







腾讯2017社交广告比赛
https://blog.csdn.net/songbinxu/article/details/79628443
https://github.com/Dojocat-GO/Tencent2017_Final_Rank28_code 28名代码
决赛第7名
比赛中,我们比较关心的一个问题在于:数据线上线下分布不一致:1、某些app和用户的记录比较少;2、数据的时效性要求较高。这对于特征工程会是一个比较大的要求,在比赛中有许多的特征会使得线上的成绩下降,比如各种差分的特征。
特征工程
特征的提取主要有以下几个方面:
- 基础特征:计数特征、转化率、比例特征等各种基本的特征;
- 线上的特征:基于当天数据统计的用户行为、app行为的特征;
- 用户行为挖掘特征:word2vec计算用户行为与历史行为的关联;
特征提取方式有以下几个方面考虑:
- 基于cv统计、贝叶斯平滑等方法,能够很好的修正线上线下的特征分布不一致的问题;
- 特征提取主要有基于全局的数据统计以及滑窗的历史统计。
- 基于全集的数据统计生成的特征:是决赛中主要的特征提取方式,效果比较平稳,而且信息量比较多,但容易会有信息泄露的问题需要通过cv统计来避免,而且难以反映时间变化的信息。
- 基于滑窗的生成特征:能反映时序上的信息,不会有信息泄露的问题。但是生成的特征数量多,线上线下的分布差异比较大,特征工程方面的工作量比较大。
因此,比赛中我选择了两种生成特征的方式来产生不同的模型进行融合。
特征选择
- 在初赛阶段,主要有以下三种方式来筛选特征:1、删除线上线下均值差异30%以上的特征;2、通过xgboost计算的特征重要性,删除重要性较低的特征;3、通过wrapper的方式选择特征。通过以上方式能够保证线上线下的特征稳定,但这工作在决赛数据量大的情况下会比较耗时。
- 在决赛阶段,每加入一部分特征,通过线上的成绩反馈来选择特征的去留。
模型方法
比赛中主要使用stacking 的方式,其中一个模块的示意图如下:
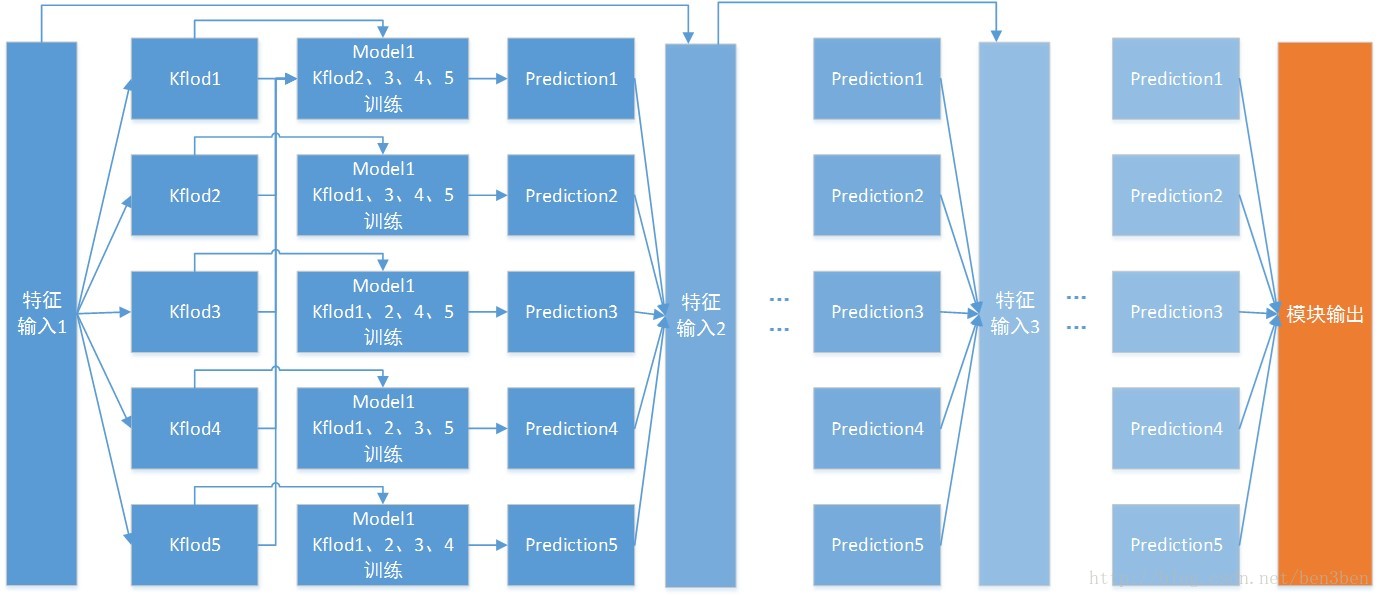
如图所示,模块中使用cv的方法,把数据分成5份来进行训练和预测,这样模型的效果会比单模型的要好些(相当于投票的一种策略)。此外模块中stack3层,每一层使用原有的特征和预测值作为下一个模型的输入,增强模块的精度。模型中使用xgboost和lightgbm。
这种模型的缺点在于,效率是单模型的十几倍,因此需要一种策略来保证效率。这里我使用分而治之的思想,每一次训练使用上一个模块的预测值和当前新提取的特征,作为下一个模块的输入进行训练,不断迭代。这样相当于把所有的特征分成很多部分分开训练,并且在决赛中通过线上成绩反馈来选择特征的去留。最终模型的流水线如下:
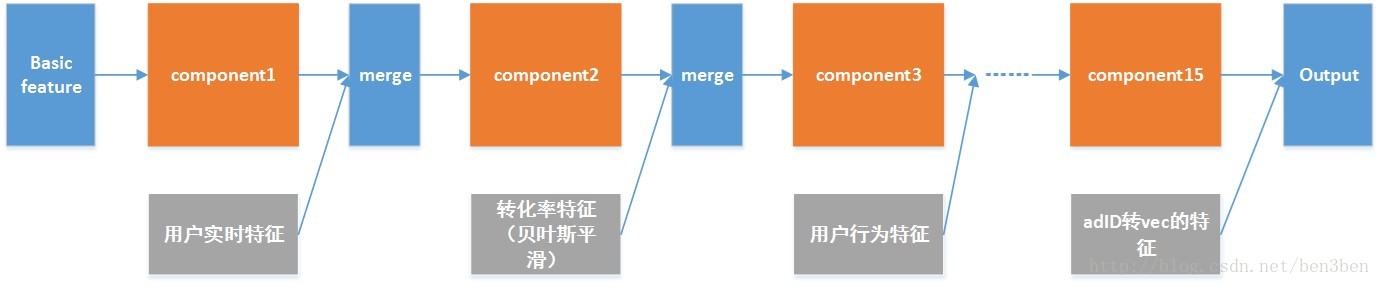
Component就是模型的一个模块(cv5份和stack3层的模块),每次提取新的特征则加入到新的component中训练。这里流水线中使用了15个模块。
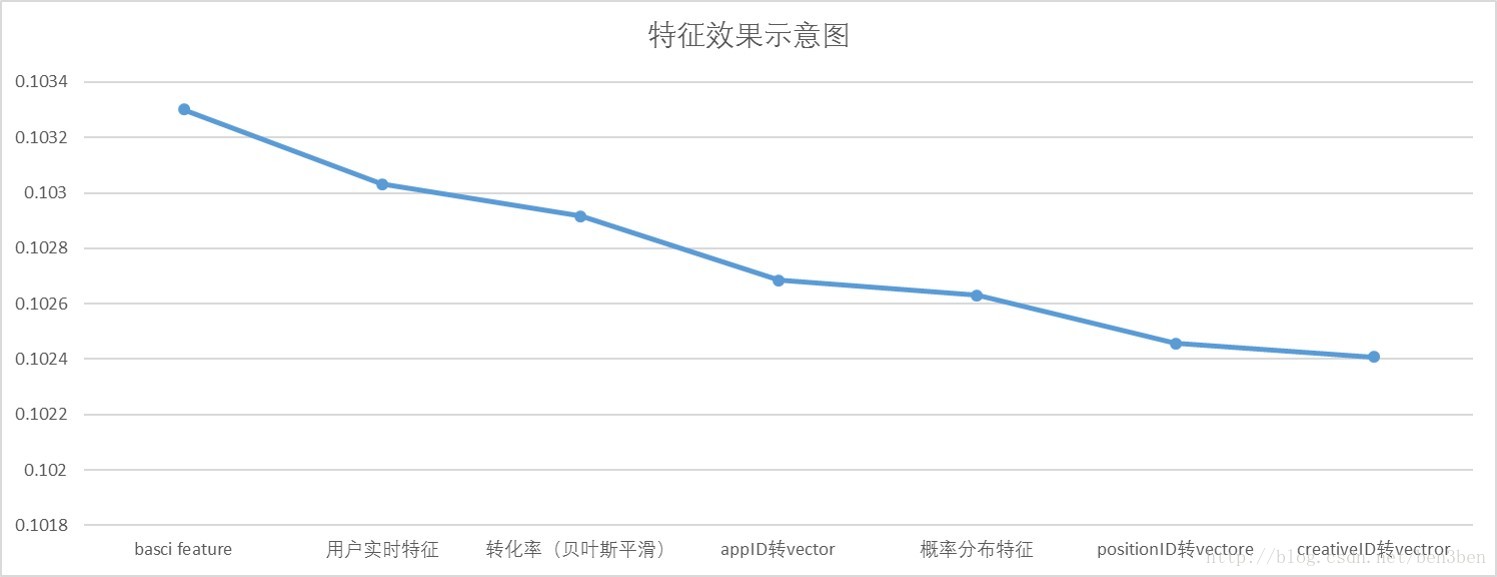
实验中,随着加入的特征越多,模型效果变得更好。模型的效果如下:
模型融合
主要有两种融合的方式:
- 加权融合:当融合的模型效果差异大时,根据线上的成绩人工设定融合的权重;
- logistic平均:当融合的模型效果差异小时,采用以下公式进行融合:p=f(∑if−1(pi)n)p=f(∑if−1(pi)n)
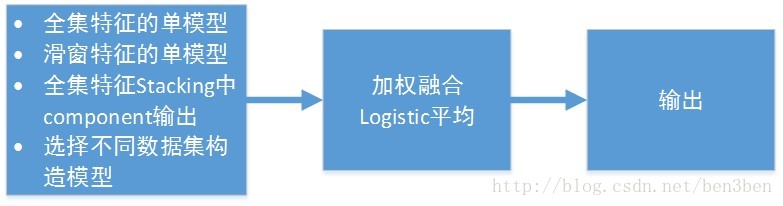
除了stacking的模型,同时也考虑全集和滑窗特征上的单模型效果,还有每个component成绩,进行融合:
赛后总结
个人感觉在模型的stack方面,已经做到了很好的程度,实验的结果表明比单模型的效果要好且鲁棒性更高。但是决赛后期尝试使用ffm算法,但是效果一直不理想,所以只是稍微的加进去原来的模型中进行融合。
特征的选择
关于特征选择,其中有两个方面是应该值得关注的。
一方面是特征的重要性,特征的重要性反映的是特征对模型效果的影响程度,理论上重要性越高的特征应该保留下来,而重要性较低的会考虑删除。特征越多,会使得模型越复杂,减少不必要的特征会使得模型更加稳定。其中常用的方法可以考虑xgboost中计算的特征重要性,或者是通过扰乱某个特征值的次序根据模型效果变化来得出。特征重要性计算的方法不少,大家可以再网上查找一下。
另一方面是特征分布是否一致,特征分布主要考虑的是线上和线下的分布差异。由于这次比赛的数据具有时序性,并且很多选手也因为在提取特征时因为信息泄露的原因导致线下成绩提升而线上成绩降低,这些问题都可以通过特征值的分布差异来排除掉,当分布不一致的特征,我们应该优先删除。特征分布差异,简单的可以通过线下和线上特征值的均值、标准差差异来考虑,或者基于其它的统计学的方法。
通过特征的重要性和分布综合考虑,应该就可以得到比较理想的特征效果了。
特征生成
关于特征生成,大体上可以分为两个大方向。
一个方向就是俗称的“拍脑袋”,根据个人对于数据观测、题目理解等考虑,得出的一系列规则转化为特征。这样很容易就会产生一系列有用或者无用的特征(比如one-hot、各种的转化率、点击量等特征),其中很多的特征所代表的意义其实是重复的,比如对各种ID做转化率的特征,当特征数量越来越多后,提取这类的特征会显得毫无意义。所以应该多角度的来提取特征,使得特征之间形成互补。
一方面是通过其它模型的结果来生成各种特征,其中能否通过深度学习来产生新的特征?LDA来分析用户和app之间的关系?特征之间不断的组合能否产生比较好的特征?这需要通过对数据的理解,不断的尝试和分析。不过我的并不建议那么快的考虑用其它的模型来生成特征,毕竟这种方法生成的特征有时候并不能很好的理解,并且需要的工作量也比较大,有时候生成的特征也并不一定有效果。
模型的理解
群里面很多的同学知道该用哪个模型,但是并没有理解模型的原理,所以把很多的时间浪费在模型的选取和调参上。事实上,我们应该先对模型有个比较基础的了解,明白模型以及各个参数的原理,这样才能指引我们如果去生成模型适合使用的特征以及怎样去调参。比如,我选取的模型是xgboost,基本上我是没怎么使用one-hot的特征。
对于刚开始比赛来讲,模型应该是简单点比较好,这样主要为了方便特征的生成和选择。当特征方面的工作做到一定的程度上,则可以考虑更复杂的模型来提高效果了。
决赛23名 https://github.com/BladeCoda/Tencent2017_Final_Coda_Allegro
1.问题&思路分析
腾讯本次竞赛的题目为移动App广告转化率预估(pCVR,Predicted Conversion Rate)。以移动App广告为研究对象,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
那么从本质上看,这就是一个二分类问题(你的点击有没有转化,即true/false)。只不过由于转化这件事情几率实在是太过于低,比赛要求你给出的是转化的概率,但这其实很好办,很多的分类器在最后预测数据类别时其实就是用概率最大进行选择的。典型的代表就是各种神经网络分类器,最后总是会接个Softmax的全连接层,通过输出层概率取最大来进行预测。
那么简而言之,这就是个非常传统的机器学习任务了。我们可以把这个任务切割成如下的子任务
1.提取数据特征
2.选取合适的模型,训练模型
3.调参与特征筛选
4.融合
2.特征提取
挖掘出强特,trick就可以吊打后面那些死肛统计特征什么的玩家了。对于分类器而言,数据记录其实就是一个特征的集合,机器学习学习的就是特征的分布。如何用一个好的方法把原始数据表达成一组有代表意义的特征向量,这便是特征提取的任务,也是这个比赛占了大部分内容的地方。
提取了50多维特征。大致为一以下几个种类。
I.基础特征:顾名思义,就是基础给你的那个属性,比如广告位ID,用户ID,用户性别,年龄之类的。这些属性其实一定程度上就能够指导转化率的预测了(即让分类器学习这些属性对于是否转化的分布)。当然,这种特征练出来的只不过是baseline级别的玩意。初赛提交占板凳用的。
II.用户的统计特征:这是重中之重,转化与否都是看用户的意愿的,而提取用户相关的特征自然是非常重要的。这里我给出我提取的一些有效的特征:
1.基本统计:类似于用户的安装数量,点击数量。用户安装同类别APP的数量等等。
2.时序统计:用户点击广告之前的一些行为都这次点击是否转化是具有很强的指导意义的。统计点击时间(clicktime)之前的一些特征能够很好的提高预测效果。例如统计clicktime之前的用户点击量,app安装数量之类的种种。
III.trick:喜闻乐见的环节,由于网速之类的问题,用户可能在很短的时间类不断的点击一个同一个广告,利用这里连续的记录是很有效的。具体使用方法举个例子,对短时间类重复的点击记录编号(1,2,3....),记录当前点击与前一次点击,后一次点击的时间差,亦或者同统段时间内用户的点击量(如1分钟内)。
*这儿必须要提一点,那就是数据泄露问题,简而言之,就是你用了未来的数据预测当前的转化率,或者直接用了和label相关性很强的特征来训练模型。后者危险性极大,直接造成线下结果超神,线上GG.很好理解,你等于用了答案在做题目-_-||||。但是前者就有意思了,理论上,实际业务你是无法提取这种特征的,但是,这是比赛,你懂得。用户是否重复点击,与后一条记录的时间差,这都是未卜先知的操作,而且这些泄露特征也是有风险的。具体自行操作感受。
IV.平滑后的转化率:你可能会想:我要预测转化率,那我用以前的转化率当特征不就OK了,你对了。但是,不全对。举个例子,统计同一广告位APP的历史转化率。由于广告位上线有前后,上线慢的统计不充分,最后特征基本就没用了。用户历史转化率就更危险了。大多数用户只点击过APP一次,历史转化率就是100%,你拿这个训练其实就是用了label来训练模型(就是前面我说的数据泄露的后者)。那种肿么办?
用先验知识来给转化率设置一个初值啊。
初值咋来?这个就涉及贝叶斯平滑啦。这个讲起来可以直接再开一个博客了。给大家一点资料:http://blog.csdn.net/mytestmy/article/details/19088519
总结一下,就是
假设一,所有的广告有一个自身的转化率,这些转化率服从一个Beta分布。
假设二,对于某一广告,给定转化次数时和它自身的转化率,它的点击次数服从一个伯努利分布
然后用梯度下降来学习这个分布。
3.训练集构造&分类器选择
有了特征,然后就是分类器的选取和训练数据集的构造问题了。决赛数据大概有10G左右,小破本根本就玩不了。
数据是按时间划分的(17-30天为训练集,31天为预测集)。我们其实只需要选取28,29就足够了。为何不选30,是因为30天数据统计有误差(官方说法,为了题目更真实)但是我用了第30天的数据并且得到了提高。第30天其实是非常重要的一天,因为广告具有很强的实效性,第30天是和第31天隔得最近的。它最能捕获31天的趋势,尽管不精确,但是30天究竟能不能用这和你的特征有关。我个人测试的结果(不保证正确):如果大量使用统计特征,请不要用第30天来训练。
线下测试cross validation就够了,但是有人会转牛角尖,用cv,会造成使用未来的数据预测以前的数据啊。对此我想说--你trick都用了,还怕这个?。这还是和特征有关,至少我和一些同学用CV能保证大体线上线下同步。当然,你也可以用27,28,来训练,29来验证。这个保险,初赛我用了这个,但是决赛数据太大,我没用测试。
然后就是分类器了。这个又很多选择,例如LR,RF,XGBOOST,LightGBM等等,由于不可能一个个介绍。我就说的用的吧,那就是XGBOOST和LightGBM。(初赛还用了LR,决赛没有空,就没训练LR了)
4.模型融合
这个是最后决胜负关键点之一!!!(当然,我就是跪在这里了,头天还是16.最后一天融合被人挤到23名)。何为融合,就是把一堆分类器揉到一起嘛。当然,这是有套路的。我这里只介绍2种,也是我用的2种。
1.加权平均:很好理解,讲多个分类器的预测结果做个加权平均。看似简单无脑,其实很有效果。但是权重不好确定,可以使用线下CV确定权重,或者线上猜权重(土豪玩法,一天就3次提交机会)但是使用加权平均保证,你用的几个分类器线上结果不能差的太悬殊。(就是不要加入没用的分类器)
*一个大佬告诉我的骚操作(我没试过):给分类器设一堆随机种子,然后训练出一堆结果加权。。。。。。。
2.stacking:一句话解释就是:用其他分类器预测的结果作为当前分类器的特征。
这是一张网上的图,和我的表达可能不太符合。只看上面那半就好(下面那半的average不是我想表达的,人懒,不想画新图了)。
大致说下步骤:
(1)讲训练集切成n分(这儿我取5)。
(2)用1,2,3,4份训练分类器来预测第5份的概率,用1,2,3,5训练分类器预测第4份的概率.....(以此类推)。然后用1-5份训练分类器预测测试集的概率
(3)讲这些概率作为另一个分类器模型的特征(在现有的特征上面加一列概率特征)来训练第二层模型
这个方法要点是:用于stacking的模型尽量要差异性大,我用的xgboost和lightGBM融合效果其实不行,原因就是两者都是树形分类器,没太大差别。
stacking的训练代价很大。破机器也很难玩好。融合这一步做的好,最后一天是可以翻身的(初赛我的stacking效果很好,决赛不知道为何就GG了)。
另外,如果你发现了两组强特,他们相关性很强,可以尝试用他们分别训练模型然后融合,可以得到不错的效果。(理论上)
最后我的融合方案是:
用xgboost来stacking训练lightGBM(Model1);用lightGBM来stacking训练xgboost(Model2);训练单模型lightGBM(Model3)
结果加权:0.25*Model1+0.25*Model3+0.5*Model2
1. 数据分析
大赛题目是转化率预估,首先是对数据的理解就花了不少心思,数据中有不少除label不同外其他数据都相同的样本,刚开始也是像处理其他问题一样将这些样本看作是噪音,只保留了label为正的样本,后来发现在线上测试集中同样存在一部分数据都相同的样本,这时训练出来的模型对这些样本的预测值都是相同的,所以对于这些样本就不能简单的当作噪音来处理了。目前我们针对这种情况的处理是通过添加一些特征来标记他们之间的先后顺序。还有关于label不准确问题的处理,因为有些回流的时间超过5天还有最后几天的回流可能还没有反馈回来,这些就会使得label取值不准确。针对这种情况,我们通过统计所有数据的回流时间,发现:90.00%的回流发生在一天之内,99.00%的回流发生在两天之内,99.90%的回流发生在三天之内。这一分析我们如何构造选取线下训练集和验证集很有帮助。
2. 模型选择
实验表明lightgbm在学习效率与准确率上都比xgboost表现得好,而且它还有这更低的内存消耗。
3. 构造训练集
通过之前的数据分析,我们直接舍弃了30日的数据。考虑自身设备情况,我们仅选取了两天的样本作为训练集。比如以27,28两天的样本为测试集,以29日样本为线下验证集。这样构造训练以及验证集可以有效避免数据泄露问题。具体构造训练集与测试集可以根据自身设备情况多取几天的样本。比赛开始阶段,我们使用一个模型进行预测,后期,使用了模型融合,分别训练了4个模型。
4. 特征工程
我们首先对数据中age属性进行了等值域划分,然后通过统计找出对原始数据中维度较小那些基本特征,对这些特征进行了one-hot编码,这样不至于出现特征维数很大的情况。其次就是组合特征了,组合特征是相对比较重要的。组合特征是不能盲目胡乱组合,要多想想实际情况,做一些统计分析,当然也可简单的通过训练结果的来测试组合特征的重要性。
4.1 基本特征与特征one-hot
选取原始数据中维数较小的特征进行one-hot编码,主要包括用户的年龄、性别、婚恋状态、教育程度,广告的advertiserID、AppID、appPlatform,上下文的sitesetID和positionType。
4.2 特征交叉
不同特征之间的组合能起到更大的作用,我们分别使用户的年龄、性别、婚恋状态、教育程度、居住地与广告的creativeID、appID和positionID两两进行交叉,同时记录在这两个特征交叉时,广告CTR的排序特征。
4.3 特征贝叶斯平滑
在交叉得到的特征中,经观察,发现很多广告的CTR值并不准确,某些广告CTR值因为该广告总点击数较少而导致CTR较高,所以进行了贝叶斯平滑,贝叶斯平滑过程主要借鉴了博客上的思路。
4.4 离散化
在得到基本特征和处理后的特征后,主要针对统计出的广告CTR特征进行离散化,这种操作的目的是保证广告CTR值可以再预估时按照自身的重要性发挥不同的价值。
竞赛刚开始阶段,并没有注重交叉特征的构造和特征的贝叶斯平滑操作,只针对基本特征和基本特征上的统计特征进行处理,结果非常差,后来加入交叉特征和对特征进行贝叶斯平滑后,效果慢慢变好。这部分内容可以参看很多博客文章。
5. 模型融合
四个模型分别采用lightgbm进行训练,使用四个模型进行预测,对4个预测结果进行线性融合以得到最终结果。融合后的结果比单个模型的预测结果好,但是线性模型融合需要调整4个模型参数,加大了工作量。
6. 比赛心得
首先,要保证训练集的构造没有问题,如果训练集有问题,再怎么提特征,调参数都没用。下来是特征的提取,可以说这个过程是整个过程中最重要的,因为特征的好坏直接决定了预测结果的好坏,特征不好,模型调的再好结果还是不行。最后就是模型调参了,这部分相对也比较重要,调参要理解参数背后的意义以及调参后会带来的影响,毫无规律的乱试能调出好的参数的概率渺茫。
引言
从数据处理,特征工程,模型搭建,训练调优这一系列过程完整
1. 对赛题及其工业背景的深入了解
首先,我所花时间最长,也是感觉最重要的一环,是对赛题与数据要做到非常充分的了解.比赛名为腾讯社交广告算法大赛,那么我们一定要花一些时间了解一下当今媒体广告包括腾讯广点通平台的运营和收费机制,这些知识虽然看似与赛题不想管.但在我目前来看,对我特征工程和数据处理起到了潜移默化的巨大的影响.举个例子,在比赛数据中,出现了广告主-推广计划-广告-素材这样的4级树关系,应该所有同学都能从字面上理解这样的层级关系,在数据处理时进行类似树结构的方式也并不难想到,但其实仔细推开社交广告运营的机制,我们还能从这样的关系中发掘更多潜在的机器学习分类器很难自我学习,却有价值的特征.
2. 数据可视化及分析
对数据分布统计在每一个数据竞赛中都会需要, 较为体系化的分析流程与开源代码教程也不难找到. 本次大赛的另一个特点便是数据带有时序性, 这给数据处理与分析造成不小的困难. 我这里主要分享一些我所做的涉及时间序列的分析工作与成果.
(1) 截止至该日共出现的各个变量的不同值的数量
可以看到, 每日都会有新的之前从未出现的userID以及appID加入(对ad, creative, campaign, advertiser也等同). 这就意味着除了按日期划分的训练集中各个变量不一致外, 在线上预测集中一定会有训练集中不存在的ID. 所以在选择特征与训练集时要尽量做到将ID类特征抽象, 例如统计转化率, 做聚类等, 而避免直接使用ID类特征.

(2) 转化率分析
转化概率是本次比赛预测的objective, 与其最为相关的便是各个sample对应的CVR了, 官方所给baseline就是将历史统计的转化率来直接作为概率进行预测.
下图所示为每日所有sample的平均转化率. 其中蓝色线为原始数据, 考虑到最后五天的训练数据label有误, 又额外做出绿色线(转化时间小于等于1天), 红色线(转化时间小于等于两天). 可以看到, 转化率在20日及以后较为稳定, 在18,19日出现转化率的剧烈变化, 且这两日的数据总数也明显少于平均水平, 可能是恰逢节日或数据上传误差等因素, 综合考虑, 20日之前的数据暂时被弃用.

(3) 时序分析
笔者还对日转化率进行了ACF, PACF分析及ARIMA拟合, 但由于总日期数过少, 且CVR波动较大, 可能属于非稳定时间序列, 并不能通过去趋势等方法进行较好回归.
3. 训练集选取与特征提取区间
如果说在机器学习中有比特征还要重要的, 那就是训练集的选取了. 最好的训练集莫过于与线上测试集的变量分布完全相同, 这样的情况下线下的训练结果可以完美的用于线上数据的预测. 这种情况在一些特定的, 数据分布较为稳定的机器学习问题中可以实现.
但对本次社交广告算法大赛, 首先训练样本有时间先后关系, 而且如2中分析, 每日的user, ad都各不相同, 所以存在这样的一个隐含因素, 即若预测31日数据, 则使用越接近31日的数据训练, 则预测效果应该会越好. 但同时另一个问题, 即26日以后的数据, 由于回流时间为5日, 所以截止至31日时并不能准确统计广告是否转化, 且该问题在29, 30 两日尤为严重, 所以最后结合线下与线上测试, 我选择了26, 27, 28三天的数据进行线下CV与训练, 并用于线上测试. 在初赛阶段, 线下线上误差基本一致, 且增减情况良好.

4. 特征工程
在对赛题与数据有了充分的了解后,第二步就是特征工程了.特征工程上,我目前还没有非常得意的大家日日所念的magic feature, 我基本上是每天优化一些自己的特征,每天的成绩虽然进步不大,但也在稳步前行.交流群中几位大佬多次提及的强特征我至今也没有悟到,但也许后面就会慢慢发现,也许我已经提出了出来.
在特征工程上,最重要的, 也是三周里每一组周冠军都提到过的, 线上线下一致. 好多同学对这点理解不清, 其实用逆向思维, 首先对31日的预测集提取特征,因为是最后一天,所以无论如何都不会发生数据泄露. 这个时候再仿照31日数据特征提取的方式与时间区间, 一步一步提取, 就可以有效的规避数据泄露. 有效的避免数据泄露, 可以做到线上线下同增减, 这样的情况下, 当我们加入新特征线下误差降低时, 我们便可以推断出该特征有益, 反之亦然. 考虑到预测集为31日, 其前5天的label有不准确的情况, 但仍然可以进行统计. 但生成训练集时, 必须对特征提取区间模仿31日数据做处理(代码如下), 例如处理28日的数据, 那么提取之前的特征时, 只能够提取转化时间小于28日0点的数据, 否则会造成训练集与预测集特征不一致.
def fix_label(df_tmp, clickDay):
mask = df_tmp['conversionTime'] >= clickDay*10000
df_tmp.ix[mask, ['label', 'conversionTime']] = 0
return df_tmp同时, 另一个难点是在根据历史观测值进行转化率统计时, 出现了样本稀疏的情况, 则根据中心极限定理, 观测概率并不能较好的代表真是概率. 在CTR预估中, 两个经典的方法便是贝叶斯平滑与指数平滑. 相关博文在互联网都不难找到.
我这里再说一点我结合本次大赛数据, 对贝叶斯平滑做的一点点小的修改. 例如对我们数据中存在的 root -> advertiser -> campaign -> ad -> creative 层级关系(root为训练集中全部样本), 这样的层级关系隐喻了在同一个父节点下的子节点, 其来自于同一个Beta分布, 所以我逐层进行了贝叶斯平滑, 且建立层级关系还有一个好处, 即对预测集出现的数据, 若该creativeID 在训练集从未出现过, 则在pandas.merge时该值为空, 则向上寻找其父节点的统计值, 最高一层为root, 是基与全部训练数据的统计, root的值不进行贝叶斯平滑, 且一定存在, 这就保证了当在预测集中遇到了未出现的样本时, 使用最合理的缺省值进行补全.

5. 机器学习模型
目前我在使用xgb与lgb两种模型, 好处是模型泛化能力强且速度快, 可以最快得到结果以进行特征筛选与调试. 模型stacking和bagging是提升最终结果的利器,但不建议大家太早使用,一是浪费时间,2是这样的大杀器是否使用,对我们结果本质的提升是没有帮助的,因为如果现在使用融合效果提升,那么未来其他同学加入模型融合后,也必然会赶超自己.
这个比赛旨在预测广告的转化率pCVR,加入转化率因子优化排序(有的广告可能ctr高,但是转化低),提升广告投放效果,提升ROI。
1. 数据集的划分: 数据集的划分要与最终提交的测试集预测逻辑一致。提交的预测集是根据31号之前的数据预测31号的转化率,所以数据集也应该按照日期来划分训练集和验证集。第二,不考虑日期来随机划分训练集和验证集,可能存在数据泄露。比如,训练集中如果有27号的数据,用27号的数据训练出来的模型来预测27号之前的样本,就存在数据泄露。另外,27号训练出来的模型反映的是27号的规律,用这个规律来预测27号之前的测试集,这个逻辑不太合理。实际情况是,随机划分方式,线上线下结果不一致。而通过20-26号的数据训练,27-28号的数据验证,线下和线上则基本变化一致。(29-30号有些负样本可能是还没有来得及上报转化,所以数据不可信,将其舍弃)
2. 噪音数据预处理: 训练集中有些样本是噪音,比如相同的样本出现很多次,或者同样特征出现不同的label,这些情况在真实场景下都是可能的。在我的处理中,直接将相同的样本去了重,将矛盾的样本全部去掉,这样有大概万分之8的提高。但是,有的参赛选手,从这种噪音数据里面提取了相关特征,据说效果很好,以后可以尝试。
3. 缺失值处理: 测试集上可能有些特征没有取值,对于这种missing value的情况,用众数或者平均数代替简单地赋0可能更有效,有大概万分之2的提高。
4. 统计特征: 对于userID, creativeID, positionID,可以统计下点击量-转化量-转化率等统计特征(但是不能有数据泄露,只能用当天以前的样本进行统计),这个对效果提升特别大(约千分之一)。同时,对于其他特征也可以加入统计特征,比如gender分别是1,2时的点击量-转化量-转化率等统计特征。对于age,connectionType等其他字段也可以加入统计特征。
5. 组合特征: 对于positionID-userID, positionID-creativeID, positionID-connectionType等组合特征,可以统计点击量-转化量-转化率等特征,组合特征对效果也有较大的提升(约千分之一)。
6. 模型寻优: 模型寻优的方式有random search, grid search等,这次比赛模型寻优没有获得太大的效果提升。下次可以尝试用grid search找到最好的参数组合,然后在该点附近缩小范围进一步寻优。另外,有一个自动化寻优工具Hyperot可以根据之前参数组合的表现,决定下次的参数组合,可以进行尝试,看有没有效果。
6. 模型组合: 参数组合的方法有stacking, blending和最简单的average等。下次可以重点进行探索,根据其他参赛者的经验,ensemble可以带来较大的提升,但要保证base model的多样性,尽量相关性小一些。另外,论文[1]中提到的ensemble selection下次也可以尝试一下。
1.数据集构造方面
数据集train.csv中正负样本是1:40,这是一个明显的正负样本不均衡的问题,这就提示我门在构建模型的时候是要用哪些数据,常见的方法就是对负样本下采样(down sampling),对正样本上采样(upsampling),尽量使得正负样本均衡。
2.特征上的一些方法
在广告点击率和转化率的特征中,特征可以分为三类,一是categorical feature(无序特征),ordinal feature(有序特征), numberical feature(数值特征)。我们队对于特征的处理
1)使用统计频率、转化次数特征、转化率特征代替onehot,因为数据太大,one-hot编码会出现一个很大维数的稀疏矩阵,导致运行很慢以及运行好长时间不出结果。
2)对训练集和测试集中的重复样本构造是否第一次点击,是否中间点击,是否最后点击,第一次和最后一次间隔特征,大佬们所谓的trick也和我们的这一点差不多。
3)大量使用组合特征,主要是用户特征和广告上下文特征。很多成绩在baseline附近的萌新应该是直接使用单特征one-hot编码,基本上没有考虑组合特征以及特征之间的相关性。
3.模型构建
在kaggle平台上avazu的比赛获奖第二名方案中作者用了random forest, GBDT(gradient boosting decision tree), Online SGD,Factorization machine四种模型,最后把他们按权重进行融合。
这次竞赛的要求是让选手预测出 App 广告点击后被激活的概率,也就是一种转化率的变形问题。对于这种问题,在提取特征的时候一般有3种有效的特征,一是原有的id特征,二是根据一些id特征做出来的历史转化率特征,三是相似度特征。对于我们这次竞赛,应该具体情况具体分析。
在训练集和测试集中,共有的特征是:clickTime(用户点击时间,我想应该是点击广告中素材的时间,题目没明说);creativeID(广告素材的id),userID(用户id),positionID(广告位id,广告曝光的具体位置),connectionType(移动设备当前联网方式),telecomsOperator(运营商);训练集还多个 lable 列(我们要预测的列,二分类)和conversionTime(转化回流时间);训练集给了第17天到第30天的数据,也就是说点击时间是从第17天开始的,测试集是要预测第31天的情况。
其余的6个数据文件依次是:
1、user.csv (用户基础特征文件):有 用户 id、年龄、性别、教育程度、婚恋状态、是否有小孩、家乡、常住地;
2、app_categories.csv ( App 特征文件):有 Appid、app分类;
3、ad.csv (广告特征文件):有 广告主 id、推广计划 id、广告 id、素材 id、App的 id、App 所在平台;
4、position.csv (广告位特征文件):有 广告位 id、站点 id、广告位类型;
上面4个文件,我都可以根据 和训练集 预测集中相同的列,将他们的数据 merge 到训练集 预测集中,这样就完成了第一部分特征的提取,对于其他几部分特征,我之后就不再举这么详细的例子了!
5、user_installedapps.csv(用户 App 安装列表文件):截止到训练数据时间段中第一天用户全部的 App 安装列表,但是这个文件中只有 144万用户,和训练集中的 259万用户 相差些,和测试集用户的交集是 15万(测试集中一共有29万用户);
6、user_app_actions.csv (用户 App 安装流水文件):有3列,用户 id、安装时间、appid,但是这个文件只有 78万用户,和训练集中的259万用户 相差些,和测试集用户的交集是 8万(测试集中一共有29万用户)。
我们的特征主要有4个部分组成
1:第一个部分是基础Id特征,上面提到的几乎都有。刚开始我们使用了这些特征,后来将每一个基础id特征都用相应的“转换率”进行了替代(对转化率的定义是:在过去7天中,这款appID label 为1的数目/(Label为0 + label为1的总数目))。
2:第二部分是组合特征,我们进行暴力搜索,首先进行两两组合,然后用230多个组合特征进行预测模型,得出最中要的50个,在组合特征中最重要的一些是:position和其他的组合。 然后提取出来他们的转化率
3:第三个部分是提取的一些统计特征+trick
(用户每天点击app多少次、这款appID在全局上的label为0的数据/label为1的数目)
(trick也是这个比赛所有队伍都比较在意的一些强特征,实际上这些trick是根据真实数据的特征分析出来的,初赛和复赛的trick都不一样,初赛的时候,是 对相同样本~clickTime+userID一样就定义为相同样本 进行排序,总数这两个特征; 复赛的时候是:同一个userID数据进行排序、统计总数、和第一条样本的时间差、和最后一条样本的时间差、每相邻两个样本之间的时间差,在初赛、复赛的时候这些trick都能提高 两个千分点)。
二、一些提分点:
1:转化率很重要,但是转化率在提取的时候我们是基于过去7天数据来提取的,所以对一些具有时间性质的组合特征,有时候就会出现在上一个7天中某个属性的转化率是0,但是在下一个7天中那个属性可能就不是0,这样不符合实际情况,会降低模型的预测效果,所以需要 拉普拉斯休整,这样可以提高0.5个千分点:
2:tfidf特征:对比赛过程中两个很大的数据文件user_installedapps.csv user_app_actions.csv,做统计特征的话,费时间而且效果不好。所以计算每一个appID的tfidf值,计算出来最合适的几个appID来当做特征(我们队伍没做)
3:模型部分提分点,在下面部分提及
三、模型部分
在这次竞赛中很多选手都选用了 xgboost 和 ffm 这两种模型,初赛的数据量不是很大,用这两种模型还说的过去,但是在复赛的时候,数据量几乎达到了原先的10倍大小,只有在 xgb 上设置 gpu 加速模块,同时增加机器的核数以及gpu,在参数设置中将这些设置好,才能达到一个不错的速度。我们在初赛使用了 xgb + lightgbm这两种模型,下面介绍下其中的xgb模型
首先因为它是一种树模型,属于 booster 的迭代算法,支持损失函数,支持L1L2正则可以防止过拟合,里面还有 scale_pos_weight 这个参数可以调节正负样本的加权训练。基分类器是 CART 树,每一棵树上的叶子节点都会有对应的判断,算法中采取投票器原则,得到最终的预测结果。而且在树分裂的时候,每一次分裂基于前一次分裂和目标函数 来计算信息增益,根据信息增益来选择最合适的特征,以及分割点。这是一种很完备的算法。
提分点:我们选取了 xgb lightgbm 随机森林 gbdt这4中模型当做基模型,Lr作为第二层,使用stacking提了一些分
https://github.com/oooozhizhi/TencentSocialAdvertising-30th-solutions
排名:30th. 成绩:0.102001;原始模型只使用了28,29两天的数据。
主要工作:
1 针对业务的特征工程
2 使用lightgbm来抽取特征,预测app转化率
3 探索了ffm的使用(基于lightgbm抽取得到的特征)
4 小技巧
1 贝叶斯平滑
2 (tricks)探测平台的平均转化率,然后所有转化率以此乘以一个ratio
3 Facebook的sample技巧,sample之后数据变成原来的几分之一,但是效果只有微笑下降。在这里效果不好,但是如果数据集再大一些,应该能有很大作用。
别人的思路分享:
1st nju_newbie 0.100787
框架:数据预处理,数据去噪,特征提取,模型构建和模型融合
特征抽取:转化率,点击特征,安装特征和时间特征
模型:GBDT(lightGBM),wide&deep网络,pnn网络和nffm网络
2nd Raymone 0.100868
框架:数据清洗,数据划分,特征提取,模型训练和模型融合
数据清洗:
1 由于转化回流时间有长有短,所以最后五天的label可能是不准确的,尤其是第30天。如果将第30天的数据全部删除,将会丢失大量有用的信息。如果全部保留,又引进了相当程度的噪声。而我们发现,转化回流时间是与APP ID有关的。于是我们统计了每个APP ID的平均转化回流时间,并且删除掉了第30天中平均转化回流时间偏长的数据。
模型融合:
1 我们模型融合采用的是Stacking方法。除了LightGBM之外,我们又训练了FFM,LR,GBDT(xgboost),ET模型。最终Stacking帮助我们提高了2.5个万分点左右。
3rd 我很难受 0.101017 :模型融合:xgb,lgb,ffm
大赛介绍
计算广告是互联网最重要的商业模式之一,广告投放效果通常通过曝光、点击和转化各环节来衡量,大多数广告系统受广告效果数据回流的限制只能通过曝光或点击作为投放效果的衡量标准开展优化。腾讯社交广告(http://ads.tencent.com)发挥特有的用户识别和转化跟踪数据能力,帮助广告主跟踪广告投放后的转化效果,基于广告转化数据训练转化率预估模型(pCVR,Predicted Conversion Rate),在广告排序中引入pCVR因子优化广告投放效果,提升ROI。
本题目以移动App广告为研究对象,预测App广告点击后被激活的概率:pCVR=P(conversion=1 | Ad,User,Context),即给定广告、用户和上下文情况下广告被点击后发生激活的概率。
特征构造:
比赛中特征主要包括三大类,主要包括用户信息,广告信息,上下文信息。基础的特征都是离散的id信息,对于一些类别比较少的id的是可以做onehot的。但是由于我们后期改用了统计类的特征,它们与id类特征的onehot后是重复的,所以后面我们都没有使用onehot的特征。我们统计的特征主要包括四大类:某个id(或两个id组合)的点击次数、某个id(或两个id组合)的转换次数、某个id(或两个id组合)的转换率、一个组合在其中一个id下的条件概率。
除了简单的统计类特征,我们还根据预测集简单构造了一些leakage的特征。比如某个用户当天的点击广告的前后时间差之类的。这些特征是对成绩有很大提高的,但是实际业务中不可能获取。
特征抽取与清洗:
我们尝试遍历了所有的统计类特征,然后抽取一部分样本放进去xgboost进行重要性排序。然后再结合皮尔森系数进行特征的清洗。这个流程我们是自动化处理的,这样子提取到的特征其实就已经能够拿到一个很好的分数了。但是就是因为我们太过暴力简单地遍历,导致上限也十分明显。
模型训练:
我们比赛主要使用了xgboost、lightgbm与ffm这三个工具。ffm是在决赛时候才使用的。相对于其他队伍而言,我们的ffm的方案的成绩是比较好的。FFM的数据预处理十分重要,主要是针对特征进行离散化。不同类型的特征的离散化方案是不一样的,比如对于长尾分布明显的特征(比如某个id的点击次数)需要先取log进行分箱操作。而对于平滑后的转换率类的特征,其实可以比较简单的进行归一化之后直接分箱。而且gbdt输出的叶子节点是一个很强的特征,把gbdt的叶子节点加入FFM,可以让FFM有一个很大的提升。
比赛反省
这里将分成代码与架构、模型、特征、数据分析、拓展性五部分进行反省。
代码、架构与工具:
虽然本人对机器学习还是有一定了解的。但是却对很多开源好用的工具没有涉及。整个比赛的代码架构,基本都是自己边写边琢磨的。很多统计类的特征,都是自己用python的字典硬刚统计,基本没有使用过pandas、sklearn等机器学习的好用的工具。总之在这个方面,个人真的有很大的短板,也严重影响了开发效率。特别是前期的数据分析阶段,基本都没有做过。而且这个也导致整个代码的架构很凌乱,复用性很不强。个人感觉真的需要看看别人的开源框架,从逻辑层将代码分离。
模型:
我们很大部分的精力都集中在了特征工程上,这个是没错的,因为特征真的决定了上限。但是我们却对模型没有太深究,这个直接导致了我们最后面的决赛的模型融合阶段是完全瞎操作。其实特征工程和模型选择两者没有本质的冲突,在特征工程的时候,应该多了解更多相关可以解决比赛的模型。这个是很有必要的,不要盲目地调用api,要根据自己的特征对模型进行修改才是真正能上得了台面的大神。
特征:
虽然我们花了很多时间在特征上面,但是并不代表我们的特征工程是做得很好的。相反,30名左右的队伍的特征工程可能都做得比我们要好。在初赛阶段,我们尝到了特征遍历的甜头(轻松进前十),导致我们认为只要遍历特征,选取重要性高的特征其实就可以了。这种想法真的太naive了。。。现在想想都觉得羞耻。个人觉得很多大神的分享还是很有用,不应该直接暴力遍历特征,那样子对机器的要求太高,而且准确度也不一定高,拓展性不强。
统计类特征其实是不需要太操心的。因为根据不同的模型,我们可以改换使用onehot,组合特征的表示,如果使用deep and wide这样的模型,也是可以解决的。 这种特征其实并不需要花太多的心思。重要的magic的特征从来都是从业务出发的。所以在构造的特征的时候,并不需要优先遍历所有的特征,而是应该从业务分析一些模型没有办法自动组合出的特征。比如一个用户的历史点击序列(01串)之类的特征,额外的辅助文件(比如这次比赛的action与install)生成的特征。其实很多的特征从业务上就能够判断是否关联偶尔,比如上下文的特征,其实是不需要做任何的关联的,上下文的特征往往都是一个bias而已。
再者,我们在比赛中对数据的处理太粗糙。虽然树类模型是不需要做归一化处理的,但是我们甚至前面生成转率特征之类连平滑都没做,缺省值的情况都没有处理。而且其实在前期就做归一化,离散化地处理对后面的其他模型的组合有大帮助。
数据分析:
这个和工具有一定关联。在这个比赛中,我们直接就开始了特征工程,只是进行了一些简单的分布分析,看分布来选取了训练集和测试集。其实这个是很不合理的,特别是比赛中明显交代了最后几天的数据不是完全准确的。我们的选择方案是直接弃用最后一天,但是却没有想过前后两天的信息关联性很大,前一天出现的id往往在后一天也会出现。总而言之,我们并没有针对测试集和训练集中的id分布做分析,这个真的是一个很愚蠢的事情。。。也是导致我们没有进前十的一个很重要的因素。
拓展性:
这个拓展性主要包括代码的拓展性和数据的拓展性。我们的代码拓展性真的做得很烂,基本写一个操作就要换重新换写一次脚本,一个脚本处理一个问题,参数都是写死在脚本里面,没有写那种可以通过传参动态处理问题的脚本。还有就是我们数据的拓展性做得很差,我们生成了一堆特征文件,但是都只是6天的,导致我们想增加训练天数的时候,根本没有拓展性可言。这个也和我们代码没有拓展性有一定关系。
最后总结
初赛应该在注重特征工程的同时,让自己的代码架构更具有复用性,方便复赛使用。而且在初赛后期的阶段其实就可以做一些简单的模型组合的尝试了,但是我们也没有。
参考资料:
https://blog.csdn.net/haphapyear/article/details/75057407/
https://blog.csdn.net/spantar_X/article/details/74936802
https://cloud.tencent.com/developer/article/1005233
https://blog.csdn.net/davidie/article/details/72983422
https://blog.csdn.net/sinat_36187551/article/details/72902717
https://blog.csdn.net/a1066196847/article/details/73928071
https://blog.csdn.net/zhizhi_zhizhi_zhizhi/article/details/77799645
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









