







四.append()为切片添加元素
Go语言的内建函数 append() 可以为切片动态添加元素,代码如下所示:
var a []int
a = append(a, 1) // 追加1个元素
a = append(a, 1, 2, 3) // 追加多个元素, 手写解包方式
a = append(a, []int{1,2,3}...) // 追加一个切片, 切片需要解包不过需要注意的是,在使用 append() 函数为切片动态添加元素时,如果空间不足以容纳足够多的元素,切片就会进行“扩容”,此时新切片的长度会发生改变。
切片在扩容时,容量的扩展规律是按容量的 2 倍数进行扩充,例如 1、2、4、8、16……,代码如下:
var numbers []int
for i := 0; i < 10; i++ {
numbers = append(numbers, i)
fmt.Printf("len: %d cap: %d pointer: %p\n", len(numbers), cap(numbers), numbers)
}代码输出如下:
len: 1 cap: 1 pointer: 0xc0420080e8
len: 2 cap: 2 pointer: 0xc042008150
len: 3 cap: 4 pointer: 0xc04200e320
len: 4 cap: 4 pointer: 0xc04200e320
len: 5 cap: 8 pointer: 0xc04200c200
len: 6 cap: 8 pointer: 0xc04200c200
len: 7 cap: 8 pointer: 0xc04200c200
len: 8 cap: 8 pointer: 0xc04200c200
len: 9 cap: 16 pointer: 0xc042074000
len: 10 cap: 16 pointer: 0xc042074000代码说明如下:
- 第 1 行,声明一个整型切片。
- 第 4 行,循环向 numbers 切片中添加 10 个数。
- 第 5 行,打印输出切片的长度、容量和指针变化,使用函数 len() 查看切片拥有的元素个数,使用函数 cap() 查看切片的容量情况。
通过查看代码输出,可以发现一个有意思的规律:切片长度 len 并不等于切片的容量 cap。
往一个切片中不断添加元素的过程,类似于公司搬家,公司发展初期,资金紧张,人员很少,所以只需要很小的房间即可容纳所有的员工,随着业务的拓展和收入的增加就需要扩充工位,但是办公地的大小是固定的,无法改变,因此公司只能选择搬家,每次搬家就需要将所有的人员转移到新的办公点。
- 员工和工位就是切片中的元素。
- 办公地就是分配好的内存。
- 搬家就是重新分配内存。
- 无论搬多少次家,公司名称始终不会变,代表外部使用切片的变量名不会修改。
- 由于搬家后地址发生变化,因此内存“地址”也会有修改。
除了在切片的尾部追加,我们还可以在切片的开头添加元素:
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头添加1个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片在切片开头添加元素一般都会导致内存的重新分配,而且会导致已有元素全部被复制 1 次,
因此,从切片的开头添加元素的性能要比从尾部追加元素的性能差很多。
因为 append 函数返回新切片的特性,所以切片也支持链式操作,我们可以将多个 append 操作组合起来,实现在切片中间插入元素:
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片每个添加操作中的第二个 append 调用都会创建一个临时切片,并将 a[i:] 的内容复制到新创建的切片中,然后将临时创建的切片再追加到 a[:i] 中。
五.切片复制
Go语言的内置函数 copy() 可以将一个数组切片复制到另一个数组切片中,如果加入的两个数组切片不一样大,就会按照其中较小的那个数组切片的元素个数进行复制。
copy() 函数的使用格式如下:
copy( destSlice, srcSlice []T) int其中 srcSlice 为数据来源切片,destSlice 为复制的目标(也就是将 srcSlice 复制到 destSlice),目标切片必须分配过空间且足够承载复制的元素个数,并且来源和目标的类型必须一致,copy() 函数的返回值表示实际发生复制的元素个数。
下面的代码展示了使用 copy() 函数将一个切片复制到另一个切片的过程:
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{5, 4, 3}
copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中
copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置copy() 函数的第一个参数是要复制的目标 slice,第二个参数是源 slice,两个 slice 可以共享同一个底层数组,甚至有重叠也没有问题。
六.切片删除
Go语言并没有对删除切片元素提供专用的语法或者接口,需要使用切片本身的特性来删除元素,根据要删除元素的位置有三种情况,分别是从开头位置删除、从中间位置删除和从尾部删除,其中删除切片尾部的元素速度最快。
从开头位置删除
删除开头的元素可以直接移动数据指针:
a = []int{1, 2, 3}
a = a[1:] // 删除开头1个元素
a = a[N:] // 删除开头N个元素也可以不移动数据指针,但是将后面的数据向开头移动,可以用 append 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化):
a = []int{1, 2, 3}
a = append(a[:0], a[1:]...) // 删除开头1个元素
a = append(a[:0], a[N:]...) // 删除开头N个元素还可以用 copy() 函数来删除开头的元素:
a = []int{1, 2, 3}
a = a[:copy(a, a[1:])] // 删除开头1个元素
a = a[:copy(a, a[N:])] // 删除开头N个元素从中间位置删除
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以用 append 或 copy 原地完成:
a = []int{1, 2, 3, ...}
a = append(a[:i], a[i+1:]...) // 删除中间1个元素
a = append(a[:i], a[i+N:]...) // 删除中间N个元素
a = a[:i+copy(a[i:], a[i+1:])] // 删除中间1个元素
a = a[:i+copy(a[i:], a[i+N:])] // 删除中间N个元素从尾部删除
a = []int{1, 2, 3}
a = a[:len(a)-1] // 删除尾部1个元素
a = a[:len(a)-N] // 删除尾部N个元素删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况,下面来看一个示例。
删除切片指定位置的元素
package main
import "fmt"
func main() {
seq := []string{"a", "b", "c", "d", "e"}
// 指定删除位置
index := 2
// 查看删除位置之前的元素和之后的元素
fmt.Println(seq[:index], seq[index+1:])
// 将删除点前后的元素连接起来
seq = append(seq[:index], seq[index+1:]...)
fmt.Println(seq)
}代码输出结果:
[a b] [d e]
[a b d e]
代码说明如下:
- 第 1 行,声明一个整型切片,保存含有从 a 到 e 的字符串。
- 第 4 行,为了演示和讲解方便,使用 index 变量保存需要删除的元素位置。
- 第 7 行,seq[:index] 表示的就是被删除元素的前半部分,值为 [1 2],seq[index+1:] 表示的是被删除元素的后半部分,值为 [4 5]。
- 第 10 行,使用 append() 函数将两个切片连接起来。
- 第 12 行,输出连接好的新切片,此时,索引为 2 的元素已经被删除。
代码的删除过程可以使用下图来描述。

图:切片删除元素的操作过程
Go语言中删除切片元素的本质是,以被删除元素为分界点,将前后两个部分的内存重新连接起来。
提示
连续容器的元素删除无论在任何语言中,都要将删除点前后的元素移动到新的位置,随着元素的增加,这个过程将会变得极为耗时,因此,当业务需要大量、频繁地从一个切片中删除元素时,如果对性能要求较高的话,就需要考虑更换其他的容器了(如双链表等能快速从删除点删除元素)。
七.循环迭代切片
range,它可以配合关键字 for 来迭代切片里的每一个元素,如下所示:
// 创建一个整型切片,并赋值
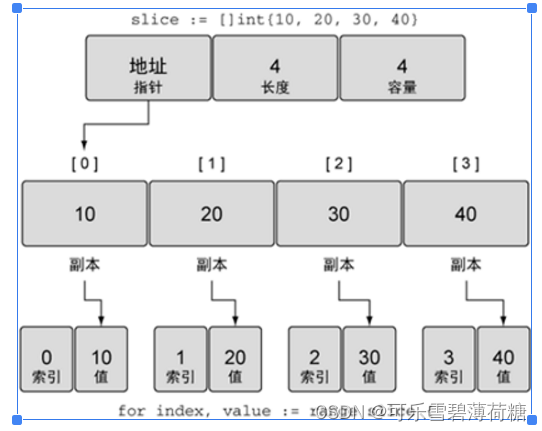
slice := []int{10, 20, 30, 40}
// 迭代每一个元素,并显示其值
for index, value := range slice {
fmt.Printf("Index: %d Value: %d\n", index, value)
}第 4 行中的 index 和 value 分别用来接收 range 关键字返回的切片中每个元素的索引和值,这里的 index 和 value 不是固定的,也可以定义成其它的名字。
上面代码的输出结果为:
Index: 0 Value: 10
Index: 1 Value: 20
Index: 2 Value: 30
Index: 3 Value: 40当迭代切片时,关键字 range 会返回两个值,第一个值是当前迭代到的索引位置,第二个值是该位置对应元素值的一份副本,如下图所示。
需要强调的是,range 返回的是每个元素的副本,而不是直接返回对该元素的引用,如下所示。
【示例 1】range 提供了每个元素的副本
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示值和地址
for index, value := range slice {
fmt.Printf("Value: %d Value-Addr: %X ElemAddr: %X\n", value, &value, &slice[index])
}输出结果为:
Value: 10 Value-Addr: 10500168 ElemAddr: 1052E100
Value: 20 Value-Addr: 10500168 ElemAddr: 1052E104
Value: 30 Value-Addr: 10500168 ElemAddr: 1052E108
Value: 40 Value-Addr: 10500168 ElemAddr: 1052E10C因为迭代返回的变量是一个在迭代过程中根据切片依次赋值的新变量,所以 value 的地址总是相同的,要想获取每个元素的地址,需要使用切片变量和索引值(例如上面代码中的 &slice[index])。
如果不需要索引值,也可以使用下划线_来忽略这个值,代码如下所示。
【示例 2】使用空白标识符(下划线)来忽略索引值
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示其值
for _, value := range slice {
fmt.Printf("Value: %d\n", value)
}
输出结果为:
Value: 10
Value: 20
Value: 30
Value: 40关键字 range 总是会从切片头部开始迭代。如果想对迭代做更多的控制,则可以使用传统的 for 循环,代码如下所示。
【示例 3】使用传统的 for 循环对切片进行迭代
// 创建一个整型切片,并赋值
slice := []int{10, 20, 30, 40}
// 从第三个元素开始迭代每个元素
for index := 2; index < len(slice); index++ {
fmt.Printf("Index: %d Value: %d\n", index, slice[index])
}
输出结果为:
Index: 2 Value: 30
Index: 3 Value: 40八.多维切片
声明一个多维数组的语法格式如下:
var sliceName [][]...[]sliceType其中,sliceName 为切片的名字,sliceType为切片的类型,每个[ ]代表着一个维度,切片有几个维度就需要几个[ ]。
下面以二维切片为例,声明一个二维切片并赋值,代码如下所示。
//声明一个二维切片
var slice [][]int
//为二维切片赋值
slice = [][]int{{10}, {100, 200}}上面的代码也可以简写为下面的样子。
// 声明一个二维整型切片并赋值
slice := [][]int{{10}, {100, 200}}九.Map
Go语言中 map 是一种特殊的数据结构,一种元素对(pair)的无序集合,pair 对应一个 key(索引)和一个 value(值),所以这个结构也称为关联数组或字典,这是一种能够快速寻找值的理想结构,给定 key,就可以迅速找到对应的 value。
map 这种数据结构在其他编程语言中也称为字典(Python)、hash 和 HashTable 等。
(1.)map 概念
map 是引用类型,可以使用如下方式声明:
var mapname map[keytype]valuetype其中:
- mapname 为 map 的变量名。
- keytype 为键类型。
- valuetype 是键对应的值类型。
提示:[keytype] 和 valuetype 之间允许有空格。
在声明的时候不需要知道 map 的长度,因为 map 是可以动态增长的,未初始化的 map 的值是 nil,使用函数 len() 可以获取 map 中 pair 的数目。
【示例】
package main
import "fmt"
func main() {
var mapLit map[string]int
//var mapCreated map[string]float32
var mapAssigned map[string]int
mapLit = map[string]int{"one": 1, "two": 2}
mapCreated := make(map[string]float32)
mapAssigned = mapLit
mapCreated["key1"] = 4.5
mapCreated["key2"] = 3.14159
mapAssigned["two"] = 3
fmt.Printf("Map literal at \"one\" is: %d\n", mapLit["one"])
fmt.Printf("Map created at \"key2\" is: %f\n", mapCreated["key2"])
fmt.Printf("Map assigned at \"two\" is: %d\n", mapLit["two"])
fmt.Printf("Map literal at \"ten\" is: %d\n", mapLit["ten"])
}
输出结果:
Map literal at "one" is: 1
Map created at "key2" is: 3.14159
Map assigned at "two" is: 3
Map literal at "ten" is: 0示例中 mapLit 演示了使用{key1: value1, key2: value2}的格式来初始化 map ,就像数组和结构体一样。
上面代码中的 mapCreated 的创建方式mapCreated := make(map[string]float)等价于mapCreated := map[string]float{} 。
mapAssigned 是 mapList 的引用,对 mapAssigned 的修改也会影响到 mapLit 的值。
注意:可以使用 make(),但不能使用 new() 来构造 map,如果错误的使用 new() 分配了一个引用对象,会获得一个空引用的指针,相当于声明了一个未初始化的变量并且取了它的地址:
mapCreated := new(map[string]float)
接下来当我们调用mapCreated["key1"] = 4.5的时候,编译器会报错:
invalid operation: mapCreated["key1"] (index of type *map[string]float).
(2).map 容量
和数组不同,map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity,格式如下:
make(map[keytype]valuetype, cap)例如:
map2 := make(map[string]float, 100)当 map 增长到容量上限的时候,如果再增加新的 key-value,map 的大小会自动加 1,所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
这里有一个 map 的具体例子,即将音阶和对应的音频映射起来:
noteFrequency := map[string]float32 {
"C0": 16.35, "D0": 18.35, "E0": 20.60, "F0": 21.83,
"G0": 24.50, "A0": 27.50, "B0": 30.87, "A4": 440}(3).用切片作为 map 的值
既然一个 key 只能对应一个 value,而 value 又是一个原始类型,那么如果一个 key 要对应多个值怎么办?例如,当我们要处理 unix 机器上的所有进程,以父进程(pid 为整形)作为 key,所有的子进程(以所有子进程的 pid 组成的切片)作为 value。通过将 value 定义为 []int 类型或者其他类型的切片,就可以优雅的解决这个问题,示例代码如下所示:
mp1 := make(map[int][]int)
mp2 := make(map[int]*[]int)(4).Go语言遍历Map
map 的遍历过程使用 for range 循环完成,代码如下:
scene := make(map[string]int)
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
for k, v := range scene {
fmt.Println(k, v)
}遍历对于Go语言的很多对象来说都是差不多的,直接使用 for range 语法即可,遍历时,可以同时获得键和值,如只遍历值,可以使用下面的形式:
for _, v := range scene {将不需要的键使用_改为匿名变量形式。
只遍历键时,使用下面的形式:
for k := range scene {无须将值改为匿名变量形式,忽略值即可。
注意:遍历输出元素的顺序与填充顺序无关,不能期望 map 在遍历时返回某种期望顺序的结果。
如果需要特定顺序的遍历结果,正确的做法是先排序,代码如下:
scene := make(map[string]int)
// 准备map数据
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
// 声明一个切片保存map数据
var sceneList []string
// 将map数据遍历复制到切片中
for k := range scene {
sceneList = append(sceneList, k)
}
// 对切片进行排序
sort.Strings(sceneList)
// 输出
fmt.Println(sceneList)
代码输出如下:
[brazil china route]代码说明如下:
- 第 1 行,创建一个 map 实例,键为字符串,值为整型。
- 第 4~6 行,将 3 个键值对写入 map 中。
- 第 9 行,声明 sceneList 为字符串切片,以缓冲和排序 map 中的所有元素。
- 第 12 行,将 map 中元素的键遍历出来,并放入切片中。
- 第 17 行,对 sceneList 字符串切片进行排序,排序时,sceneList 会被修改。
- 第 20 行,输出排好序的 map 的键。
sort.Strings 的作用是对传入的字符串切片进行字符串字符的升序排列
(5).map元素的删除和清空
Go语言提供了一个内置函数 delete(),用于删除容器内的元素,下面我们简单介绍一下如何用 delete() 函数删除 map 内的元素。
使用 delete() 函数从 map 中删除键值对
使用 delete() 内建函数从 map 中删除一组键值对,delete() 函数的格式如下:
delete(map, 键)
其中 map 为要删除的 map 实例,键为要删除的 map 中键值对的键。
从 map 中删除一组键值对可以通过下面的代码来完成:
scene := make(map[string]int)
// 准备map数据
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
delete(scene, "brazil")
for k, v := range scene {
fmt.Println(k, v)
}代码输出如下:
route 66 china 960
这个例子中使用 delete() 函数将 brazil 从 scene 这个 map 中删除了。
(6).清空 map 中的所有元素
有意思的是,Go语言中并没有为 map 提供任何清空所有元素的函数、方法,清空 map 的唯一办法就是重新 make 一个新的 map,不用担心垃圾回收的效率,Go语言中的并行垃圾回收效率比写一个清空函数要高效的多。
(7).sync.map
Go语言中的 map 在并发情况下,只读是线程安全的,同时读写是线程不安全的。
下面来看下并发情况下读写 map 时会出现的问题,代码如下:
// 创建一个int到int的映射
m := make(map[int]int)
// 开启一段并发代码
go func() {
// 不停地对map进行写入
for {
m[1] = 1
}
}()
// 开启一段并发代码
go func() {
// 不停地对map进行读取
for {
_ = m[1]
}
}()
// 无限循环, 让并发程序在后台执行
for {
}
运行代码会报错,输出如下:
fatal error: concurrent map read and map write错误信息显示,并发的 map 读和 map 写,也就是说使用了两个并发函数不断地对 map 进行读和写而发生了竞态问题,map 内部会对这种并发操作进行检查并提前发现。
需要并发读写时,一般的做法是加锁,但这样性能并不高,Go语言在 1.9 版本中提供了一种效率较高的并发安全的 sync.Map,sync.Map 和 map 不同,不是以语言原生形态提供,而是在 sync 包下的特殊结构。
sync.Map 有以下特性:
- 无须初始化,直接声明即可。
- sync.Map 不能使用 map 的方式进行取值和设置等操作,而是使用 sync.Map 的方法进行调用,Store 表示存储,Load 表示获取,Delete 表示删除。
- 使用 Range 配合一个回调函数进行遍历操作,通过回调函数返回内部遍历出来的值,Range 参数中回调函数的返回值在需要继续迭代遍历时,返回 true,终止迭代遍历时,返回 false。
并发安全的 sync.Map 演示代码如下:
package main
import (
"fmt"
"sync"
)
func main() {
var scene sync.Map
// 将键值对保存到sync.Map
scene.Store("greece", 97)
scene.Store("london", 100)
scene.Store("egypt", 200)
// 从sync.Map中根据键取值
fmt.Println(scene.Load("london"))
// 根据键删除对应的键值对
scene.Delete("london")
// 遍历所有sync.Map中的键值对
scene.Range(func(k, v interface{}) bool {
fmt.Println("iterate:", k, v)
return true
})
}
代码输出如下:
100 true
iterate: egypt 200
iterate: greece 97代码说明如下:
- 第 10 行,声明 scene,类型为 sync.Map,注意,sync.Map 不能使用 make 创建。
- 第 13~15 行,将一系列键值对保存到 sync.Map 中,sync.Map 将键和值以 interface{} 类型进行保存。
- 第 18 行,提供一个 sync.Map 的键给 scene.Load() 方法后将查询到键对应的值返回。
- 第 21 行,sync.Map 的 Delete 可以使用指定的键将对应的键值对删除。
- 第 24 行,Range() 方法可以遍历 sync.Map,遍历需要提供一个匿名函数,参数为 k、v,类型为 interface{},每次 Range() 在遍历一个元素时,都会调用这个匿名函数把结果返回。
sync.Map 没有提供获取 map 数量的方法,替代方法是在获取 sync.Map 时遍历自行计算数量,sync.Map 为了保证并发安全有一些性能损失,因此在非并发情况下,使用 map 相比使用 sync.Map 会有更好的性能。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









