







目录
1、Map的三个实例化:HashMap类、LinkedHashMap类和TreeMap类
上一篇学习了集合Collection接口中的List接口(线性表)和Queue接口(队列),接下来学习剩下一个接口:规则集Set接口还有和他很相像的Map接口。
一、规则集:Set接口
规则集set用于存储和处理无重复元素。Set接口扩展了Collection接口,设限实例中不能出现重复元素。
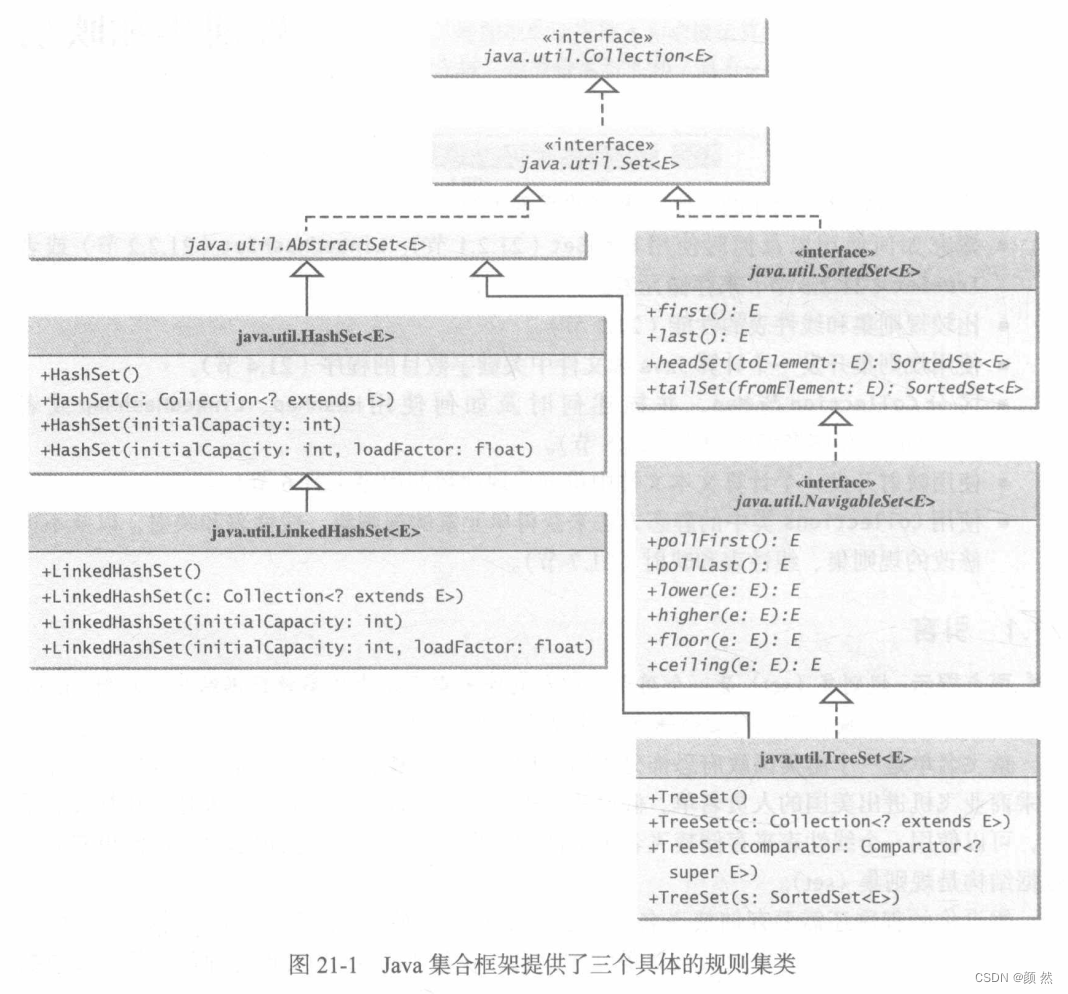
实例化Set接口的三个具体类是:HashSet(散列式)、LinkedHashSet(链式散列集)、TreeSet(树形集):
1、散列式:HashSet类
下面创建一个散列集存储字符串:
public class TestHashSet {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("LLLondon");
set.add("BBBBBondon");
set.add("LLLondon");
set.add("Aaa");
set.add("Ring");
System.out.println(set);
for(String s : set) {
System.out.print(s.toUpperCase() + " ");
}
System.out.println();
set.forEach(e -> System.out.print(e.toLowerCase() + " "));
}
}
/*
[Aaa, Ring, LLLondon, BBBBBondon]
AAA RING LLLONDON BBBBBONDON
aaa ring lllondon bbbbbondon
*/字符串LLLondon被添加多次,但最终存储到集合中的只有一个,因为规则集中不允许重复元素出现;其次是发现字符串没有按照添加时的顺序排列,因为散列集中的元素没有特定的顺序。
因为规则集是Collection接口的实例,所以所有定义在Collection中的方法都可以用在规则集上。
2、链式散列集:LinkedHashSet类
上面的HashSet类中的元素没有顺序,如果想要顺序排列元素,则可以使用LinkedHashSet类,它用一个链表实现来扩展HashSet类,元素可以按照它们插入规则集的顺序来获取。
用法和HashSet用法一样,创造一个LinkedHashSet对象:
Set<String> set = new LinkedHashSet<>();3、树形集:TreeSet类
ShortedSet是Set接口的一个子接口,确保规则集元素是有序的同时,提供方法first()和last()来返回第一个或最后一个元素;headSet(E)和tailSet(E)分别返回规则集小于或大于E的那一部分。
NavigableSet扩展了ShortedSet接口,在原本的基础上提供lower(E)(<)、floor(E)(<=)、ceiling(E)(>=)、higher(E)(>)方法返回指定大或小的一个元素;pollFirst()和pollLast()分别删除并返回树形集的第一个和最后一个元素。
4、比较:线性表和规则集
线性表可通过索引来访问元素,而规则集是无序的,因此不支持索引。

二、映射:Map接口
映射map存储 <“键或值”的集合> 。键很像索引,只不过在Map中,键也可以是对象。
一个键对应一个值,一个键+一个值=一个条目,映射是条目集。不能有重复的键,所以使用规则集存储键集。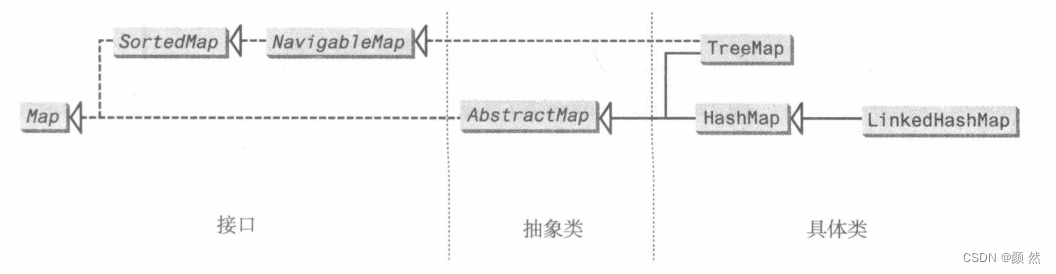
Map接口包含了查询、更新和获取的方法:

其中Map接口中还有个内部接口:Entry接口。Map接口中的entrySet方法返回包含所有条目的规则集,而这些条目就是Map.Entry<K,V>接口的实例。Entry接口中包含对键值的操作:

1、Map的三个实例化:HashMap类、LinkedHashMap类和TreeMap类
实例化Map接口的三个具体类是:HashMap(散列映射)、LinkedHashMap(链式散列映射)、TreeMap(树形映射):
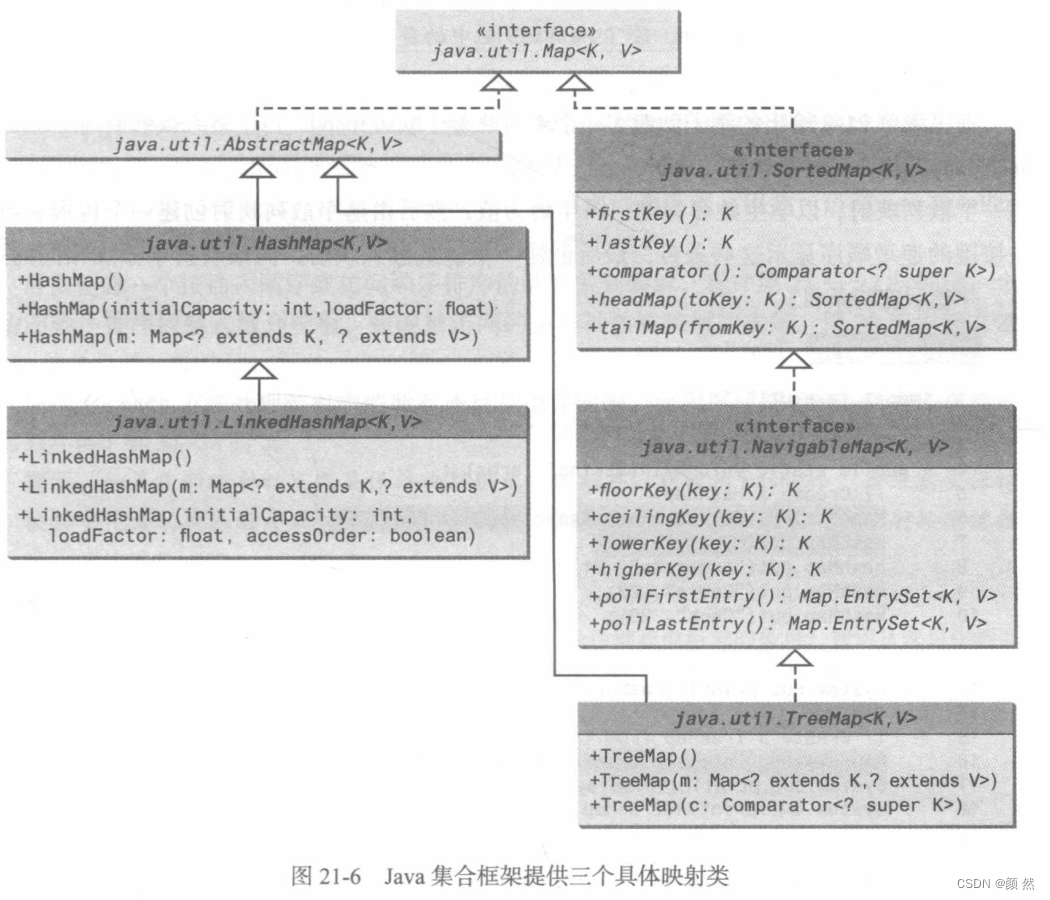
和规则集很类似,HashMap对于定位一个值、删除或插入一个条目时是最高效的,但它是个无序集合。
需要对条目排序时,LinkedHashMap使用链表扩展HashMap,实现条目排序。
TreeMap类在遍历排好的键(键使用Comparable接口或Comparator接口实现排序)时是高效的。
其中TreeMap接口继承自NavigableMap接口,而NavigableMap接口继承自SortedMap接口。TreeMap的父类和爷类提供了对键和条目的操作。
2、实例操作:统计单词出现次数
public class CountOccurrenceOfWords {
public static void main(String[] args){
String text = "Good morning.Have a good Day" + "Have fun!";
Map<String, Integer> map = new TreeMap<>();
String[] words = text.split("[\\s+\\p{P}]");
for(int i = 0; i < words.length; i++){
String key = words[i].toLowerCase();
if(key.length() > 0 ){
if(!map.containsKey(key)){ //检测单词是否已经作为键存在
map.put(key,1); //如果没有,就将单词和初始统计次数(1)构成一个新条目存储到映射中
}else { //如果有,给单词的计数器+1
int value = map.get(key);
value ++;
map.put(key,value);
}
}
}
//按照出现次数递增顺序显示单词
List<Map.Entry<String, Integer>> entries = new ArrayList<>(map.entrySet());
//sort方法排序
Collections.sort(entries, (entry1,entry2) -> {
return entry1.getValue().compareTo(entry2.getValue());
});
for(Map.Entry<String,Integer> entry:entries){ //输出
System.out.println(entry.getKey() + "\t" + entry.getValue());
}
}
}
/*
a 1
dayhave 1
fun 1
have 1
morning 1
good 2
*/程序使用String类中的方法split分隔字符串,将单词存储到数组words中,然后用toLowerCase方法变小写(统一)。程序中将单词作为条目的键存储,然后进行判断。接下来创建一个线性表,按照出现次数递增顺序显示单词。
使用映射真的能大幅度地减少代码量。如果不使用映射,代码估计翻倍。映射,牛。
















 1372
1372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











