







 本文介绍了顺序查找和二分查找两种搜索算法。顺序查找适用于无序列表,平均查找复杂度为O(n),而二分查找则利用有序列表特性,查找复杂度为O(logn)。二分查找通过不断缩小查找范围实现高效查找,适合大型有序数据集。对于数据项不存在的情况,有序表的顺序查找能节省一些比较次数。
本文介绍了顺序查找和二分查找两种搜索算法。顺序查找适用于无序列表,平均查找复杂度为O(n),而二分查找则利用有序列表特性,查找复杂度为O(logn)。二分查找通过不断缩小查找范围实现高效查找,适合大型有序数据集。对于数据项不存在的情况,有序表的顺序查找能节省一些比较次数。
1. 顺序查找
查找有顺序查找Sequential Search、二分查找Binary Search等查找方法。在Python中,用下标查找数据项的技术,是顺序查找。
1.1 定义
顺序查找是从列表中的第一个数据项开始。按照下标增长的顺序,逐个比对数据项,如果到最后一个都未发现要查找的项,那么查找失败。

1.2 代码
def sequentialSearch(thelist, item):
i = 0
found = False
pos = 0
while i < len(thelist) and found == False:
if thelist[i] == item:
found = True
pos = i
else:
i = i + 1
if found:
return pos
else:
return False
print(sequentialSearch([1, 2, 3, 4], 2)) # 1
print(sequentialSearch([1, 2, 3, 4], 4)) # 3
print(sequentialSearch([1, 2, 3, 4], 5)) # False
1.3 算法分析
算法复杂度是O(n)
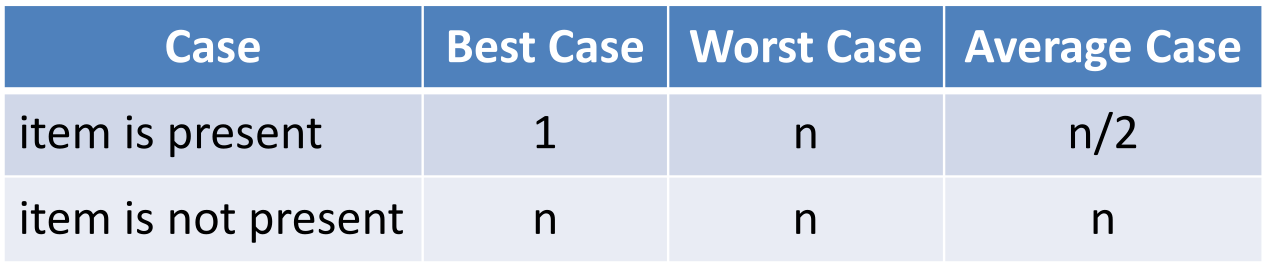
1.4 有序表的顺序查找
当数据项存在时,查找有序表和无序表的方法完全相同。但是当数据项不在表中时,有序表可以提前结束。
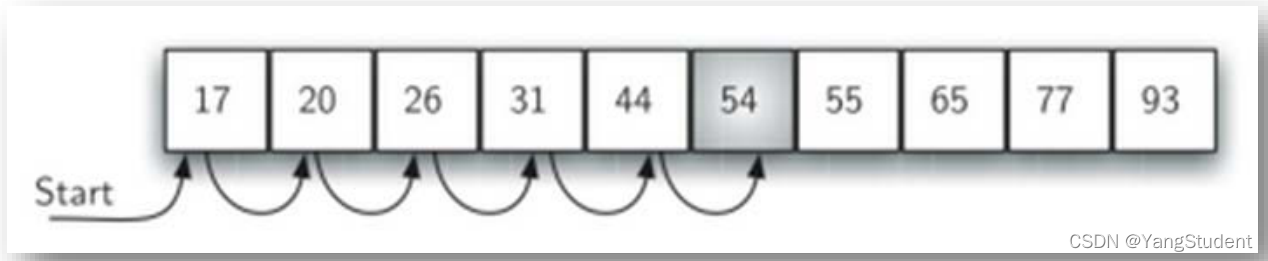
查找数据项50,当看到54时,可知道后面不可能存在50,可以提前退出查找。
def sequentialSearch(thelist, item):
found = False
stop = False
i = 0
while i < len(thelist) and not found and not stop:
if thelist[i] != item:
i = i + 1
elif thelist[i] > item:
stop = True
else:
found = True
return found
print(sequentialSearch([1, 3, 5, 7], 4)) # False
print(sequentialSearch([1, 3, 5, 7], 5)) # True
print(sequentialSearch([1, 3, 5, 7], 8)) # False
算法复杂度仍然是O(n), 只是在数据项不存在的时候,有序表的查找能节省一些比对次数,但并不改变其数量级。
2. 二分查找(折半查找)法
2.1 定义
二分法利用有序表的特性,缩小待比对数据项的范围。从列表中间开始比对,如果列表中间的项匹配查找项,则查找结束如果不匹配,那么就有两种情况:
- 列表查找项比中间项小,那么查找项只可能出现在前半部分
- 列表查找项比中间项大,那么查找项只可能出现在后半部分
无论如何,我们都会将比对范围缩小到原来的一半:n/2
继续采用上面的方法查找,每次都会将比对范围缩小一半
2.2 代码
def binarySearch(thelist, item):
found = False
first = 0
last = len(thelist) - 1
position = 0
while first <= last and not found:
midpoint = (first + last) // 2 # // 是除法取整数
if item > thelist[midpoint]:
first = midpoint + 1
elif item < thelist[midpoint]:
last = midpoint - 1
elif item == thelist[midpoint]:
found = True
position = midpoint
if found == True:
return position
else:
return False
print(binarySearch([1, 3, 5, 7, 9], 5))
print(binarySearch([1, 3, 5, 7, 9], 2))
print(binarySearch([1, 3, 5, 7, 9], 7))
print(binarySearch([1, 3, 5, 7, 9], 3))
print(binarySearch([1, 3, 5, 7, 9], 8))
2.3 分而治之,递归解法
二分查找算法实际上体现了解决问题的典型策略:分而治之
- 将问题分为若干更小规模的部分
- 通过解决每一个小规模部分问题,并将结果汇总得到原问题的解
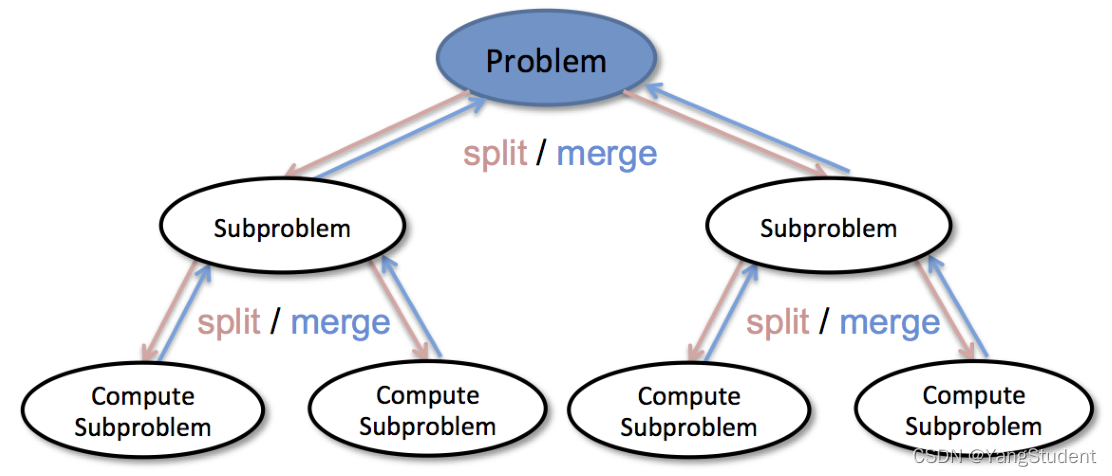
递归算法求解:
def binary_search(the_list, item):
mid = len(the_list) // 2
if the_list[mid] == item:
return mid
# 基本结束条件
if the_list[mid] > item:
return binary_search(the_list[0: mid], item)
if the_list[mid] < item:
return mid + binary_search(the_list[mid:], item)
# 向小规模前进
# 调用自身
print(binary_search([1, 3, 5, 7, 9], 1))
print(binary_search([1, 3, 5, 7, 9], 3))
print(binary_search([1, 3, 5, 7, 9], 5))
2.4 算法分析
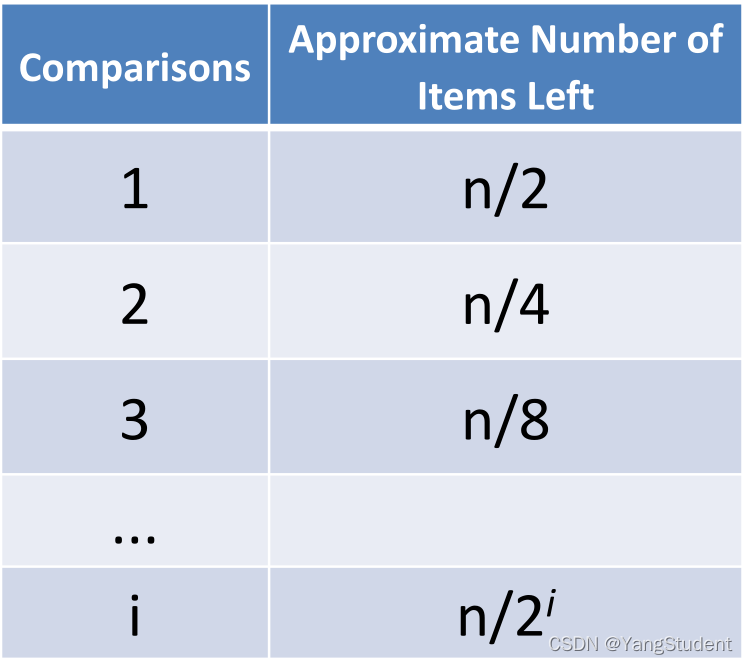
由于二分查找,每次比对都将下一步的比对范围缩小一半
每次比对后剩余数据项如下表所示:
另外,虽然二分查找在时间复杂度上优于顺序查找,但也要考虑到对数据项进行排序的开销。换句话说,二分查找需要先排序,会更麻烦一点。
参考文献
本文的知识来源于B站视频 【慕课+课堂实录】数据结构与算法Python版-北京大学-陈斌-字幕校对-【完结!】,是对陈斌老师课程的复习总结。

















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









