







大家都知道使用htmlunit的时候会有很多debug的日志输出,很影响实际的生产判断,网上一些关于LoggerFactory的配置、还有一些基于配置文件的配置均不能实际解决问题;
以下解决方案适用场景为:java的main方法中调htmlunit进行一些业务处理。
1.直接屏蔽,按需打开
//import org.slf4j.LoggerFactory;
//import ch.qos.logback.classic.Logger
//import ch.qos.logback.classic.Level;
//import ch.qos.logback.classic.LoggerContext;
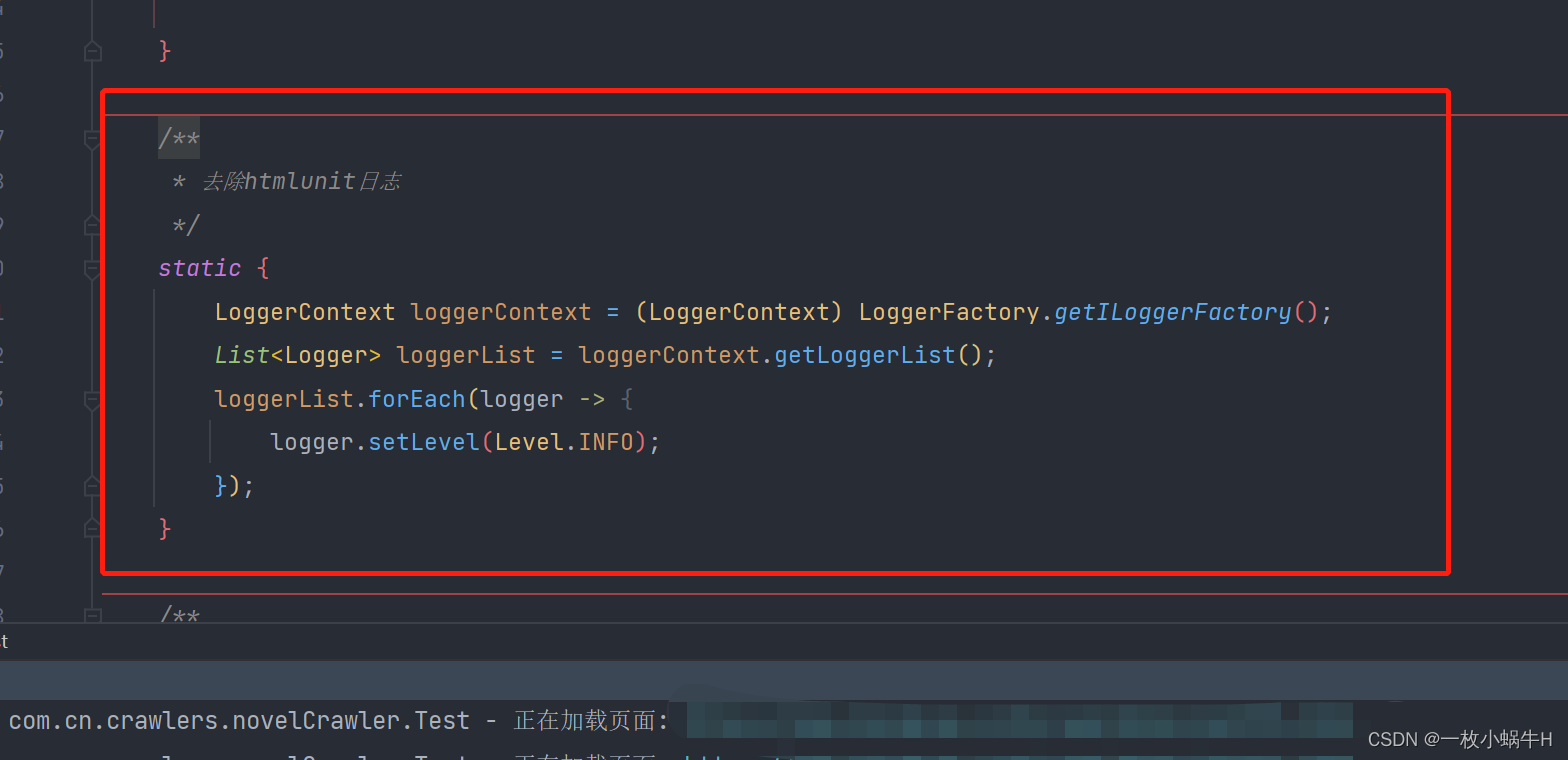
static {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
List<ch.qos.logback.classic.Logger> loggerList = loggerContext.getLoggerList();
loggerList.forEach(logger -> {
logger.setLevel(Level.OFF);
});
}将静态代码块添加到测试类中即可,亲测可行,Level.OFF根据实际需要进行修改等级。比如我自定义的INFO级别,就放开了。这个还不完美,JS也会报错,加上方案2。
如图所示
2.屏蔽js异常报错
进行各种各样的网页爬虫过程中,有些网页直接httpclient拿过来就能用,但是有些网站是需要等待js加载样式或者某些值的,使用httpclient没办法设置js等待时间,然后再抓取值。
htmlunit可以完美解决这个问题。但是在使用htmlunit访问网页时 经常会出现各种网页的JavaScript加载过程中的警告与提示信息 例如:
ERROR c.g.h.javascript.DefaultJavaScriptErrorListener - Error during JavaScript execution
com.gargoylesoftware.htmlunit.ScriptException: URIError: Malformed URI sequence.在代码中已经对WebClient进行设置了webClient.getOptions().setThrowExceptionOnScriptError(false);
并不能关闭这些提示信息 导致每次访问网页都会打印一大串一大串的无用信息
我并不关心他js报什么错,我只关心拿下来页面的结果。通过查看这个报错类,重写它里面的方法,把所有log输出语句全部删除,就可以达到不打印错误信息的作用了。
类路径是:com.gargoylesoftware.htmlunit.javascript.DefaultJavaScriptErrorListener
/**
* 忽略html unit打印的所有js加载报错信息
*/
public static class MyJSErrorListener extends DefaultJavaScriptErrorListener {
@Override
public void scriptException(HtmlPage page, ScriptException scriptException) {
}
@Override
public void timeoutError(HtmlPage page, long allowedTime, long executionTime) {
}
@Override
public void malformedScriptURL(HtmlPage page, String url, MalformedURLException malformedURLException) {
}
@Override
public void loadScriptError(HtmlPage page, URL scriptUrl, Exception exception) {
}
@Override
public void warn(String message, String sourceName, int line, String lineSource, int lineOffset) {
}
}3. 范例代码
package com.cn.crawlers.novelCrawler;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
import ch.qos.logback.classic.LoggerContext;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.io.IORuntimeException;
import cn.hutool.core.util.CharsetUtil;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.NicelyResynchronizingAjaxController;
import com.gargoylesoftware.htmlunit.ScriptException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import com.gargoylesoftware.htmlunit.javascript.DefaultJavaScriptErrorListener;
import lombok.extern.slf4j.Slf4j;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.slf4j.LoggerFactory;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.List;
@Slf4j
public class Test {
public static void main(String[] args) {
log.info("任务开始");
Document document = accordingToURLGetBrowserHtml("https://www.dingdian.info/book/82431/");
Element boxCon = document.getElementsByClass("box_con").get(1);
for (Element element : boxCon.getElementsByAttribute("href")) {
String href = "https://www.dingdian.info" + element.attr("href");
String text = element.text();
setTxt(text);
getInfo(href);
}
log.info("任务结束");
}
/**
* 获取内容
*
* @param url 链接
*/
public static void getInfo(String url) {
Document document = accordingToURLGetBrowserHtml(url);
Element content = document.getElementById("content");
String text = null;
if (content != null) {
text = content.wholeText();
}
setTxt(text);
}
/**
* 写入txt
*
* @param content 内容
*/
public static void setTxt(String content) {
//将String写入文件,追加模式
String path = "D:\\新建 文本文档.txt";
//path指定路径下的文件如不存在,则创建
try {
FileUtil.appendString(content, path, CharsetUtil.UTF_8);
} catch (IORuntimeException e) {
//抛出一个运行时异常(直接停止掉程序)
throw new RuntimeException("运行时异常", e);
}
}
/**
* 去除htmlunit日志
*/
static {
LoggerContext loggerContext = (LoggerContext) LoggerFactory.getILoggerFactory();
List<Logger> loggerList = loggerContext.getLoggerList();
loggerList.forEach(logger -> {
logger.setLevel(Level.INFO);
});
}
/**
* 设置一个无头浏览器,抓取动态渲染页面
*
* @param requestUrl 要解析页面URL地址
* @return 返回Document对象
*/
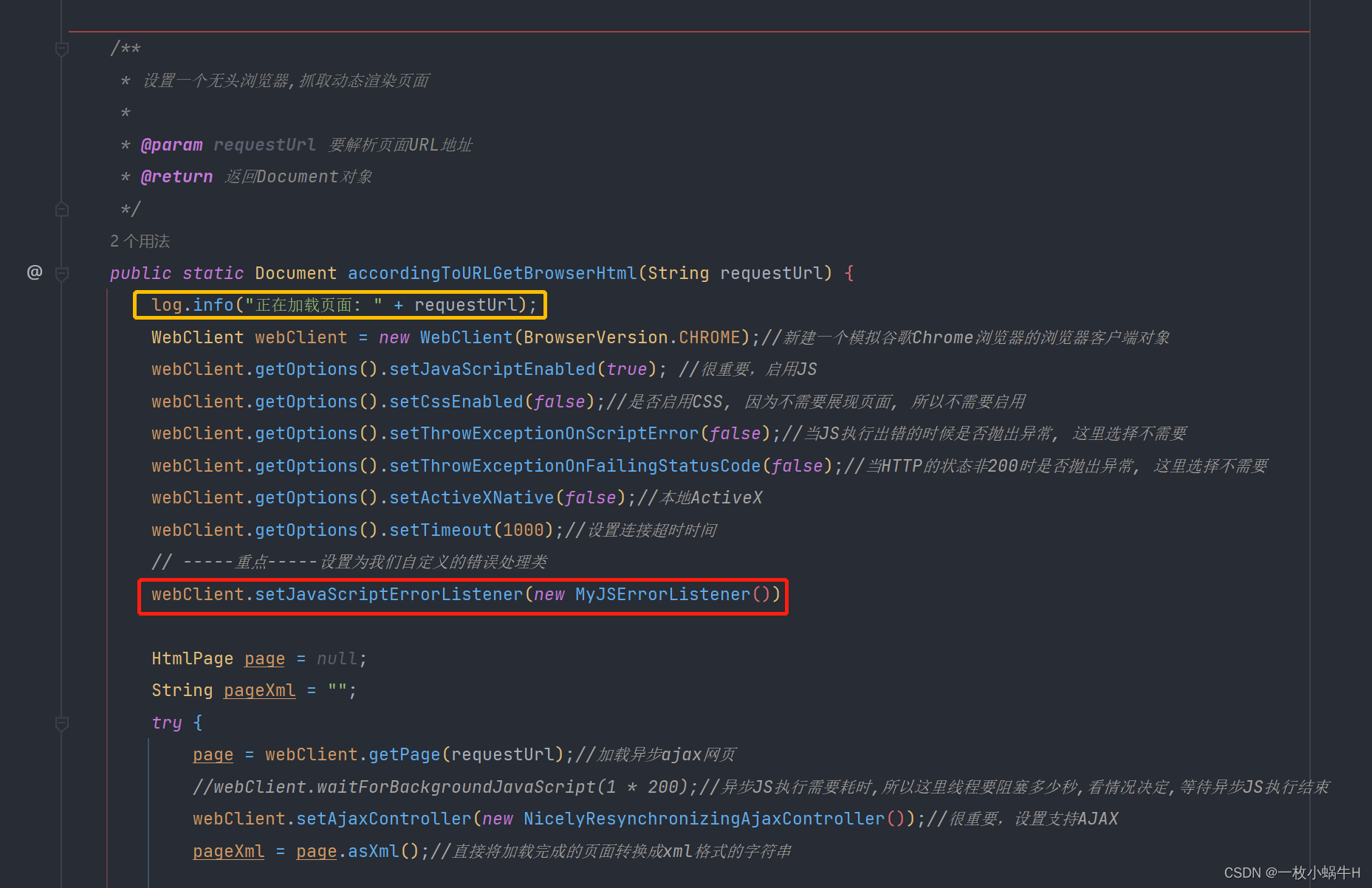
public static Document accordingToURLGetBrowserHtml(String requestUrl) {
log.info("正在加载页面: " + requestUrl);
WebClient webClient = new WebClient(BrowserVersion.CHROME);//新建一个模拟谷歌Chrome浏览器的浏览器客户端对象
webClient.getOptions().setJavaScriptEnabled(true); //很重要,启用JS
webClient.getOptions().setCssEnabled(false);//是否启用CSS, 因为不需要展现页面, 所以不需要启用
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.getOptions().setActiveXNative(false);//本地ActiveX
webClient.getOptions().setTimeout(1000);//设置连接超时时间
// -----重点-----设置为我们自定义的错误处理类
webClient.setJavaScriptErrorListener(new MyJSErrorListener());
HtmlPage page = null;
String pageXml = "";
try {
page = webClient.getPage(requestUrl);//加载异步ajax网页
//webClient.waitForBackgroundJavaScript(1 * 200);//异步JS执行需要耗时,所以这里线程要阻塞多少秒,看情况决定,等待异步JS执行结束
webClient.setAjaxController(new NicelyResynchronizingAjaxController());//很重要,设置支持AJAX
pageXml = page.asXml();//直接将加载完成的页面转换成xml格式的字符串
} catch (Exception e) {
e.printStackTrace();
} finally {
webClient.close();
}
return Jsoup.parse(pageXml);//获取html文档
}
/**
* 忽略html unit打印的所有js加载报错信息
*/
public static class MyJSErrorListener extends DefaultJavaScriptErrorListener {
@Override
public void scriptException(HtmlPage page, ScriptException scriptException) {
}
@Override
public void timeoutError(HtmlPage page, long allowedTime, long executionTime) {
}
@Override
public void malformedScriptURL(HtmlPage page, String url, MalformedURLException malformedURLException) {
}
@Override
public void loadScriptError(HtmlPage page, URL scriptUrl, Exception exception) {
}
@Override
public void warn(String message, String sourceName, int line, String lineSource, int lineOffset) {
}
}
}
参考链接:https://blog.csdn.net/csdn_avatar_2019/article/details/123762252
参考链接:https://blog.csdn.net/he37176427/article/details/103125002















 1211
1211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









