







一:什么是爬虫?
爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
说简单点就是,你可以把网络爬虫想象成一个在网上自动行走的机器人,它能够阅读网页上的内容,并根据需要将这些内容保存下来。我们编写的程序就是其这个所谓的机器人。
二:爬虫有什么用处?
- 数据收集:爬虫访问网页,收集网页上的数据,比如文本、图片、链接等。
- 链接跟踪:爬虫会识别网页中的链接,并根据这些链接访问更多的网页,实现对整个网站的遍历。
- 数据存储:爬取的数据会被保存到数据库或其他存储系统中,供进一步分析和使用。
- 内容更新:定期运行爬虫,以更新存储的数据,保持信息的时效性。
然而,我们在使用网络爬虫时需要遵守网站的robots.txt文件规定,尊重版权和隐私政策,避免对网站造成过大的访问压力。一定要做个遵纪守法的好公民。
三:实战分析(获取获取网页价格为例)
一:了解html网页的结构
我们想抓取网页中的内容,就不得不对网页有一个初步的了解。下面来简单介绍以下网页结构。
随机打开一个网页(以csdn社区为例),右键鼠标,可以看到一个检查
点击打开,可以看到一堆代码,这就是HTML(HyperText Markup Language,超文本标记语言)是构建网页和网页应用的标准标记语言。
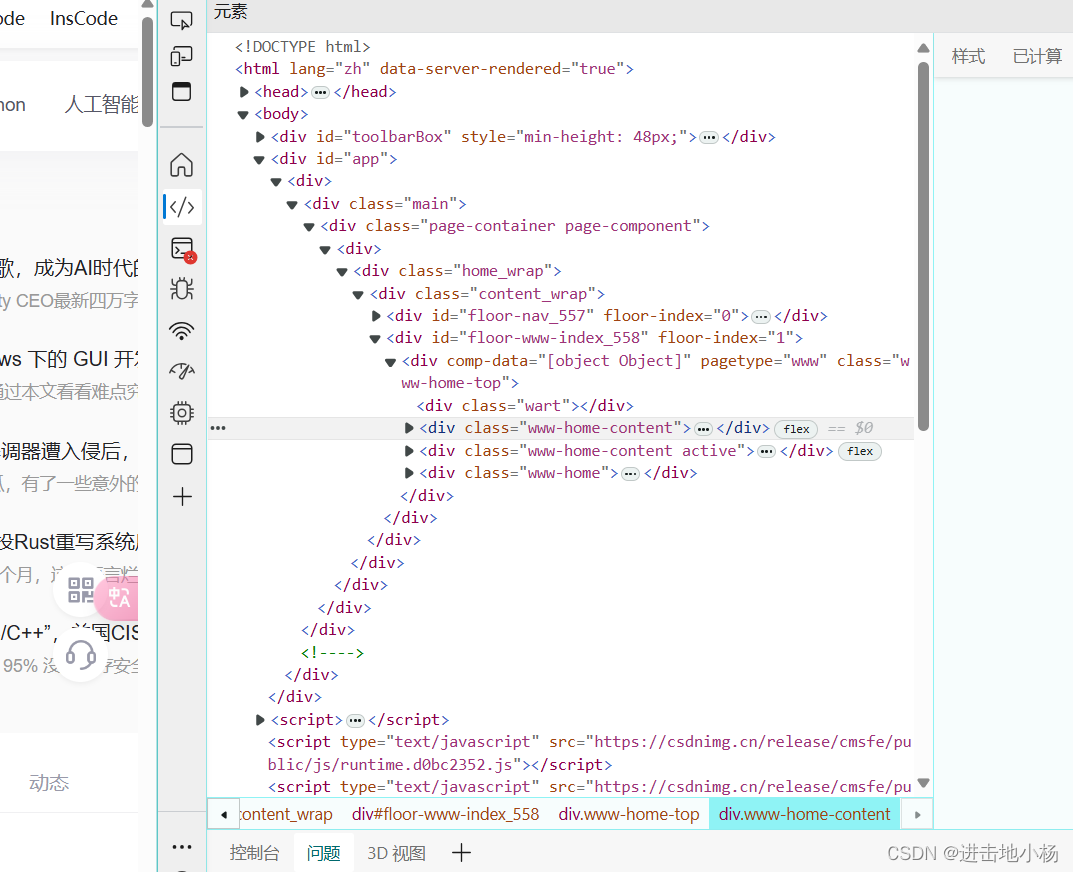
一个典型的HTML网页由以下基本结构组成:
-
文档类型声明(DOCTYPE):告诉浏览器该文档是HTML5文档。通常写为
<!DOCTYPE html>。 -
<html>元素:是HTML文档的根元素,包含了所有的HTML代码。 -
<head>元素:包含了文档的元数据,比如标题(<title>)、字符集声明(<meta charset="UTF-8">)、CSS链接、JavaScript文件链接等。这些信息通常对用户不可见。<title>:定义文档的标题,显示在浏览器的标签页上。
-
<body>元素:包含了可见的页面内容,比如文本、图片、链接、表格、列表等。- 文本内容:使用
<p>(段落)、<h1>到<h6>(标题)等标签定义。 - 图片:使用
<img>标签,需要指定源文件(src属性)。 - 链接:使用
<a>标签,通过href属性指定链接地址。 - 列表:有序列表(
<ol>)和无序列表(<ul>),列表项使用<li>。 - 表格:使用
<table>、<tr>(行)、<td>(单元格)等标签定义表格结构。
- 文本内容:使用
-
语义化标签:HTML5引入了一系列新的语义化标签,如
<header>、<nav>、<section>、<article>、<aside>、<footer>等,这些标签帮助定义网页的不同部分,提高内容的可读性和SEO(搜索引擎优化)效果。 -
表单:使用
<form>元素创建,包含输入字段(如<input>、<textarea>)、按钮(<button>)等。 -
脚本:
<script>标签用于引入JavaScript代码,可以是内联脚本或外部JavaScript文件。 -
样式:可以通过
<style>标签内联CSS样式,或通过<link>标签链接外部CSS文件。
我们可以简单理解为
网页结构可以类比为一本书的结构,这样更容易理解:
-
封面(
<!DOCTYPE html>):就像书的封面一样,告诉读者和浏览器这是一本HTML书。 -
书脊(
<html>):书的外壳,包含整本书的所有内容。 -
目录(
<head>):书的目录页,列出了书的基本信息和一些对读者不直接展示的内容,比如书的标题(<title>),使用的字体和样式(相当于CSS),以及一些脚本(相当于JavaScript)。 -
正文(
<body>):书的主体部分,读者阅读的主要部分。在网页中,这里包含了所有用户可以看到的内容,比如文字、图片、链接等。 -
章节标题(
<header>,<section>,<article>,<footer>):就像书的章节标题一样,帮助读者快速了解网页的各个部分。<header>通常是网页的头部,包含网站的logo和导航菜单;<section>、<article>、<aside>等则可以代表不同的内容区块;<footer>是网页的底部,通常包含版权信息和联系方式。 -
段落和标题(
<p>,<h1>-<h6>):就像书中的段落和不同级别的标题,帮助组织和突出显示文本内容。 -
图片和图表(
<img>):就像书中的插图,增强了内容的表现力。 -
链接(
<a>):就像书中的引用或脚注,可以链接到其他页面或网站。 -
列表(
<ul>,<ol>,<li>):就像书中的列表,用于组织一系列相关的项目。 -
表格(
<table>,<tr>,<td>):就像书中的表格,用于展示数据和信息的矩阵。 -
表单(
<form>):就像书中的调查问卷,允许用户输入信息并提交。 -
脚本和样式(
<script>,<style>):就像书的附录,包含了一些额外的代码,用于控制网页的行为和外观。
我们需要的所有数据都储存在这本”书”的内容,这样我们就要编写程序来读出来这本书。
二:介绍需要用到的两python个库及基础操作
1:request库
我们在pycharm下面的终端(执行系统命令和脚本的窗口)中执行下面红色框内的代码来安装requests库。等待片刻后,如果显示为下面两种情况均可以证明其安装成功。


requests库的作用:允许你向网络上的服务器发送GET、POST、PUT、DELETE等HTTP请求,即向网站发送访问申请。

第一步(获得网页内容):
新建一个python文件,输入上述代码,可以看出我们是申请访问
https://books.toscrape.com/该网站为爬虫测试网站,其中
response:这是requests.get函数返回的响应对象,它包含了服务器响应的所有信息。
response.status_code:这将打印出HTTP状态码。对于一个成功的请求,状态码通常是200。
response.text:这将打印出服务器响应的文本内容。运行后得到:
显然状态码为200,说明程序运行成功。此时我们已经获得网页里面的内容,成功完成第一步。
2:BeautifulSoup库
作用:可以从HTML或XML文件中提取数据的Python库,即把我们获得的网页内容进行解析。
安装步骤同上,这里不再赘述。
第二部:解析网页
使用教程:
 将获取的网页内容赋值给context,然后该库对此内容进行解析,因为BeautifulSoup可以对很多类型的网页进行介绍,故在此后面需要添加"html.parser"。将该内容解析为类似下面的结构:
将获取的网页内容赋值给context,然后该库对此内容进行解析,因为BeautifulSoup可以对很多类型的网页进行介绍,故在此后面需要添加"html.parser"。将该内容解析为类似下面的结构:
显然网页被分为了很多部分,因此只需要找到目标数据的所属结构,就可以提取出相关数据。
例:在上面代码中
print(soup.p)
表示将第一个p元素的全部内容打印下来。
现在我们的目标是找到这个网页 https://books.toscrape.com/的所有书名和价格。

在网页检查页,可以发现其价格元素<p class="price_color">£53.74</p>,发现价格都在p元素内,为了避免其他含有p元素出现,我们接着利用其他特点,比如此价格元素中,所有class的属性都为"price_color"。所以我们的目标变为找出所有class属性为“price_color”的p标签。

findall:根据标签,属性等找出所有符合条件的元素。再利用for循环将所有元素打印出来,即可得到所有价格标签。另外,我们只想要里面的价格信息,这里再对程序进行稍加改进,
对元素进行切割和提取,就能轻松得到价格数据。到这里我们看到,爬虫技能需要我们随机应变,才能准确提取相关的信息。
三:实战篇(提取top250电影名)
一:绕开防爬虫系统
由于很多网页都是限制爬虫程序访问的(因为防止服务器过载),所以我们需要假装为”用户“来骗取服务器进行访问。操作如下:
import requests
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
response = requests.get("https://movie.douban.com/",headers=headers).text
print(response)
定义一个字典类型,对“User-Agent”进行赋值
红色部分就是帮助我们伪装为游览器的代码,那么我们该如何获取呢?打开任意网页,右键-检查-点击任意项目,点击network或者如图标准,往下划找到User-Agent后面部分

此时可以轻松绕开防爬虫系统。
二:观察数据所在元素特点

可以看出均为span标签,且class属性为“title”。
三:运行程序
import requests
from bs4 import BeautifulSoup
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
html = requests.get("https://movie.douban.com/top250/",headers=headers).text
soup = BeautifulSoup(html,"html.parser")
all_titles = soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
title_string =title.string
if "/" not in title_string:
print(title_string)
运行以上代码

即可得到这一页的所有电影名称,但是我们需要的top250,那么我们需要对网页进行for循环了,


我们观测前后两页的网址可以发现,只有start后面的数字有所改变,因此我们定义一个变量start—num,可以取0,25,50.....250,使用for循环结合range语句。此时我们进行更新一下网址链接。
import requests
from bs4 import BeautifulSoup
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
for start_num in range(0,250,25):
response = requests.get(f"https://movie.douban.com/top250?start={start_num}",headers =headers)
html = response.text
soup = BeautifulSoup(html,"html.parser")
all_titles = soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
title_string =title.string
if "/" not in title_string:
print(title_string)
此时可以得到top250电影名称的全部数据。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









