






是在努力学习代码的小白一枚~随手记录日常学习知识点,防止遗忘~
关于模型配置:model=dict()
backbone = dict(
type = ' mmpretrain.ConvNeXt ' ) 表明在相关程序里选用ConvNeXt作为主干网络。
ConvNeXt是一种卷积神经网络架构。它是为视觉任务设计的,在图像分类等任务中有出色表现。与传统卷积网络相比,ConvNeXt借鉴了Transformer的一些设计理念并加以改进,比如采用更大的卷积核(7*7)、depthwise conv模块上移(1x1 conv → depthwise conv → 1x1 conv变为depthwise conv → 1x1 conv → 1x1 conv)、下采样模块kernel=stride、调整堆叠block的次数(ResNet50 3,4,6,3→3,3,9,3)、借鉴ResNext组卷积思想(采用depthwise convolution:group数和通道数channel相同)、使用Inverted Bottleneck模块(图1)、减少激活函数的使用(图2)、减少批归一化并将批归一化(Batch Normalization,BN)改为层归一化(Layer Normalization,LN)、设置单独的下采样层(主分支3x3卷积层stride=2,捷径分支1x1卷积层stride=2→Layer Normalization+kernel=2,stride=2的卷积层),提升了特征提取能力。
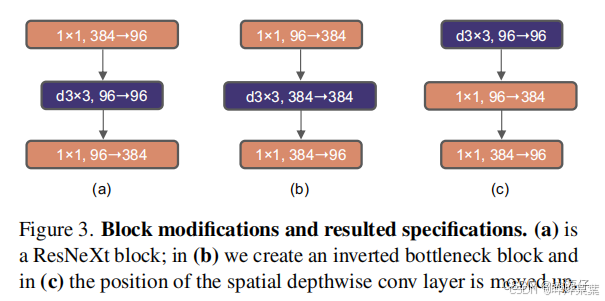
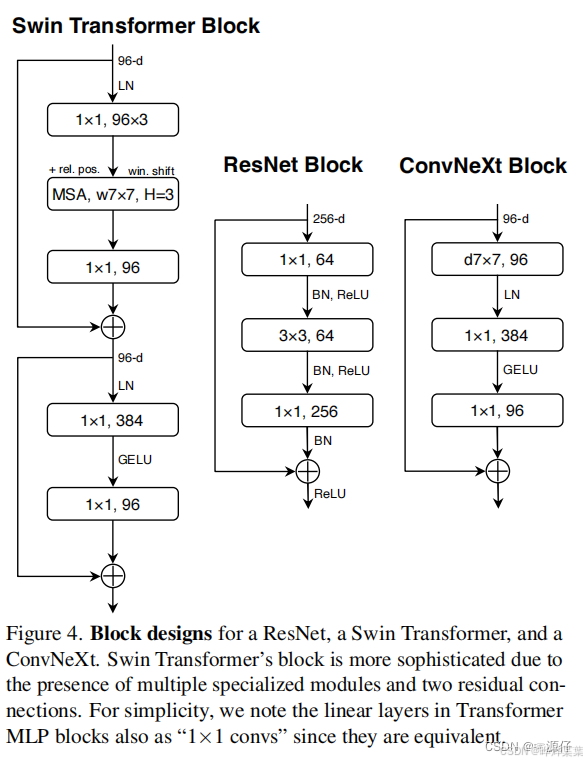
在“mmpretrain”场景下使用ConvNeXt为主干网络,意味着在预训练模型相关工作中,以ConvNeXt为基础构建模型框架。主干网络负责从输入数据中提取主要的特征信息,后续可基于这些特征进行分类、检测等具体任务的模型构建 。
arch='tiny' 使用轻量级架构来完成相应任务 。
在深度学习领域,“tiny” 架构常指轻量级的模型结构设计。这类架构参数量少、计算复杂度低。比如在图像分类任务里,有专门设计的 Tiny 模型,能在保证一定性能的同时大幅减少资源占用。
out_indices=[0, 1, 2, 3] 指定输出网络中哪些层的特征。
这行代码定义了一个列表,名为 `out_indices`,其中包含了四个整数元素:0、1、2 和 3。用于指定从某个多特征层网络结构(比如特征金字塔网络FPN)中提取哪些层的特征。
• 列表中的每个数字代表特征金字塔中的一层。例如,0 可能代表最低分辨率的特征层,而 3 可能代表最高分辨率的特征层。
drop_path_rate = 0.4 DropPath(随机路径丢弃)是一种正则化技术。在深度学习模型里,路径指的是信息从输入到输出所经过的一系列层的连接。DropPath率(这里是0.4)表示在训练过程中,每个样本在每次前向传播时有40%的概率随机将某一层的连接“丢弃”,也就是让这一路径暂时失效。这样做可以防止模型过度依赖某些特定的路径,促使模型学习到更加鲁棒和通用的特征表示,从而提高模型的泛化能力,减少过拟合的风险 。
layer_scale_init_value = 0., 禁用 layer scale;“layer_scale” 用于增强模型各层的表示能力。
具体来说,“layer_scale” 是在模型的每一层引入的可学习缩放因子,它可以帮助模型更好地调整不同层之间的信息流动。“init_value” 指的是这个缩放因子的初始值。当 “layer_scale_init_value” 设置为 0. 时,意味着这些缩放因子在初始化时被设置为零。
gap_before_final_norm=False 在最终归一化前不存在特定操作
use_grn=True GRN全局响应归一化(Global Response Normalization,GRN) 是一种在ConvNeXtV2中提出的归一化方法,类似于注意力机制,用于对特征进行重标定。GRN主要由全局特征聚合、特征归一化和特征校准三部分组成。
dropout_ratio=0.1 在每次训练迭代中,有10%的神经元会被随机丢弃。
Dropout是一种在神经网络训练中用于防止过拟合的技术。在训练过程中,Dropout会随机地将一部分神经元的输出设置为0,这意味着在每次迭代中,网络的一部分会被“丢弃”,即暂时不参与计算。
这种方法可以强制网络学习更加鲁棒的特征,因为它不能依赖于任何一个特定的神经元。通过这种方式,网络变得对神经元的特定配置不那么敏感,从而减少了过拟合的风险。Dropout通常在全连接层中使用较多,在卷积层中较少使用,因为卷积层本身就具有一定的正则化效果。
loss_decode=[ dict(type='CrossEntropyLoss', # 损失函数类型:交叉熵损失 use_sigmoid=False, avg_non_ignore=True, loss_weight=1.0), ]
这段代码定义了一个损失解码(loss_decode)的配置列表,其中包含一个字典,用于设置损失函数的相关参数。
• **CrossEntropyLoss**:这是一种常用的损失函数,主要用于分类任务。它衡量模型预测的概率分布与真实标签之间的差异。
• **use_sigmoid=False**:表示不使用Sigmoid激活函数。在交叉熵损失中,如果use_sigmoid为False,通常意味着输入到损失函数的是经过Softmax处理后的概率值,适用于多分类问题。
• **avg_non_ignore=True**:表示对于损失计算,支持通过 avg_non_ignore 和 ignore_index 忽略某些标签的索引(通过ignore_index设置忽略标签值)。这样,平均损失只会在未忽略的标签中计算,可能会获得更好的性能。
• **loss_weight=1.0**:这是该损失函数的权重系数,用于调整该损失在总损失中的相对重要性。值为1.0表示其权重与其他未指定的损失相同(如果有的话)。
default_hooks = dict(
checkpoint=dict(type='CheckpointHook', interval=5, max_keep_ckpts=2))
• 保存最新的多个权重
如果只想保存一定数量的权重,可以通过设置 max_keep_ckpts 参数实现最多保存 max_keep_ckpts个权重,当保存的权重数超过 max_keep_ckpts 时,前面的权重会被删除。
上述例子表示,假如一共训练 20 个 epoch,那么会在第 5, 10, 15, 20 个 epoch 保存模型,但是在第 15 个 epoch 的时候会删除第 5 个 epoch 保存的权重,在第 20 个 epoch 的时候会删除第 10 个 epoch 的权重,最终只有第 15 和第 20 个 epoch 的权重才会被保存。
default_hooks = dict(
checkpoint=dict(type='CheckpointHook', save_best='auto'))
• 保存最优权重
如果想要保存训练过程验证集的最优权重,可以设置 save_best 参数,如果设置为 'auto',则会根据验证集的第一个评价指标(验证集返回的评价指标是一个有序字典)判断当前权重是否最优。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









