







Mybatis
- Mybatis知识点
- 1.什么是三层架构
- 2.生活中的三层架构
- 3.常用的框架SSM.
- 4.什么是框架
- 5.什么是MyBatis框架
- 6.添加框架的步骤
- 7.MyBatis对象分析
- 8.为实体类注册别名
- 9.设置日志输出
- 10.动态代理存在意义
- 11.动态代理访问的步骤
- 12.优化mapper.xml文件注册
- 13.#{}占位符
- 14.${}字符串拼接或字符串替换
- 15.返回主键值
- 16.UUID
- 17.什么是动态sql
- 18.指定参数位置
- 19.入参个数 > 1、入参是map(重点掌握)
- 20.返回值是map、resultType与resultMap;入参parameterType
- 21.表之间的关联关系
- 22.一对多关联关系
- 23.多对一关联关系.(即重点放在多的一方,多就是主表)
- 24.一对一关联
- 25.多对多关联
- 26.事务
- 27.缓存
- 28.什么是ORM
- 29.整体思路、总结
Mybatis知识点
1.什么是三层架构
在项目开发中,遵循的一种形式模式.分为三层.
1)界面层:用来接收客 户端的输入,调用业务逻辑层进行功能处理,返回结果给客户端.过去的servlet就是界面层的功能.
2)业务逻辑层:用来进行整个项目的业务逻辑处理,向上为界面层提供处理结果,向下问数据访问层要数据.
3)数据访问层:专门用来进行数据库的增删改查操作,向上为业务逻辑层提供数据.
各层之间的调用顺序是固定的,不允许跨层访问.
界面层<------->业务逻辑层<------>数据访问层
2.生活中的三层架构
3.常用的框架SSM.
Spring:它是整合其它框架的框架.它的核心是IOC和AOP.它由20多个模块构成.在很多领域都提供了很好的解决方案.是一个大佬级别的存在.
SpringMVC:它是Spring家族的一员.专门用来优化控制器(Servlet)的.提供了极简单数据提交,数据携带,页面跳转等功能.
MyBatis:是持久化层的一个框架.用来进行数据库访问的优化.专注于sql语句.极大的简化了JDBC的访问.
4.什么是框架
它是一个半成品软件.将所有的公共的,重复的功能解决掉,帮助程序快速高效的进行开发.它是可复用,可扩展的.
5.什么是MyBatis框架
MyBatis 本是 apache 的一个开源项目iBatis, 2010 年这个项目由 apache software foundation 迁移到了 google code,并且改名为 MyBatis 。2013 年 11 月迁移到 Github,最新版本是 MyBatis 3.5.7 ,其发布时间是 2021 年 4月 7日。
MyBatis完成数据访问层的优化.它专注于sql语句.简化了过去JDBC繁琐的访问机制.
6.添加框架的步骤
1)添加依赖
2)添加配置文件
具体步骤:
1.新建库建表
2.新建maven项目,选quickstart模板
3.修改目录,添加缺失的目录,修改目录属性
注意,放到resources目录下的文件相当于放入到了类的根路径下,在sqlMapConfig.xml中,比如读取属性文件
<!--1、读取jdbc.properties属性文件-->
<properties resource="jdbc.properties"></properties>
用resource属性会自动从类的根路径下开始查找资源,这可以作为一个技巧,看到resource,大部分就是从类的根路径下加载,比如:
jdbc.properties文件正好也在根目录下,所以直接写名字就可以,不用再写其他路径
4.修改pom.xml文件,添加MyBatis的依赖,添加mysql的依赖
<!--添加MyBatis框架的依赖-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--添加mysql依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.32</version>
</dependency>
5.修改pom.xml文件,添加资源文件指定
6.在idea中添加数据库的可视化
7.添加jdbc.properties属性文件(数据库的配置)
8.添加SqlMapConfig.xml文件,MyBatis的核心配置文件
9.创建实体类Student,用来封装数据
10)、添加完成学生表的增删改查的功能的StudentMapper.xml文件
注意这个文件是要在sqlMapConfig中去配置的:下面是全都配了
<!--5、注册mapper.xml,使用接口的完全限定名来注册-->
<mappers>
<!--<mapper class="cn.edu.uestc.mapper.StudentMapper"></mapper>-->
<!--批量注册-->
<package name="cn.edu.uestc.mapper"/>
</mappers>
StudentMapper.xml文件如下:
<mapper namespace="zar">
<!--
完成查询全部学生的功能
List<Student> getALL();
resultType:指定查询返回的结果集的类型,如果是集合,则必须是泛型的类型
parameterType:如果有参数,则通过它来指定参数的类型
-->
<select id="getAll" resultType="com.bjpowernode.pojo.Student" >
select id,name,email,age
from student
</select>
<!--
按主键id查询学生信息
Student getById(Integer id);
-->
<select id="getById" parameterType="int" resultType="com.bjpowernode.pojo.Student">
select id,name,email,age
from student
where id=#{id}
</select>
<!--
按学生名称模糊查询
List<Student> getByName(String name);
-->
<select id="getByName" parameterType="string" resultType="com.bjpowernode.pojo.Student">
select id,name,email,age
from student
where name like '%${name}%'
</select>
<!--
增加学生
int insert(Student stu);
实体类:
private Integer id;
private String name;
private String email;
private Integer age;
-->
<insert id="insert" parameterType="com.bjpowernode.pojo.Student">
insert into student (name,email ,age) values(#{name},#{email},#{age})
</insert>
<!--
按主键删除学生
int delete(Integer id);
-->
<delete id="delete" parameterType="int" >
delete from student where id=#{id}
</delete>
<!--
更新学生
int update(Student stu);
-->
<update id="update" parameterType="com.bjpowernode.pojo.Student">
update student set name=#{name},email=#{email},age=#{age}
where id=#{id}
</update>
</mapper>
测试类
@Test
public void testUpdate()throws IOException {
//1.使用流读取核心配置文件
InputStream in = Resources.getResourceAsStream("SqlMapConfig.xml");
//2.创建SqlSessionFactory工厂对象
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
//3.取出SqlSession
SqlSession sqlSession = factory.openSession();
//4.调用方法
int num = sqlSession.update("zar.update",new Student(3,"hehe","hehe@126.com",30));
System.out.println(num);
sqlSession.commit();
sqlSession.close();
}
11.创建测试类,进行功能测试
测试代码如下:
public class MyTest {
SqlSession sqlSession;
//动态代理对象
UsersMapper usersMapper;
//日期的格式化刷子
//SimpleDateFormat下:format()方法把日期变字符串;parse()方法就是把字符串变日期;
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");//注意MM大写,和分钟mm区分开!
@Before
public void openSqlSessoion() throws IOException {
//1、读取核心配置文件,其实读完就是一个流
//Resources.getResourceAsStream只不过是方便从当前项目中直接获取,本质上还是个流
InputStream ins = Resources.getResourceAsStream("SqlMapConfig.xml");
//2、创建工厂(要从工厂中拿到sqlSession,一般一个数据库一个SqlSessionFactory)
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(ins);
//3、打开sqlSession
sqlSession = factory.openSession(true);
/**
* 大重点
* 取出动态代理对象,完成接口中方法的调用,实际是调用xml文件中相关标签的功能!!
*/
usersMapper = sqlSession.getMapper(UsersMapper.class);
}
@After
public void closeSession(){
sqlSession.close();
}
@Test
public void testGetAll(){
System.out.println(usersMapper.getClass());//class com.sun.proxy.$Proxy6 这就是动态代理对象
List<Users> list = usersMapper.getAll();
list.forEach(users-> System.out.println(users));
}
7.MyBatis对象分析
1)Resources类
就是解析SqlMapConfig.xml文件,创建出相应的对象
InputStream in = Resources.getResourceAsStream(“SqlMapConfig.xml”);
2)SqlSessionFactory接口
使用ctrl+h快捷键查看本接口的子接口及实现类
DefaultSqlSessionFactory是实现类
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(in);
3)SqlSession接口
DefaultSqlSession实现类
8.为实体类注册别名
注意:所有别名不区分大小写哦; 配置文件中的nameSpace 必须是使用接口的全限定名称,不可以写别名!
1)单个注册
<typeAlias type="com.bjpowernode.pojo.Student" alias="student"></typeAlias>
2)批量注册
<!--<typeAlias type="com.bjpowernode.pojo.Student" alias="student"></typeAlias>-->
<!--批量注册别名
别名是类名的驼峰命名法(规范)
-->
<package name="com.bjpowernode.pojo"></package>
9.设置日志输出
<!--设置日志输出底层执行的代码-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
10.动态代理存在意义
在三层架构中,业务逻辑层要通过接口访问数据访问层的功能.动态代理可以实现.
动态代理的实现规范:
1)UsersMapper.xml文件与UsersMapper.java的接口必须同一个目录下.
2)UsersMapper.xml文件与UsersMapper.java的接口的文件名必须一致,后缀不管.
3)UserMapper.xml文件中标签的id值与与UserMapper.java的接口中方法的名称完全一致.
4)UserMapper.xml文件中标签的parameterType属性值与与UserMapper.java的接口中方法的参数类型完全一致.
5)UserMapper.xml文件中标签的resultType值与与UserMapper.java的接口中方法的返回值类型完全一致.
6)UserMapper.xml文件中namespace属性必须是接口的完全限定名称com.bjpowernode.mapper.UsersMapper
7)在SqlMapConfig.xml文件中注册mapper文件时,使用class=接口的完全限定名称com.bjpowernode.mapper.UsersMapper.
11.动态代理访问的步骤
1)建表Users
2)新建maven工程,刷新可视化
3)修改目录
4)修改pom.xml文件,添加依赖
5)添加jdbc.propertis文件到resources目录下
6)添加SqlMapConfig.xml文件
7)添加实体类
8)添加mapper文件夹,新建UsersMapper接口
9)在mapper文件夹下,新建UsersMapper.xml文件,完成增删改查功能
10)添加测试类,测试功能
12.优化mapper.xml文件注册
mybatis-config.xml文件中的mappers标签。
<mapper resource="CarMapper.xml"/> 要求类的根路径下必须有:CarMapper.xml
<mapper url="file:///d:/CarMapper.xml"/> 要求在d:/下有CarMapper.xml文件
<mapper class="全限定接口名,带有包名"/>
mapper标签的属性可以有三个:
-
resource:这种方式是从类的根路径下开始查找资源。采用这种方式的话,你的配置文件需要放到类路径当中才行。
-
url:这种方式是一种绝对路径的方式,这种方式不要求配置文件必须放到类路径当中,哪里都行,只要提供一个绝对路径就行。这种方式使用极少,因为移植性太差。
-
class: 这个位置提供的是mapper接口的全限定接口名,必须带有包名的。
思考:mapper标签的作用是指定SqlMapper.xml文件的路径,指定接口名有什么用呢?
<mapper class="com.powernode.mybatis.mapper.CarMapper"/>
如果你class指定是:com.powernode.mybatis.mapper.CarMapper
那么mybatis框架会自动去com/powernode/mybatis/mapper目录下查找CarMapper.xml文件。
注意:也就是说:如果你采用这种方式,那么你必须保证CarMapper.xml文件和CarMapper接口必须在同一个目录下。并且名字一致。(resources目录和java目录都是类的根路径)
CarMapper接口-> CarMapper.xml
LogMapper接口-> LogMapper.xml
…
<!--注册mapper.xml文件-->
<mappers>
<!--绝对路径注册-->
<mapper url="/"></mapper>
<!--非动态代理方式下的注册-->
<mapper resource="StudentMapper.xml"></mapper>
<!--动态代理方式下的单个mapper.xml文件注册-->
<mapper class="com.bjpowernode.mapper.UsersMapper"></mapper>
<!--批量注册-->
<package name="com.bjpowernode.mapper"></package>
</mappers>
13.#{}占位符
传参大部分使用#{}传参,它的底层使用的是PreparedStatement对象,是安全的数据库访问 ,防止sql注入.
#{}里如何写,看parameterType参数的类型
1)如果parameterType的类型是简单类型(8种基本(封装)+String),则#{}里随便写.
<select id="getById" parameterType="int" resultType="users"> ===>入参类型是简单类型
select id,username,birthday,sex,address
from users
where id=#{zar} ===>随便写
</select>
2)parameterType的类型是实体类的类型,则#{}里只能是类中成员变量的名称,而且区分大小写.
<insert id="insert" parameterType="users" > ===>入参是实体类
insert into users (username, birthday, sex, address) values(#{userName},#{birthday},#{sex},#{address}) ==>成员变量名称
</insert>
3)不能使用#{}的地方:首先清楚,#{}就是一个占位符 ? 如果遇到这样的情况:
select sal from emp by sal #{} 这时候外部插入的值比如是asc 或desc 是String类型的。那结果语句会编程: select sal from emp by sal 'desc' 多了两个引号,语法错误。(所以记住它只是传值,只是占位符,来String的就把string传过去,String 类型的就带引号,这时候就要用下面的字符串拼接)。
反正记住,只有${} 是字符串拼接,结果在sql语句中是没有‘’引号的,而大部分其实需要引号,比如根据名字查信息的时候,名字用 #{} 传入或者模糊查询传入,在sql语句中都需‘’
14.${}字符串拼接或字符串替换
使用的例子:
现实业务中,一张表数据量太大,查询效率底。
现在每天以当天的日期作为名称生成每天的表。这样一张表就存一天的信息,查询效率就高了。
这样查表也方便了,外面输入日期信息进行拼接,就能查到对应日期的表。
1)字符串拼接,一般用于模糊查询中.建议少用,因为有sql注入的风险.
也分两种情况,同样的看parameterType的类型
A. 如果parameterType的类型是简单类型,则${}里随便写,但是分版本,如果是3.5.1及以下的版本,只以写value.
<select id="getByName" parameterType="string" resultType="users"> ===>入参是简单类型
select id,username,birthday,sex,address
from users
where username like '%${zar}%' ===>随便写
</select>
B. 如果parameterType的类型是实体类的类型,则`${}`里只能是类中成员变量的名称.(现在已经少用)
C. 优化后的模糊查询(以后都要使用这种方式)
模糊查询一共四种方法:
需求:根据汽车品牌进行模糊查询
select * from t_car where brand like ‘%奔驰%’;
select * from t_car where brand like ‘%比亚迪%’;
第一种方案:
'%${brand}%'
第二种方案:concat函数,这个是mysql数据库当中的一个函数,专门进行字符串拼接
concat('%',#{brand},'%')
第三种方案:比较鸡肋了。可以不算。
concat('%','${brand}','%')
第四种方案:(使用最多)
"%"#{brand}"%"
<select id="getByNameGood" parameterType="string" resultType="users">
select id,username,birthday,sex,address
from users
where username like concat('%',#{name},'%')
</select>
2)字符串替换
需求:模糊地址或用户名查询
select * from users where username like ‘%小%’;
select * from users where address like ‘%市%’
<!--
//模糊用户名和地址查询
//如果参数超过一个,则parameterType不写
List<Users> getByNameOrAddress(
@Param("columnName") ===>为了在sql语句中使用的名称
String columnName,
@Param("columnValue") ===>为了在sql语句中使用的名称
String columnValue);
-->
<select id="getByNameOrAddress" resultType="users">
select id,username,birthday,sex,address
from users
where ${columnName} like concat('%',#{columnValue},'%') ==>此处使用的是@Param注解里的名称
</select>
15.返回主键值
在插入语句结束后, 返回自增的主键值到入参的users对象的id属性中. useGeneratedKeys自动生成的主键值
应用场景:涉及到多表的连接查询时,在第一张表插入信息时,由于主键经常是自增,自己产生的,我们不知道。而在副表中也许需要用到该主键,就要返回该主键值。
<insert id="insert" parameterType="users" >
<selectKey keyProperty="id" resultType="int" order="AFTER">
select last_insert_id()
</selectKey>
insert into users (username, birthday, sex, address) values(#{userName},#{birthday},#{sex},#{address})
</insert>
<selectKey>标签的参数详解:
keyProperty: users对象的哪个属性来接返回的主键值
resultType:返回的主键的类型
order:在插入语句执行前,还是执行后返回主键的值
<!--
第二种写法:
useGeneratedKeys="true" 使用自动生成的主键值。
keyProperty="id" 指定主键值赋值给对象的哪个属性。这个就表示将主键值赋值给Car对象的id属性。
-->
<insert id="insertCarUseGeneratedKeys" useGeneratedKeys="true" keyProperty="id">
insert into t_car values(null,#{carNum},#{brand},#{guidePrice},#{produceTime},#{carType})
</insert>
16.UUID
这是一个全球唯一随机字符串,由36个字母数字中划线组.
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString().replace(“-”,“”).substring(20));
17.什么是动态sql
可以定义代码片断,可以进行逻辑判断,可以进行循环处理(批量处理),使条件判断更为简单.
1)<sql>:用来定义代码片断,可以将所有的列名,或复杂的条件定义为代码片断,供使用时调用.
2)<include>:用来引用<sql>定义的代码片断.
<!--定义代码片断-->
<sql id="allColumns">
id,username,birthday,sex,address
</sql>
//引用定义好的代码片断
<select id="getAll" resultType="users" >
select <include refid="allColumns"></include>
from users
</select>
3)<if>:进行条件判断
test条件判断的取值可以是实体类的成员变量,可以是map的key,可以是**@Param注解的名称**.
1. if标签中test属性是必须的。
2. if标签中test属性的值是false或者true。
3. 如果test是true,则if标签中的sql语句就会拼接。反之,则不会拼接。
4. test属性中可以使用的是:
当使用了@Param注解(Mapper接口中),那么test中要出现的是@Param注解指定的参数名。@Param(“brand”),那么这里只能使用brand
当没有使用@Param注解,那么test中要出现的是:param1 param2 param3 arg0 arg1 arg2…
当使用了POJO,那么test中出现的是POJO类的属性名。
你出现的错误:用#{name} 这里不用传值,而是名字就好
5. 在mybatis的动态SQL当中,不能使用&&,只能使用and。
4)<where>:进行多条件拼接,在查询,删除,更新中使用.
where 标签能够自动去除多余的and 所以在子语句中,可以全部加上and(语句前面加,在后面加不行)
<select id="getByCondition" parameterType="users" resultType="users">
select <include refid="allColumns"></include>
from users
<where>
<if test="userName != null and userName != ''">
and username like concat('%',#{userName},'%')
</if>
<if test="birthday != null">
and birthday = #{birthday}
</if>
<if test="sex != null and sex != ''">
and sex = #{sex}
</if>
<if test="address != null and address != ''">
and address like concat('%',#{address},'%')
</if>
</where>
</select>
5)<set>:有选择的进行更新处理,至少更新一列.能够保证如果没有传值进来,则数据库中的数据保持不变.
update语句中使用,如果里面嵌套的if语句没有一个test成立,
<update id="updateBySet" parameterType="users">
update users
<set>
<if test="userName != null and userName != ''">
username = #{userName},
</if>
<if test="birthday != null">
birthday = #{birthday},
</if>
<if test="sex != null and sex != ''">
sex = #{sex},
</if>
<if test="address != null and address != ''">
address =#{address} ,
</if>
</set>
where id = #{id}
</update>
6)<foreach>:用来进行循环遍历,完成循环条件查询,批量删除,批量增加,批量更新.
查询实现
<select id="getByIds" resultType="users">
select <include refid="allColumns"></include>
from users
where id in
<foreach collection="array" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</select>
<foreach>参数详解:
collection:用来指定入参的类型,如果是List集合,则为list,如果是Map集合,则为map,如果是数组,则为array.
item:每次循环遍历出来的值或对象
separator:多个值或对象或语句之间的分隔符
open:整个循环外面的前括号
close:整个循环外面的后括号
批量删除实现
<delete id="deleteBatch" >
delete from users
where id in
<foreach collection="array" item="id" separator="," open="(" close=")">
#{id}
</foreach>
</delete>
批量增加实现
<insert id="insertBatch">
insert into users(username, birthday, sex, address) values
<foreach collection="list" item="u" separator="," >
(#{u.userName},#{u.birthday},#{u.sex},#{u.address})
</foreach>
</insert>
7)<trim>:可以设置该标签内的内容添加前缀、后缀
如果全部if标签的if条件都不满足,where标签自动不拼接。另外有些不必要的后缀也自动不拼接
<select id="selectByMultiConditionWithTrim" resultType="Car">
select * from t_car
<!--
prefix:加前缀
suffix:加后缀
prefixOverrides:删除前缀
suffixOverrides:删除后缀
-->
<!--prefix="where" 是在trim标签所有内容的前面添加 where-->
<!--suffixOverrides="and|or" 把trim标签中内容的后缀and或or去掉-->
<trim prefix="where" suffixOverrides="and|or">
<if test="brand != null and brand != ''">
brand like "%"#{brand}"%" or
</if>
<if test="guidePrice != null and guidePrice != ''">
guide_price > #{guidePrice} and
</if>
<if test="carType != null and carType != ''">
car_type = #{carType}
</if>
</trim>
</select>
18.指定参数位置
如果入参是多个,可以通过:指定参数位置 进行传。是实体包含不住的条件.实体类只能封装住成员变量的条件.如果某个成员变量要有区间范围内的判断,或者有两个值进行处理,则实体类包不住.
例如:查询指定日期范围内的用户信息.
<!--
//查询指定日期范围内的用户
List<Users> getByBirthday(Date begin, Date end);
-->
<select id="getByBirthday" resultType="users">
select <include refid="allColumns"></include>
from users
where birthday between #{arg0} and #{arg1}
</select>
19.入参个数 > 1、入参是map(重点掌握)
如果入参超过一个以上,使用map封装查询条件,更有语义,查询条件更明确.
应用场景:
1、根据名字和性别查询
2、查询生日在xxxx ---- xxxx之间的user数据(思路是where birthday between #{begin} and #{end})
3、分页查询 limit startIndex,pageSize(注:startIndex = (pageNumber - 1)*pageSize),pageNumber是第几页,pagesize是每页显示的记录条数
上面这三种情况入参都 >1 parameterType包不足了,使用map封装查询条。
1、多个参数底层实现原理:
- 如果是多个参数的话,mybatis框架底层是怎么做的呢?
mybatis框架会自动创建一个Map集合。并且Map集合是以这种方式存储参数的:
map.put(“arg0”, name);
map.put(“arg1”, sex);
map.put(“param1”, name);
map.put(“param2”, sex);
map的value就是传入参数的值,在mapper接口类中就是形参,key的名字不修改的话,默认是arg0…
<select id="selectByNameAndSex" resultType="Student">
<!--select * from t_student where name = #{arg0} and sex = #{arg1}-->
<!--select * from t_student where name = #{param1} and sex = #{param2}-->
select * from t_student where name = #{arg0} and sex = #{param2}
</select>
2、@Param
如果不想用arg0、arg1,想自己指定名字:在xxxMapper中使用@Param
List<Student> selectByNameAndSex2(
@Param("name") String name,
@Param("sex") Character sex);
<select id="selectByNameAndSex2" resultType="Student">
<!--使用了@Param注解之后,arg0和arg1失效了-->
<!--select * from t_student where name = #{arg0} and sex = #{arg1}-->
<!--使用了@Param注解之后,param1和param2还可以用-->
<!--select * from t_student where name = #{param1} and sex = #{param2}-->
select * from t_student where name = #{name} and sex = #{sex}
</select>
@Test
public void testSelectByNameAndSex2(){
SqlSession sqlSession = SqlSessionUtil.openSession();
// mapper实际上指向了代理对象
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
// mapper是代理对象
// selectByNameAndSex2是代理方法
List<Student> students = mapper.selectByNameAndSex2("张三", '男');
students.forEach(student -> System.out.println(student));
sqlSession.close();
}
3、入参是map使用示例:
入参是map也可以用于解决多个参数查询的问题,只要注意xxxxMapper.xml中 占位符:#{map的key}就可以自动识别!
<!--
入参是map:
List<Users> getByMap(Map map);
#{birthdayBegin}:就是map中的key,作为xml文件中的占位符
-->
<select id="getByMap" resultType="users" >
select <include refid="allColumns"></include>
from users
where birthday between #{birthdayBegin} and #{birthdayEnd}
</select>
测试类中
@Test
public void testGetByMap() throws ParseException {
Date begin = sf.parse("1999-01-01");
Date end = sf.parse("1999-12-31");
Map map = new HashMap<>();
map.put("birthdayBegin",begin);
map.put("birthdayEnd", end);
List<Users> list = uMapper.getByMap(map);
list.forEach(users -> System.out.println(users));
}
4、当然,一个入参也可以用map:(注意#{里面是map的key})
个人感觉用的不是很多?因为一般插入数据入参都是实体类然后自动识别
<!--<insert id="insertStudentByMap" parameterType="map">-->
<insert id="insertStudentByMap">
insert into t_student(id,name,age,sex,birth,height) values(null,#{姓名},#{年龄},#{性别},#{生日},#{身高})
</insert>
测试程序:
@Test
public void testInsertStudentByMap(){
SqlSession sqlSession = SqlSessionUtil.openSession();
StudentMapper mapper = sqlSession.getMapper(StudentMapper.class);
Map<String,Object> map = new HashMap<>();
map.put("姓名", "赵六");
map.put("年龄", 20);
map.put("身高", 1.81);
map.put("性别", '男');
map.put("生日", new Date());
mapper.insertStudentByMap(map);
sqlSession.commit();
sqlSession.close();
}
20.返回值是map、resultType与resultMap;入参parameterType
parameterType:
parameterType属性的作用:
告诉mybatis框架,我这个方法的参数类型是什么类型。
mybatis框架自身带有类型自动推断机制,所以大部分情况下parameterType属性都是可以省略不写的。
SQL语句最终是这样的:
select * from t_student where id = ?
JDBC代码是一定要给?传值的。
怎么传值?ps.setXxx(第几个问号, 传什么值);
ps.setLong(1, 1L);
ps.setString(1, "zhangsan");
ps.setDate(1, new Date());
ps.setInt(1, 100);
...
mybatis底层到底调用setXxx的哪个方法,取决于parameterType属性的值。
注意:
1、mybatis框架实际上内置了很多别名。可以参考开发手册。
2、Date类型也是简单类型,parameterType也可以省略,但是在比如 根据生日搜索 传入的类型应该和建表时一直,使用Date类型的(simpleDateFormate 有parse()方法,可以将字符串类型转为Date类型)
resultType:
resultType可以把查询结果封装到pojo类型中,但必须pojo类的属性名和查询到的数据库表的字段名一致。
如果sql查询到的字段与pojo的属性名不一致,则需要使用resultMap将字段名和属性名对应起来,进行手动配置封装,将结果映射到pojo中
resultMap:
resultMap可以实现将查询结果映射为复杂类型的pojo,比如在查询结果映射对象中包括pojo和list实现一对一查询和一对多查询。
如果返回的数据实体类无法包含,可以使用map返回多张表中的若干数据.返回后这些数据之间没有任何关系.就是Object类型.返回的map的key就是列名或别名.
<!--
//返回值是map(一行)
Map getReturnMap(Integer id);
-->
<select id="getReturnMap" parameterType="int" resultType="map">
select username nam,address a
from users
where id=#{id}
</select>
<!--
//返回多行的map
List<Map> getMulMap();
-->
<select id="getMulMap" resultType="map">
select username,address
from users
</select>
21.表之间的关联关系
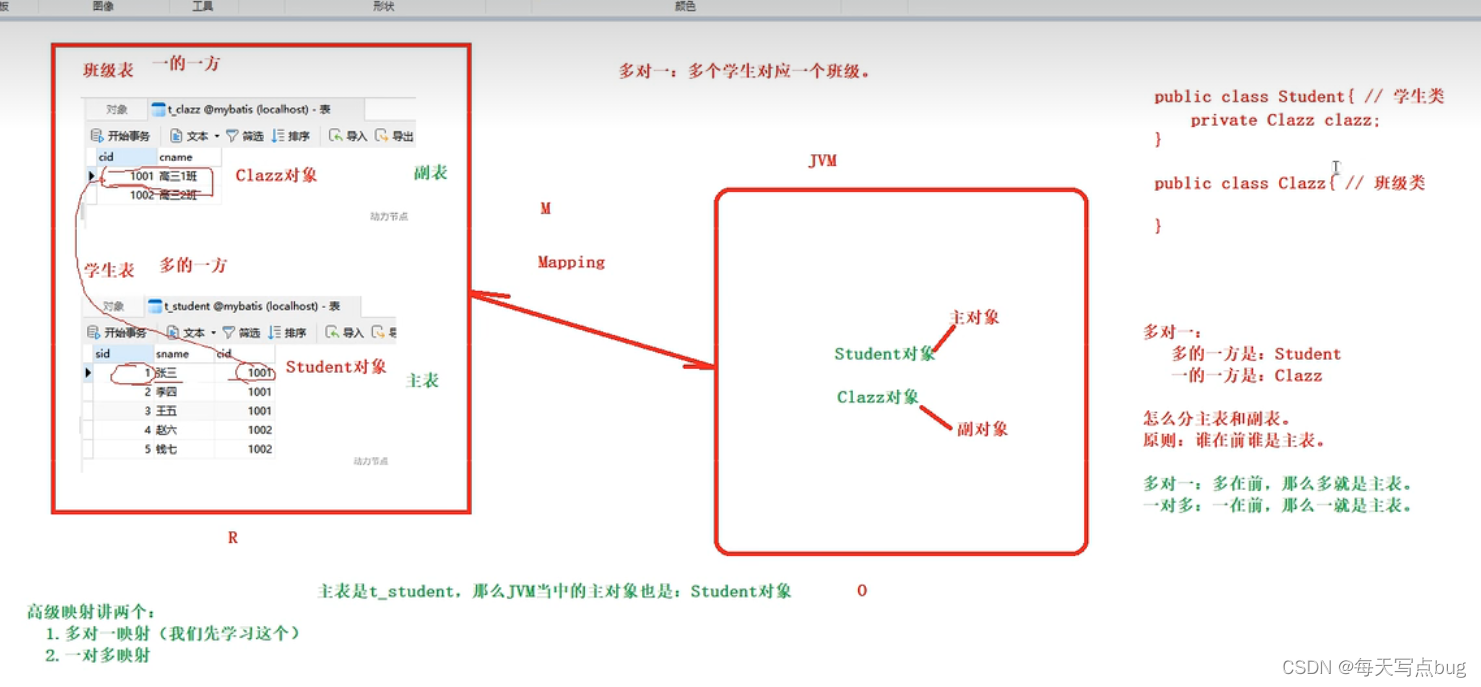
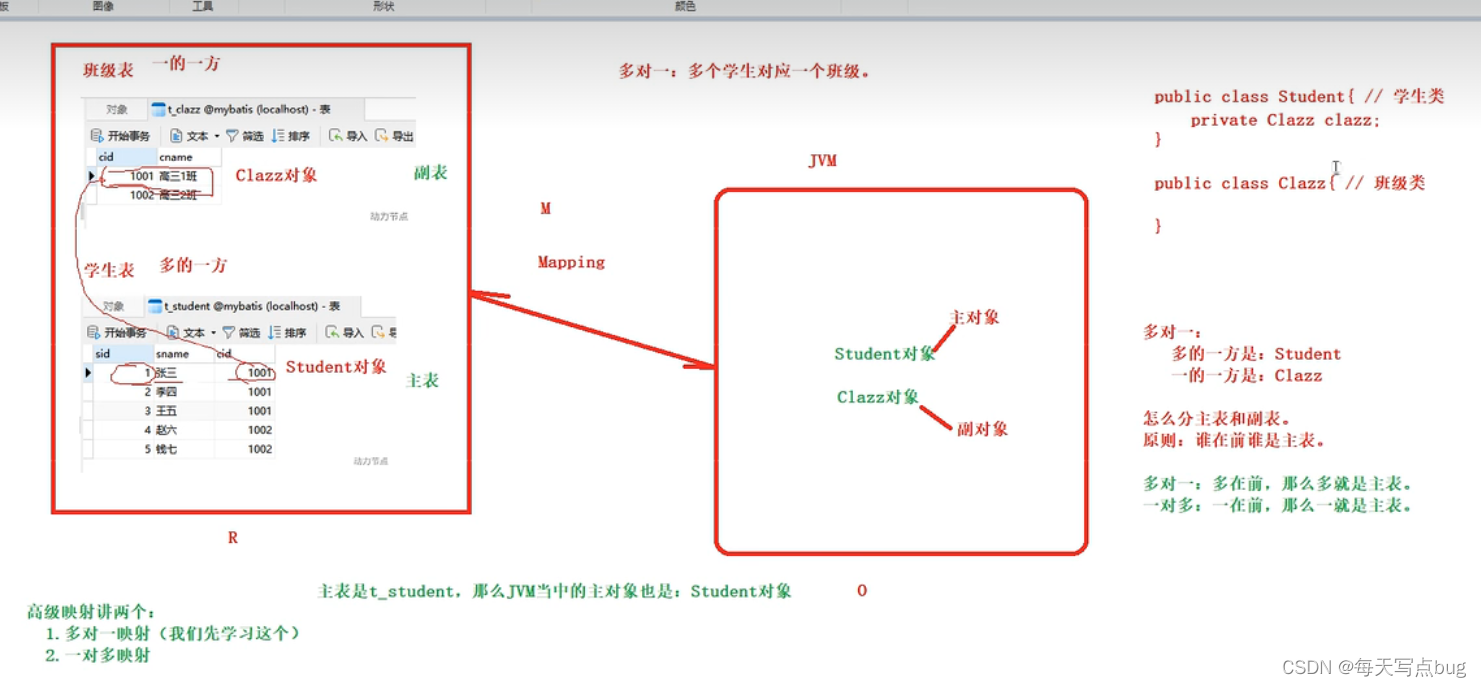
关联关系是有方向的.
1)一对多关联:一个老师可以教多个学生,多个学生只有一个老师来教,站在老师方,就是一对多关联.
2)多对一关联:一个老师可以教多个学生,多个学生只有一个老师来教,站在学生方,就是多对一关联.
3)一对一关联:一个老师辅导一个学生,一个学生只请教一个老师.学生和老师是一对一.
4)多对多关联:园区划线的车位和园区的每一辆车.任意一个车位可以停任意一辆车.任意一车辆车可以停在任意一个车位上.
22.一对多关联关系
客户和订单就是典型的一对多关联关系.
一个客户名下可以有多个订单.
客户表是一方,订单表是多方.客户一中持有订单的集合.
使用一对多的关联关系,可以满足查询客户的同时查询该客户名下的所有订单.

<mapper namespace="com.bjpowernode.mapper.CustomerMapper">
<!--
//根据客户的id查询客户所有信息并同时查询该客户名下的所有订单
Customer getById(Integer id)
实体类:
//customer表中的三个列
private Integer id;
private String name;
private Integer age;
//该客户名下的所有订单的集合
private List<Orders> ordersList;
-->
<resultMap id="customermap" type="customer">
<!--主键绑定-->
<id property="id" column="cid"></id>
<!--非主键绑定-->
<result property="name" column="name"></result>
<result property="age" column="age"></result>
<!--多出来的一咕噜绑定ordersList
Orders实体类:
private Integer id;
private String orderNumber;
private Double orderPrice;
-->
<collection property="ordersList" ofType="orders">
<!--主键绑定-->
<id property="id" column="oid"></id>
<!--非主键绑定-->
<result property="orderNumber" column="orderNumber"></result>
<result property="orderPrice" column="orderPrice"></result>
</collection>
</resultMap>
<select id="getById" parameterType="int" resultMap="customermap">
select c.id cid,name,age,o.id oid,orderNumber,orderPrice,customer_id
from customer c left join orders o on c.id = o.customer_id
where c.id=#{id}
</select>
</mapper>
23.多对一关联关系.(即重点放在多的一方,多就是主表)
订单和客户就是多对一关联.
站在订单的方向查询订单的同时将客户信息查出.
订单是多方,会持有一方的对象.客户是一方.
StudentMapper.xml如下
<!--
分步查询的优点:
第一:复用性增强。可以重复利用。(大步拆成N多个小碎步。每一个小碎步更加可以重复利用。)
第二:采用这种分步查询,可以充分利用他们的延迟加载/懒加载机制。
什么是延迟加载(懒加载),有什么用?
延迟加载的核心原理是:用的时候再执行查询语句。不用的时候不查询。
作用:提高性能。尽可能的不查,或者说尽可能的少查。来提高效率。
在mybatis当中怎么开启延迟加载呢?
association标签中添加fetchType="lazy"
注意:默认情况下是没有开启延迟加载的。需要设置:fetchType="lazy"
这种在association标签中配置fetchType="lazy",是局部的设置,只对当前的association关联的sql语句起作用。
在实际的开发中,大部分都是需要使用延迟加载的,所以建议开启全部的延迟加载机制:
在mybatis核心配置文件中添加全局配置:lazyLoadingEnabled=true
实际开发中的模式:
把全局的延迟加载打开。
如果某一步不需要使用延迟加载,请设置:fetchType="eager"
-->
<!--
1、多对一映射的第一种方式:一条SQL语句,级联属性映射。
-->
<resultMap id="studentResultMap" type="students">
<id property="studentId" column="s_id"/>
<result property="studentName" column="s_name"/>
<!--<result property="cId" column="c_id"/> 这个不对-->
<result property="myClass.classId" column="c_id"/>
<result property="myClass.className" column="c_name"/>
</resultMap>
<select id="selectById" resultMap="studentResultMap">
select s.s_id,s.s_name,c.c_name,c.c_id
from t_student s left join t_class c on s.c_id = c.c_id
where s_id = #{studentId}
</select>
<!--
2、多对一映射的第一种方式:一条SQL语句,association。
-->
<resultMap id="studentsResultMapAssociation" type="students">
<id property="studentId" column="s_id"/>
<result property="studentName" column="s_name"/>
<!--
association:翻译为关联。一个Student对象关联一个Clazz对象
property:提供要映射的POJO类的属性名。 (看到property想到属性!)
javaType:用来指定要映射的java类型。(就是对应的类)
-->
<association property="myClass" javaType="MyClass">
<id property="classId" column="c_id"></id>
<result property="className" column="c_name"></result>
</association>
</resultMap>
<select id="selectByIdAssociation" resultMap="studentsResultMapAssociation">
select s.s_id,s.s_name,c.c_id,c.c_name
from t_student s left join t_class c
on s.c_id = c.c_id
where s.s_id = #{studentId}
</select>
<!--
3.1、两条SQL语句,完成多对一的分步查询。
这里是第一步:根据学生的id查询学生的所有信息。这些信息当中含有班级id(cid)
分步查询的第二步应该 写一个MyClass的Mapper和对应的xml
<association property="clazz"
select="com.powernode.mybatis.mapper.ClazzMapper.selectByIdStep2" 第二条sql语句在mapper对应的方法!
column="cid" 将查询到的改列名对应的值,交给上面select语句对应的sql
fetchType="eager"/>
-->
<resultMap id="studentResultMapStep1" type="students">
<id property="studentId" column="s_id"/>
<result property="studentName" column="s_name"/>
<result property="classId" column="c_id"/>
<association property="myClass"
select="cn.edu.uestc.mapper.MyClassMapper.selectByIdStep2"
column="c_id"
fetchType="lazy"/>
</resultMap>
<select id="selectByIdStep1" resultMap="studentResultMapStep1">
select s_id,s_name,c_id
from t_student
where s_id = #{studentId}
</select>
对应的副表查询就非常简单,正常写即可,需要的参数由前一个传过来
<!--
3.2多对一分步查询第二步:
第一步那边通过associtaion的Colum传过来
<association property="myClass"
select="cn.edu.uestc.mapper.MyClassMapper.selectByIdStep2"
column="c_id"/>
-->
<resultMap id="myClassResultMapStep2" type="MyClass">
<id property="classId" column="c_id"></id>
<result property="className" column="c_name"/>
</resultMap>
<select id="selectByIdStep2" resultMap="myClassResultMapStep2">
select c_name,c_id
from t_class
where c_id = #{classId}
</select>
延迟加载的理解:(sqlMapConfig全局中配置全局延迟加载,如果有的需要不延迟加载,请设置:fetchType=“eager”)
<!--延迟加载的全局开关。默认值false不开启。-->
<!--什么意思:所有只要但凡带有分步的,都采用延迟加载。-->
<setting name="lazyLoadingEnabled" value="true"/>
@Test
public void testSelectByIdStep(){
Students students = service.selectByIdStep1(1);
//System.out.println(students);
//测试延迟加载:现在只取学生的名字,则不去查询另外一张表(配置了延迟加载,或者不配也是默认的
//如果配置完全局是lazy,而单独这个加上fetchType="eager",那也会去查两张表
System.out.println(students.getStudentName());
//现在又想看班级信息,如果是lazy模式的话,这时候才回去查询第二张附表
System.out.println(students.getMyClass().getClassName());
}
24.一对一关联
25.多对多关联
总结:无论是什么关联关系,如果某方持有另一方的集合,则使用标签完成映射,如果某方持有另一方的对象,则使用标签完成映射。
26.事务
多个操作同时完成,或同时失败称为事务处理.
事务有四个特性:一致性,持久性,原子性,隔离性.
下订单的业务:
1)订单表中完成增加一条记录的操作
2)订单明细表中完成N条记录的增加
3)商品数据更新(减少)
4)购物车中已支付商品删除
5)用户积分更新(增加)
在MyBatis框架中设置事务
===>程序员自己控制处理的提交和回滚
可设置为自动提交
sqlSession = factory.openSession(); ===>默认是手工提交事务,设置为false也是手工提交事务,如果设置为true,则为自动提交.
sqlSession = factory.openSession(true); ===>设置为自动提交,在增删改后不需要commit();
27.缓存
MyBatis框架提供两级缓存,一级缓存和二级缓存.默认开启一级缓存.
缓存就是为了提交查询效率.先取sqlSession中找,再去sqlSessionFactory中找
使用缓存后,查询的流程:
查询时先到缓存里查,如果没有则查询数据库,放缓存一份,再返回客户端.下次再查询的时候直接从缓存返回,不再访问数据库.如果数据库中发生commit()操作(增删改),则清空缓存.
1、 一级缓存使用的是SqlSession的作用域,同一个sqlSession共享一级缓存的数据.
2、 二级缓存使用的是mapper的作用域,不同的sqlSession只要访问的同一个mapper.xml文件,则共享二级缓存作用域.
二级缓存范围是SqlSessionFactory,范围较大,整个数据库级别的
什么时候一级缓存失效?
第一次DQL和第二次DQL之间你做了以下两件事中的任意一件,都会让一级缓存清空:
- 执行了sqlSession的clearCache()方法,这是手动清空缓存。
- 执行了INSERT或DELETE或UPDATE语句。不管你是操作哪张表的,都会清空一级缓存。
复习:
1、sqlSession.getMapper(XXXMapper.class)拿到mapper动态代理对象,就算获取两个mapper,使用一级缓存也不用多次访问数据库
2、如果要测试一级缓存,那弄两个sqlSession就好了:sqlSessionFactory.openSession() 写两次,拿到两个,这两个分别取取数据,那肯定是访问两次数据库 。(sqlSession对象不是同一个不走缓存)
28.什么是ORM
ORM(Object Relational Mapping):对象关系映射
MyBatis框架是ORM非常优秀的框架.
java语言中以对象的方式操作数据,存到数据库中是以表的方式进行存储,对象中的成员变量与表中的列之间的数据互换称为映射.整个这套操作就是ORM.
持久化的操作:将对象保存到关系型数据库中 ,将关系型数据库中的数据读取出来以对象的形式封装
MyBatis是持久化层优秀的框架.
29.整体思路、总结
- 先配置好pom文件,在resources目录下搞定jdbc.properties文件、SqlMapConfig.xml文件。
- 写好实体类pojo,注意如果实体类的属性名称和表中列名不一致,在XXXMapper.xml中需要使用resultMap进行配置。
- 开始写mapper包下的接口文件和xml文件。接口文件指定了有什么方法,传递什么参数,返回什么类型(比如获取所有就该返回 List<具体类型> )。xml文件中写sql语句就好。
- 上面其实就能运行了,现在需要进行测试。在测试中,通过
usersMapper = sqlSession.getMapper(UsersMapper.class);拿到接口的代理,让代理去调用接口中的方法就好了。(mybatis能动态的生成接口的实现类,这就是没看到一个UserMapperImpl类的原因,动态生成了,就是动态代理)
/**
* 记住三件事,before、after、测试
* 总结:xml文件中id = getAll对应的sql语句被代理出来,送给接口UserMapper,最后都是用接口去调用接口中的方法,对应的就是xml文件中标签提供的功能
*/
public class MyTest {
SqlSession sqlSession;
//动态代理对象,需要获取和关闭,所以要放在外面
UsersMapper usersMapper;//通过session拿到xxxMapper;
//日期的格式化刷子
//SimpleDateFormat下:format()方法把日期变字符串;parse()方法就是把字符串变日期;
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");//注意MM大写,和分钟mm区分开!
@Before
public void openSqlSessoion() throws IOException {
//1、读取核心配置文件
InputStream ins = Resources.getResourceAsStream("SqlMapConfig.xml");
//2、创建工厂
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(ins);
//3、打开sqlSession
sqlSession = factory.openSession(true);
/**
* 大重点
* 取出动态代理对象,完成接口中方法的调用,实际是调用xml文件中相关标签的功能!!
* getMapper()得到映射器的方法
*/
usersMapper = sqlSession.getMapper(UsersMapper.class);
}
@After
public void closeSession(){
sqlSession.close();
}
@Test
public void testGetAll(){
System.out.println(usersMapper.getClass());//class com.sun.proxy.$Proxy6 这就是动态代理对象
List<Users> list = usersMapper.getAll();
list.forEach(users-> System.out.println(users));
}
5)、配置映射(名称不一致)
resultType:指定查询返回的结果集的类型,如果是集合,则必须是泛型的类型。比如用于返回受影响的条数等。
resultMap:实体类的属性名称和列名不一致的时候(要将查到的信息封装到对应的类中成员变量去),使用这个回参。比如select语句查到信息后返回一个对象或者对象的集合用到
parameterType: 这是入;如果有参数,则通过它来指定输入参数的类型,比如:insert语句,经常入参是个对象user这样、delete语句入参id等。注意多个入参的时候,parameterType可以不写!
- 比如在执行查询语句的时候,查询到了表中的列,想要自动封装为一个对象返回,那肯定得和属性名对上,才能封装为指定的返回值类型resultType。
- 如果名称不一致,那就不能用resultType(当然可以给列名起别名 select …as…),这时候就需要使用resultMap。如果查询多条数据比如selectAll(),回参类型还是resultMap的id,只需要在当时写接口的时候指定返回值类型是List,使用代替代理对象ordersMapper调用对应方法就可以返回到一个List集合。
- 其配置格式如下
<resultMap id="map" type="orders">
<!--定义主键,非常重要,如果是多个字段,就定义多个id-->
<!--property: 主键在pojo中的属性名-->
<!--column:主键在数据库中的列名-->
<id property="id" column="id"></id>
<!--定义普通属性-->
<result property="orderNumber" column="order_number"></result>
<result property="orderPrice" column="order_price"></result>
<result property="customerId" column="customer_id"/>
</resultMap>
















 65
65











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









