” 主宰 “ IP 协议-CSDN博客
【网络原理 8】HTTP 协议的基本格式和 fiddler 的用法-CSDN博客
【网络原理 9】HTTP协议 请求 & 响应 超详解 看这篇就够-CSDN博客
【网络原理 10】HTTPS 协议 工作过程 超细节(精心配图)-CSDN博客
目录
4. HTTP 从客户端到服务端发送从url到发送完成到底发生了什么???⭐⭐
前言
接上篇文章,【网络原理 8】HTTP 协议的基本格式和 fiddler 的用法-CSDN博客,这里详细介绍HTTP 的 请求 和 响应。
HTTP请求 (Request)
HTTP(Hypertext Transfer Protocol)是一种应用层协议,用于在Web浏览器和Web服务器之间传输数据。HTTP请求和响应是HTTP协议中最基本的消息类型。
HTTP请求包含以下内容:
- 请求行:包括HTTP方法(GET,POST等)、请求URI和HTTP版本号;
- 请求头部:包括一系列关于请求的元数据,如Host、User-Agent、Accept等;
- 空行:请求头部和请求正文之间需要空一行;
- 请求正文(可选):包含请求提交的数据,如表单数据、文件等。
1. 认识URL
1.1 URL基本格式
平时我们俗称的"⽹址"其实就是说的 URL(UniformResourceLocator统⼀资源定位符) . 互联⽹上的每个⽂件都有⼀个唯⼀的URL,它包含的信息指出⽂件的位置以及浏览器应该怎么处理它. URL的详细规则由因特⽹标准RFC1738进⾏了约定.RFC 1738 - Uniform Resource Locators (URL)

⼀个具体的URL:
https://v.bitedu.vip/personInf/student?userId=10000&classId=100
可以看到,在这个URL中有些信息被省略了.
- https:协议方案名. 常见的有http和https,也有其他的类型.(例如访问mysql时用的jdbc :mysql))
- user:pass: 登陆信息.现在的网站进行身份认证一般不再通过URL进行了.一般都会省略
- v.bitedu.vip : 服务器地址.此处是一个"域名",域名会通过DNS系统解析成一个具体的IP地址.(通过ping 命令可以看到, v.bitedu.vip的真实IP地址为118.24.113.28 )
- 端口号 : 上面的URL中端口号被省略了.当端口号省略的时候,浏览器会根据协议类型自动决定使用哪个端口.例如 http 协议默认使用80端口, https 协议默认使用443端口.
- / personInf /student:带层次的文件路径.
- userId=10000&classId=100:查询字符串(query string). 本质是一个键值对结构.键值对之间使用&分隔.键和值之间使用=分隔.
- 片段标识: 此URL中省略了片段标识.片段标识主要用于页面内跳转.(例如Vue官方文档: https://cn.vuejs.org/v2/guide/#%E8%B5%B7%E6%AD%A5,通过不同的片段标识跳转到文档的不同章节)
使⽤ping命令查看域名对应的IP地址.如下图:
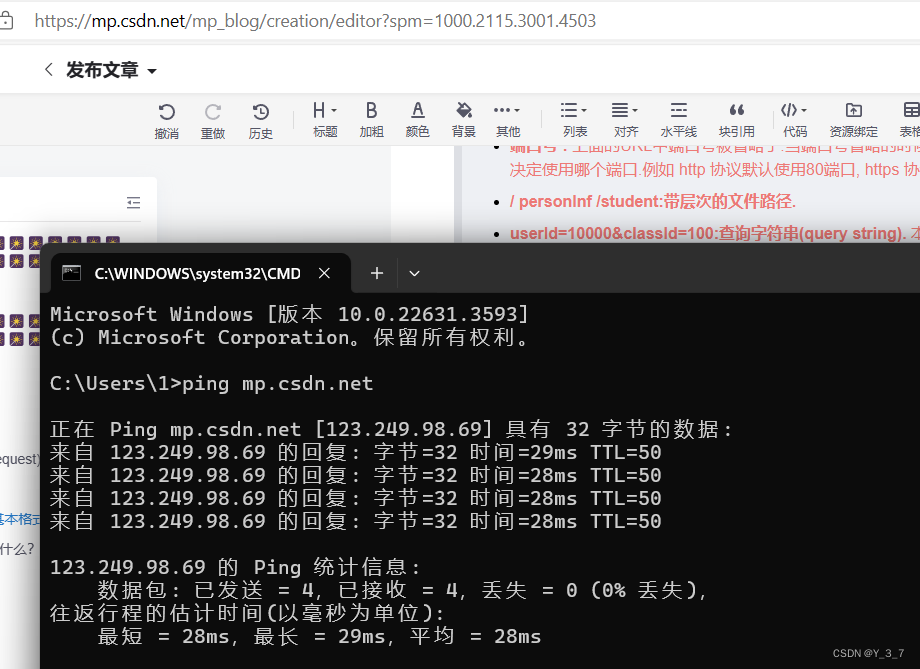
PS: 有的电脑上ping命令会报错 ping 不是内部或外部命令,也不是可运⾏的程序或批处理⽂件 . 这种情况是因为有的Windows10默认没有启⽤ping命令. 百度搜索 windows10 启⽤ ping 即可.
关于 querystring
query string 中的内容是键值对结构.其中的key和value的取值和个数,完全都是程序猿⾃⼰约定 的.我们可以通过这样的⽅式来⾃定制传输我们需要的信息给服务器.
URL中的可省略部分
• 协议名:可以省略,省略后默认为http://
• ip地址/域名:在HTML中可以省略(⽐如img,link,script,a标签的src或者href属性).省略后表 ⽰服务器的ip/域名与当前HTML所属的ip/域名⼀致.
• 端⼝号:可以省略.省略后如果是http协议,端⼝号⾃动设为80;如果是https协议,端⼝号⾃动设为 443.
• 带层次的⽂件路径:可以省略.省略后相当于/.有些服务器会在发现/路径的时候⾃动访问 /index.html
• 查询字符串:可以省略
• ⽚段标识:可以省略
所以可以只有服务器地址就可以访问了。
1.2 关于 URLencode
像/?:等这样的字符,已经被url当做特殊意义理解了.因此这些字符不能随意出现.
⽐如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进⾏转义.
⼀个中⽂字符由UTF-8或者GBK这样的编码⽅式构成,虽然在URL中没有特殊含义,但是仍然需要进 ⾏转义.否则浏览器可能把UTF-8/GBK编码中的某个字节当做URL中的特殊符号
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不⾜4位直接处理),每2位做 ⼀位,前⾯加上%,编码成%XY格式
例如:
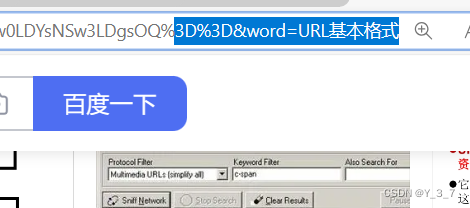
" = " 被转义成了" %3D " urldecode 就是 urlencode 的逆过程;
2. 认识"⽅法"(method)
1. GET⽅法
GET是最常⽤的HTTP⽅法.常⽤于获取服务器上的某个资源. 在浏览器中直接输⼊URL,此时浏览器就会发送出⼀个GET请求.
另外,HTML中的link,img,script等标签,也会触发GET请求. 使⽤JavaScript中的ajax也能构造GET请求.
使⽤Fiddler观察GET请求
打开Fiddler,访问搜狗主⻚,观察抓包结果

箭头指向的就是通过浏览器地址栏发送的GET请求,下⾯的和 sogou 域名相关的请求,有些是通过html中的link/script/img标签产⽣的,例如

有些是通过ajax的⽅式产⽣的,例如

选中 GET请求 观察请求的详细结果
1 GET https: / / www . sogou.com/ HTTP/1.1
2 Host: www . sogou. com
3 Connection: keep-alive4 Cache-Control: max-age=0
5 sec-ch-ua: " Not;A Brand" ;v="99","Google Chrome" ;v="91", "Chromium" ; v="91"6 sec-ch-ua-mobile: ?0
7 Upgrade-Insecure-Requests: 1
8 User-Agent: Mozilla/5.0 (windows NT 10.0; win64; x64) ApplewebKit/537.36(KHTML,9 Accept: text/html,application/xhtml+xml,application/xml; q=0.9,image/avif, image/w
10 Sec-Fetch-Site: none
11 Sec-Fetch-Mode: navigate12 Sec-Fetch-User: ?1
13 Sec-Fetch-Dest: document
14 Accept-Encoding: gzip,deflate,br
15 Accept-Language: zh-CN ,zh;q=0.9,en;q=0.8
16 Cookie:SUID=19AA8B7B6E1CAOOA000000005F9A2F76;SUV=1603940214073598;pgv_pvi=266
2.1 GET请求的特点
• ⾸⾏的第⼀部分为GET
• URL的 querystring 可以为空,也可以不为空.
• header部分有若⼲个键值对结构.
• body部分为空.
关于GET请求的URL长度问题
网上有些资料上描述: get请求长度最多1024kb这样的说法是错误的.
HTTP协议由RFC2616标准定义,标准原文中明确说明: "Hypertext Transfer Protocol-HTTP/1.1,"does not specify any requirement for URL length.
没有对URL的长度有任何的限制.
实际URL的长度取决于浏览器的实现和HTTP服务器端的实现.在浏览器端, 不同的浏览器最大长度是不同的, 但是现代浏览器支持的长度一般都很长;在服务器端, 一般这个长度是可以配置的.
2. POST⽅法
POST⽅法也是⼀种常⻅的⽅法.多⽤于提交⽤⼾输⼊的数据给服务器(例如登陆⻚⾯).
通过HTML中的form标签可以构造POST请求,或者使⽤JavaScript的ajax也可以构造POST请求.
使⽤Fiddler观察POST⽅法
在登陆⻚⾯,输⼊⽤⼾名,密码,验证码之后,点击登陆,就可以看到POST请求.

POST请求的特点
• ⾸⾏的第⼀部分为POST
• URL的querystring⼀般为空(也可以不为空)
• header部分有若⼲个键值对结构.
• body部分⼀般不为空.body 内的数据格式通过 header 中的 由header中的 Content-Length 指定.
GET和POST的区别
经典⾯试题
• 语义不同:GET⼀般⽤于获取数据,POST⼀般⽤于提交数据. Content-Type 指定.body的⻓度
• GET的body⼀般为空,需要传递的数据通过querystring传递,POST的querystring⼀般为空,需 要传递的数据通过body传递
• GET请求⼀般是幂等的,POST请求⼀般是不幂等的.(如果多次请求得到的结果⼀样,就视为请求是 幂等的).
• GET可以被缓存,POST不能被缓存.(这⼀点也是承接幂等性).
补充说明:
• 关于语义:GET完全可以⽤于提交数据,POST也完全可以⽤于获取数据.
• 关于幂等性: 标准建议GET实现为幂等的.实际开发中GET也不必完全遵守这个规则(主流⽹站都有 "猜你喜欢"功能,会根据⽤⼾的历史⾏为实时更新现有的结果.
• 关于安全性: 有些资料上说"POST⽐GET请安全".这样的说法是不科学的.是否安全取决于前端在 传输密码等敏感信息时是否进⾏加密,和GETPOST⽆关.
• 关于传输数据量: 有的资料上说"GET传输的数据量⼩,POST传输数据量⼤".这个也是不科学的,标 准没有规定GET的URL的⻓度,也没有规定POST的body的⻓度.传输数据量多少,完全取决于不 同浏览器和不同服务器之间的实现区别.
• 关于传输数据类型: 有的资料上说"GET只能传输⽂本数据,POST可以传输⼆进制数据".这个也是 不科学的.GET的querystring虽然⽆法直接传输⼆进制数据,但是可以针对⼆进制数据进⾏url encode.
任何⼀个能进⾏⽹络编程的语⾔都可以构造HTTP请求.本质上就是通过TCPsocket写⼊⼀个符合 HTTP协议规则的字符串.
3. 认识请求"报头"(header)
header 的整体的格式也是"键值对"结构. 每个键值对占⼀⾏.
键和值之间使⽤分号分割. 报头的种类有很多,此处仅介绍⼏个常⻅的.
Host : 表⽰服务器主机的地址和端⼝.
Content-Length :表⽰body中的数据⻓度.
Content-Type :表⽰请求的body中的数据格式(图片,视频,文本...).
text/html:表示响应正文是HTML格式的文本,通常用于网页内容的展示。text/css:表示响应正文是CSS格式的文本,通常用于网页样式的设置和控制。application/javascript:表示响应正文是JavaScript格式的文本,通常用于网页动态效果、事件处理等脚本编程。application/json:表示响应正文是JSON格式的文本,通常用于数据传输、交换等。
MIME types (IANA media types) - HTTP | MDN
User-Agent (简称UA)
表⽰浏览器/操作系统的属性.形如
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
其中 Windows NT 10.0; Win64; x64 表⽰操作系统信息
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 表⽰浏览器信息.
Referer
表⽰这个⻚⾯是从哪个⻚⾯跳转过来的.形如
https://v.bitedu.vip/login
如果直接在浏览器中输⼊URL,或者直接通过收藏夹访问⻚⾯时是没有Referer的.
Cookie
Cookie是一种在客户端(通常是Web浏览器)和服务器之间传递的小型数据片段,它存储在用户的计算机上,并由浏览器在之后的请求中发送到同一服务器。Cookie通常用于跟踪用户的会话信息、记录用户的偏好设置、实现购物车功能等。
Cookie由服务器发送到客户端的HTTP响应头部中,其中包含了一些关键信息,比如Cookie的名称、值、过期时间、作用域等。一旦存储在客户端,Cookie会在每次与同一服务器的通信中被发送到服务器,以便服务器可以识别用户并提供个性化的服务。
Cookie可以分为两种类型:
会话Cookie:这种Cookie存储在用户计算机的内存中,并且在用户关闭浏览器时被删除。会话Cookie通常用于存储临时数据,比如用户的会话标识符,以便服务器在用户浏览网站期间识别用户。
持久Cookie:这种Cookie存储在用户计算机的硬盘上,并且可以在多次会话之间保留。持久Cookie通常具有过期时间,在过期之前会一直存在于用户计算机上。持久Cookie常用于存储用户的偏好设置、登录凭证等长期有效的信息。
尽管Cookie在提供个性化服务和跟踪用户行为方面具有很大的用处,但也存在一些隐私和安全方面的问题。比如,Cookie可能被用于跟踪用户的浏览历史,并且可能被恶意利用来窃取用户的个人信息。因此,许多浏览器都提供了对Cookie的管理功能,用户可以选择是否接受Cookie,以及在什么情况下接受。
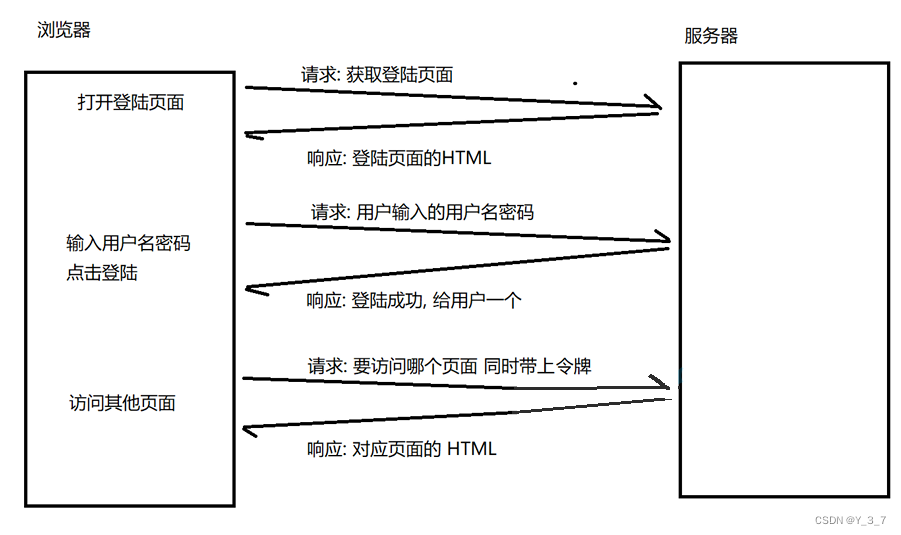
Cookie 一般用于记录⽤⼾当前登陆的⾝份标识.也称为"令牌(token)"
理解登陆过程
4. 认识请求"正⽂"(body)
正⽂中的内容格式和header中的Content-Type密切相关.
HTTP请求中的"正文"(body)是指在HTTP请求中发送的数据部分。在HTTP请求中,正文通常用于传输一些数据,比如表单数据、JSON数据、XML数据等。正文是可选的,因为并非所有的HTTP请求都需要在正文中发送数据。
正文部分通常出现在POST请求和PUT请求中,而GET请求通常不包含正文,因为GET请求是通过URL传递参数的。在POST请求和PUT请求中,正文通常是以键值对的形式发送数据,也可以是JSON格式、XML格式等。
例如,在一个POST请求中,如果用户提交了一个表单,表单中包含了用户名和密码,那么这些数据就可以放在请求的正文中,以键值对的形式发送到服务器。服务器在接收到这个请求后,就可以从正文中提取出用户名和密码,进行相应的处理。
总之,HTTP请求中的正文部分用于传输一些数据,这些数据可以是各种格式的,根据请求的需要来决定。
HTTP响应 (Response)
HTTP响应包含以下内容:
- 状态行:包括HTTP版本、响应状态码和对应的状态消息;
- 响应头部:包括一系列关于响应的元数据,如Content-Type、Content-Length、Server等;
- 空行:响应头部和响应正文之间需要空一行;
- 响应正文:包含响应的数据,如HTML、XML、JSON等文档格式、图片、音频、视频等二进制数据等等。
1. 认识"状态码"(statuscode)
状态码(status code)是在HTTP协议中用于表示服务器对客户端请求的处理结果的数字代码。通过状态码,客户端可以了解到请求的处理结果,如访问是否成功、是否需要重定向、是否存在错误等。
以下是常见的HTTP状态码及其含义:
1xx:信息性响应
- 100:继续(Continue)- 表示服务器接收到请求,客户端可以继续发送请求的剩余部分。
- 101:切换协议(Switching Protocols)- 表示服务器正在切换协议,例如从HTTP切换到WebSocket。
2xx:成功响应
- 200:成功(OK)- 表示请求已成功处理,并返回相应的内容。
- 201:已创建(Created)- 表示请求已成功处理,并在服务器上创建了新的资源。
- 204:无内容(No Content)- 表示请求已成功处理,但没有返回任何内容。
3xx:重定向
- 301:永久重定向(Moved Permanently)- 请求的资源已永久移动到新位置。
- 302:临时重定向(Found)- 请求的资源临时移动到其他位置。
- 304:未修改(Not Modified)- 表示客户端的缓存资源仍有效,可以直接使用缓存的内容。
4xx:客户端错误
- 400:错误请求(Bad Request)- 请求无效或不可理解。
- 401:未授权(Unauthorized)- 请求需要身份验证。
- 403 :不可访问(Forbidden)表⽰访问被拒绝.有的⻚⾯通常需要⽤⼾具有⼀定的权限才能访问(登陆后才能访问).如果⽤⼾没有登陆 直接访问,就容易⻅到403.
- 404:未找到(Not Found)- 请求的资源不存在。
5xx:服务器错误
- 500:服务器内部错误(Internal Server Error)- 服务器遇到了意外情况,无法完成请求。
- 503:服务不可用(Service Unavailable)- 服务器暂时无法处理请求,通常是因为过载或维护。
- 504:超时(GatewayTimeout) 当服务器负载⽐较⼤的时候,服务器处理单条请求的时候消耗的时间就会很⻓,就可能会导致出现超时 的情况.
以上只是一些常见的HTTP状态码,实际上HTTP协议定义了更多的状态码用于表示不同的情况。状态码对于调试和排查问题非常有帮助,客户端可以根据状态码来适当地处理响应结果。
2. 认识响应"报头"(header)
响应报头的基本格式和请求报头的格式基本⼀致.
类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义⼀致.
Content-Type:
响应中的Content-Type常⻅取值有以下⼏种:
text/html:表示响应正文是HTML格式的文本,通常用于网页内容的展示。text/css:表示响应正文是CSS格式的文本,通常用于网页样式的设置和控制。application/javascript:表示响应正文是JavaScript格式的文本,通常用于网页动态效果、事件处理等脚本编程。application/json:表示响应正文是JSON格式的文本,通常用于数据传输、交换等。
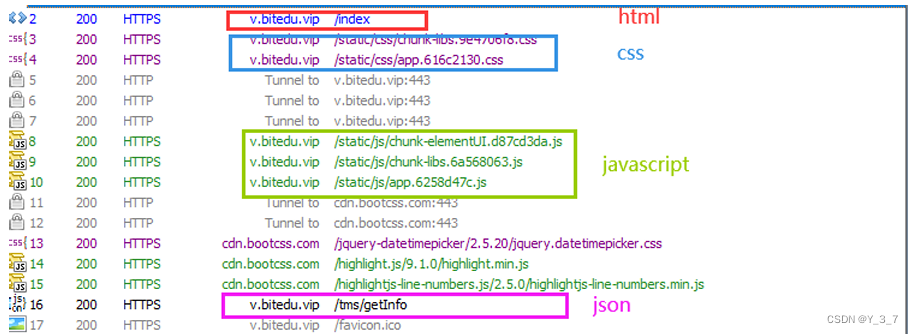
3. 认识响应"正⽂"(body)
正⽂的具体格式取决于Content-Type.
HTTP响应的"正文"(body)是指服务器返回给客户端的实际数据内容。正文通常包含了请求所需要的信息,如HTML、XML、JSON等文档格式、图片、音频、视频等二进制数据等等。
在HTTP响应中,正文通常跟随在响应头部分的后面,使用空行来分隔。响应头部分包含了HTTP协议版本、状态码、响应头字段等元数据信息,而正文则包含了具体的数据内容。例如,一个HTTP响应的格式通常如下所示:
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 1234
<!DOCTYPE html>
<html>
<head>
<title>Example Website</title>
<meta charset="utf-8">
</head>
<body>
<h1>Welcome to Example Website!</h1>
<p>This is an example website.</p>
</body>
</html>
上述例子中,响应头部分包含了HTTP协议版本、状态码和Content-Type等元数据信息,而正文部分则是一个HTML文档,包含了网页的标题、编码方式以及页面的内容等信息。
在对HTTP响应进行解析时,客户端需要读取并处理响应的正文部分,以获取服务器返回的具体数据内容。具体的处理方法依赖于正文的类型和格式,通常可以使用相应的解析库或者工具来处理。例如,在读取HTML文档时,可以使用浏览器或者其他HTML解析器来解析HTML文件,并将其中的内容渲染到用户界面上。
4. HTTP 从客户端到服务端发送从url到发送完成到底发生了什么
当从客户端通过 HTTP 从 URL 发起请求到发送完成的过程中,会发生一系列复杂且有序的操作,以下是详细介绍:
1. URL 解析:客户端输入 URL 后,浏览器首先对其进行解析。以
https://www.example.com:8080/path?query=value#fragment为例,会分离出协议(https)、域名(www.example.com)、端口号(8080,如果未指定则使用默认端口,如 HTTP 默认 80,HTTPS 默认 443)、路径(/path)、查询参数(query=value)和片段标识符(fragment)。其中,片段标识符不会发送到服务器,仅用于在页面内部定位。2. DNS 域名解析:浏览器需要知道目标服务器的 IP 地址才能与其通信,因此会发起 DNS 查询。首先会检查浏览器自身的 DNS 缓存,如果有对应的 IP 记录则直接使用;若没有,则向操作系统的 DNS 缓存查询。若仍未找到,会向本地 DNS 服务器(通常是网络服务提供商提供的)发起查询。本地 DNS 服务器可能会递归地向其他 DNS 服务器(如根 DNS 服务器、顶级域名 DNS 服务器、权威 DNS 服务器等)查询,最终获取到域名对应的 IP 地址,并将结果返回给浏览器。
3. 建立 TCP 连接:得到服务器的 IP 地址后,客户端使用 TCP 协议与服务器建立连接。这一过程通过三次握手来实现:
- 客户端向服务器发送一个 SYN(同步)包,其中包含客户端的初始序列号(例如 x),表示客户端请求建立连接。
- 服务器收到 SYN 包后,回复一个 SYN-ACK(同步确认)包,包含服务器的初始序列号(例如 y),并确认客户端的序列号(x + 1)。
- 客户端收到 SYN-ACK 包后,再发送一个 ACK(确认)包,确认服务器的序列号(y + 1),至此 TCP 连接建立成功。
4. 构建 HTTP 请求:在 TCP 连接建立后,客户端开始构建 HTTP 请求消息。请求消息由请求行、请求头和请求体(对于 GET 请求,请求体通常为空;对于 POST 等请求,请求体包含发送的数据)组成。例如:
GET /path?query=value HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Connection: keep-alive5. 发送 HTTP 请求:将构建好的 HTTP 请求消息通过建立好的 TCP 连接发送到服务器。数据在网络中会被分割成多个数据包进行传输,并通过 IP 协议进行路由,最终到达服务器。
6. 服务器处理请求:服务器接收到 HTTP 请求后,会对请求进行解析。首先解析请求行,确定请求的方法(如 GET、POST 等)、请求的资源路径等;然后解析请求头,获取客户端的各种信息(如 User-Agent、Accept 等)。根据请求的内容,服务器会进行相应的处理,如查询数据库、调用业务逻辑等,生成响应数据。
7. 构建 HTTP 响应:服务器构建 HTTP 响应消息,由状态行、响应头和响应体组成。状态行包含 HTTP 协议版本、状态码(如 200 表示成功,404 表示未找到资源等)和状态描述。响应头包含关于响应的元信息,如 Content-Type(指示响应体的内容类型,如 text/html、application/json 等)、Content-Length(响应体的长度)等。响应体则包含服务器返回给客户端的数据,如 HTML 页面内容、JSON 数据等。例如:
HTTP/1.1 200 OK Content-Type: text/html Content-Length: 1234 Server: Apache/2.4.41 (Ubuntu) Connection: keep-alive <!DOCTYPE html> <html> <body> ...(页面内容) </body> </html>8. 发送 HTTP 响应:服务器将构建好的 HTTP 响应消息通过 TCP 连接发送回客户端。同样,数据会被分割成数据包在网络中传输。
9. 客户端接收响应:客户端接收服务器发送的 HTTP 响应数据包,并进行重组。然后解析响应消息,首先读取状态行,判断请求是否成功;接着读取响应头,获取相关信息;最后读取响应体,根据 Content-Type 来处理响应数据,如在浏览器中渲染 HTML 页面、解析 JSON 数据等。
10. 关闭 TCP 连接:在完成数据传输后,客户端和服务器可以选择关闭 TCP 连接。这通常通过四次挥手来实现:
- 客户端发送一个 FIN(结束)包,表示客户端不再发送数据。
- 服务器收到 FIN 包后,回复一个 ACK 包,确认收到客户端的 FIN 包。
- 服务器处理完剩余数据后,发送一个 FIN 包,表示服务器也不再发送数据。
- 客户端收到服务器的 FIN 包后,回复一个 ACK 包,确认收到服务器的 FIN 包,至此 TCP 连接关闭。
以上就是从客户端输入 URL 到 HTTP 请求发送完成并接收响应的整个过程。
总结
HTTP(Hypertext Transfer Protocol)是一种应用层协议,用于在Web浏览器和Web服务器之间传输数据。HTTP请求和响应是HTTP协议中最基本的消息类型。
HTTP请求包含以下内容:
- 请求行:包括HTTP方法(GET,POST等)、请求URI和HTTP版本号;
- 请求头部:包括一系列关于请求的元数据,如Host、User-Agent、Accept等;
- 空行:请求头部和请求正文之间需要空一行;
- 请求正文(可选):包含请求提交的数据,如表单数据、文件等。
HTTP响应包含以下内容:
- 状态行:包括HTTP版本、响应状态码和对应的状态消息;
- 响应头部:包括一系列关于响应的元数据,如Content-Type、Content-Length、Server等;
- 空行:响应头部和响应正文之间需要空一行;
- 响应正文:包含响应的数据,如HTML、XML、JSON等文档格式、图片、音频、视频等二进制数据等等。
HTTP请求和响应之间通过网络传输,使用TCP/IP协议来传输数据。HTTP是无状态的协议,也就是每个HTTP请求都是独立的,与之前或之后的请求没有关联。为了实现状态保持,HTTP引入了cookie和session等机制来帮助Web应用程序管理客户端的状态信息。
总之,HTTP请求和响应是HTTP协议中最基本的消息类型,它们用于在Web浏览器和Web服务器之间传输数据,是Web应用程序的基石。
以上就是本文的所有内容,肝到凌晨 2 点,呼呼,辛苦自己了。
博客不易,希望可以帮助到大伙,动动小手点个赞我会开心很久,感谢阅览。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









