




文章目录
1、概述
官方图标

- Cloudera Impala是一款 时髦的、开源的、大规模并行处理的 SQL引擎
为Hadoop提供 低延时、高并发的 查询分析功能
1.1、特点
- 对内存的依赖很大,速度快但容易内存溢出
- data locality:尽可能地将读数和计算分配在同一台机器,减少网络开销
- 支持各种文件格式,如:文本文件、序列文件、RCFile、Avro、Parquet
- 支持压缩,如:snappy、gzip、bz2
- 可访问HIVE元数据,查询HIVE数据
- HIVE数据更新时,需要刷新该HIVE表【缺点】
1.2、架构
架构图
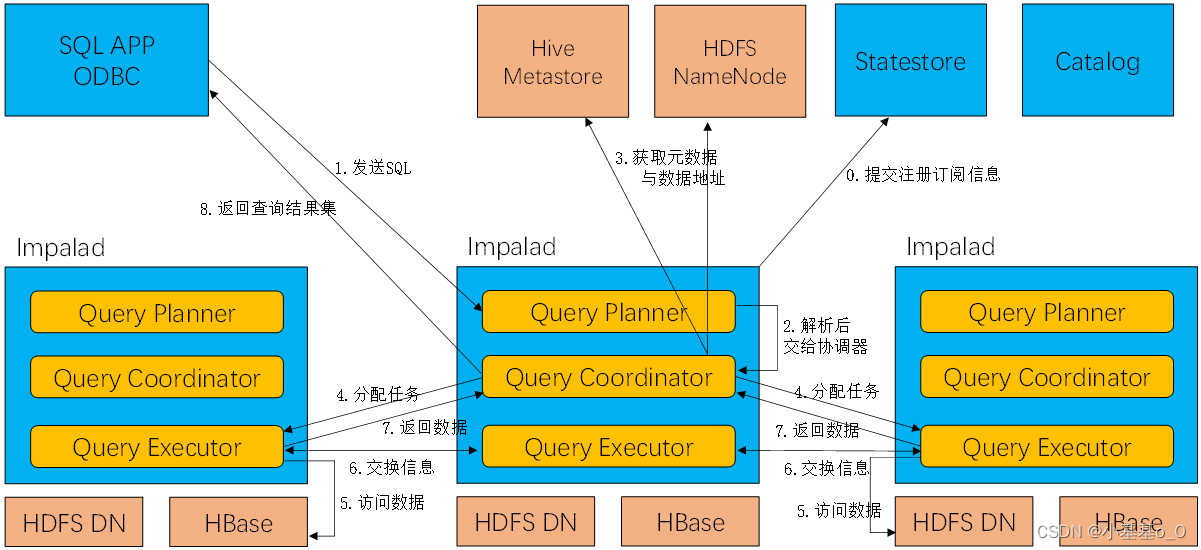
- 创建impalad进程,impalad向StateStore提交注册订阅信息,StateStore创建1个statestored进程,用来处理impalad的注册订阅信息
- 客户端提交SQL
- Query Planner解析SQL,生成解析树;然后Planner把解析树变成若干PlanFragment,发送到Query Coordinator
- Coordinator从元数据库中获取元数据,从HDFS的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点
- Query Coordinator初始化相应impalad上的任务执行,即把查询任务分配给所有存储这个查询相关数据的数据节点
- Query Executor读取HDFS数据
- Query Executor之间交换信息
- Query Coordinator汇聚来自各个Query Executor的结果
- Query Coordinator把结果返回给客户端。
| impala组成 | 进程 | 说明 |
|---|---|---|
| Catalog daemon | catalogd | 作为Impala的目录存储库和元数据接入网关 |
| Statestore daemon | statestored | 将整个集群的元数据传播到所有Impala进程 |
| Impala daemon | impalad | 1、负责协调客户端提交的查询的执行; 2、给其它impalad分配任务以及汇总其它Impalad的执行结果; 3、读取HDFS |
建议Impalad运行在DataNode所在节点
建议StateStore和Catalog服务在同一节点
2、CDH添加impala
添加服务
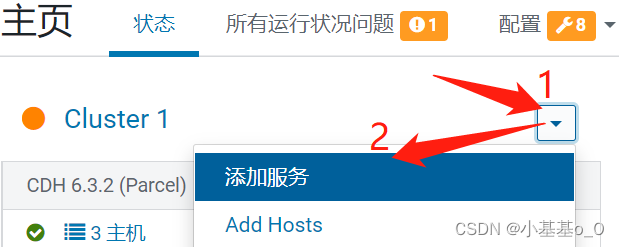
点选impala,然后继续

角色分配
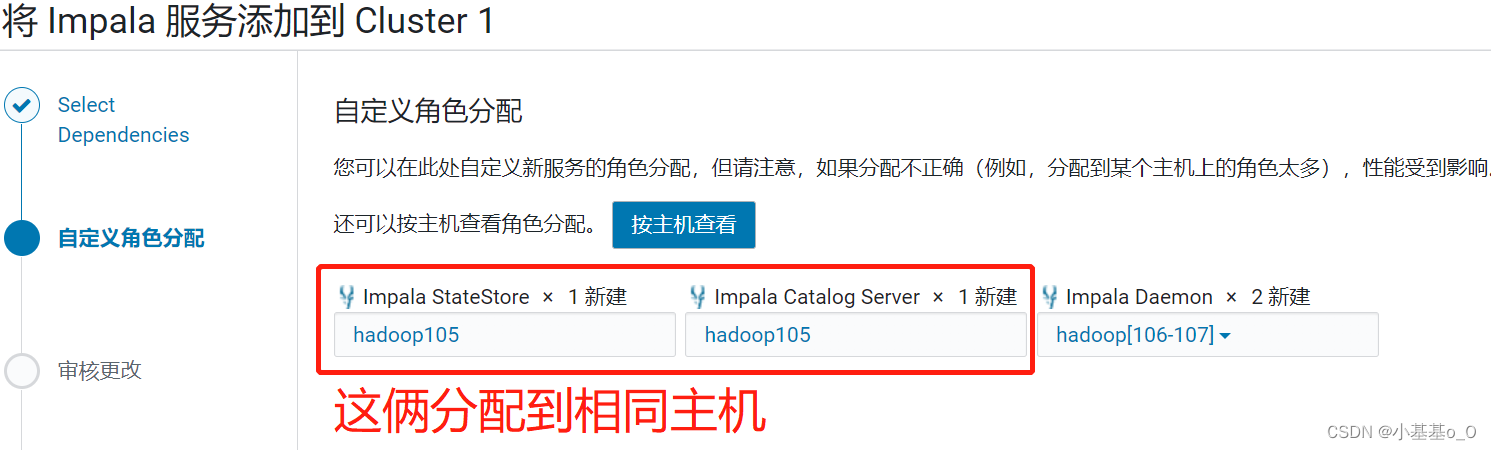
无修改

Hue配置关联impala
2.1、配置
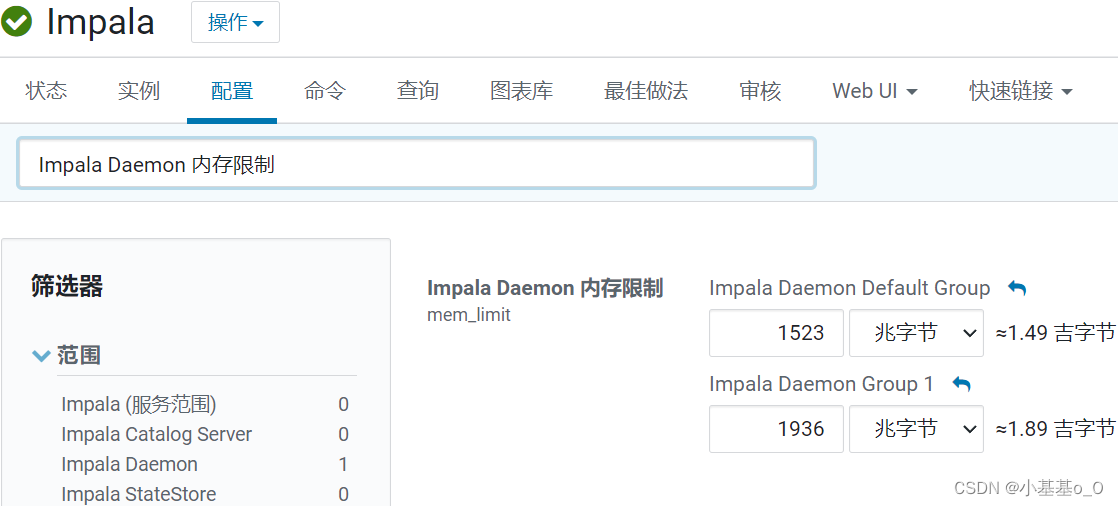
impalad内存
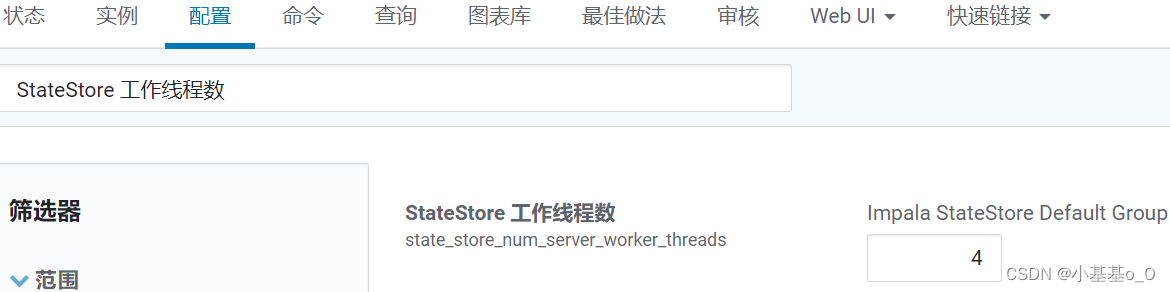
StateStore工作线程数
- Impalad Deamon内存限制:
若工作节点内存128G,120G用于计算,NN分了80G,那么可分40G给impalad - StateStore工作线程数:建议调大,8或10都可
3、impala客户端
3.1、impala-shell
| 常用选项 | 说明 | 默认值 |
|---|---|---|
-h, --help |
显示帮助信息 | |
-i IMPALAD, --impalad=IMPALAD |
impalad连接的<host:port> |
当前主机的主机名:21000 |
-f QUERY_FILE,--query_file=QUERY_FILE |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 9006
9006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











