






引言
在信息爆炸的数字时代,数据已成为最宝贵的资源之一。随着互联网的飞速发展,网络上的数据量以惊人的速度增长,这些数据蕴含着巨大的价值,等待着我们去挖掘和分析。网络爬虫技术,作为获取网络数据的有力工具,已经成为大数据领域不可或缺的一部分。它能够帮助我们自动、高效地从互联网上抓取大量数据,为数据分析、机器学习、商业智能等应用提供了丰富的原材料。
1、爬虫技术的魅力与挑战
网络爬虫,通常被称为网络蜘蛛或网页抓取器,是一种自动浏览网页并抓取所需信息的程序。随着大数据技术的发展,爬虫技术已经成为数据科学家、分析师和开发者的重要工具。通过爬虫,我们可以从新闻网站、社交媒体、电子商务平台等来源抓取数据,用于市场趋势分析、消费者行为研究、品牌监控等多种大数据分析场景。
然而,爬虫技术的应用也面临着法律和伦理的挑战。不合理的使用可能会侵犯个人隐私、损害网站权益甚至触犯法律。因此,了解爬虫技术的合法使用边界,遵守相关的法律法规,是每个爬虫开发者必须面对的问题。
2、大数据分析的应用前景
大数据分析是指使用先进的分析技术和工具,从海量数据中提取有价值的信息和知识。随着大数据技术的发展,大数据分析已经成为企业和组织决策的重要支持。通过大数据分析,企业可以更好地理解市场动态、优化业务流程、提高运营效率,甚至发现新的商业机会。
网络爬虫技术与大数据分析的结合,为数据驱动的决策提供了强大的支持。通过爬虫获取的数据可以用于各种分析模型,如预测分析、聚类分析、关联规则挖掘等,帮助企业和组织做出更明智的决策。
3、本系列的目标
在本博客系列中,我们将深入探讨网络爬虫技术的工作原理、开发实践以及在大数据分析中的应用。我们将从爬虫的基础知识入手,逐步介绍爬虫的高级技巧和最佳实践。同时,我们也会讨论爬虫技术面临的法律和伦理问题,以及如何在合规的前提下有效地使用爬虫技术。
通过本系列的学习和实践,您将能够掌握网络爬虫技术的核心概念和技能,了解如何在大数据分析中应用这些技术,并成为一个负责任的爬虫开发者。让我们一起开启这段激动人心的学习之旅。
一、初识网络爬虫
在数字化时代,网络爬虫已成为探索互联网数据海洋的必备工具。它们自动地访问网页,提取信息,为大数据分析提供原材料。但同时,爬虫技术也引发了一系列法律和伦理问题,需要我们仔细考量。
1、爬虫的定义与工作原理
(1)网络爬虫的概念
网络爬虫,也称为网页蜘蛛或网页机器人,是一种自动化的程序,它能够模拟人类浏览网页的行为,按照一定的规则在互联网上浏览和抓取信息。爬虫可以连续访问多个页面,收集大量的数据,为数据分析、信息检索、内容聚合等多种应用提供支持。
(2)爬虫如何模拟浏览器行为
爬虫通过发送HTTP请求来模拟浏览器向服务器请求网页内容。当服务器响应这些请求时,爬虫会接收网页的HTML代码,然后使用解析器(如BeautifulSoup或lxml)来提取所需的数据。这个过程涉及到模拟用户代理(User-Agent)、处理Cookies、管理会话以及执行JavaScript等技术,以确保能够准确地抓取和解析网页内容。
2、爬虫的合法性与伦理问题
(1)爬虫行为的法律边界
爬虫技术本身是中立的,但其应用可能会触及法律红线。例如,爬取受版权保护的内容、侵犯个人隐私、突破网站的反爬虫措施等行为都可能构成违法行为。各国法律对爬虫的规定不尽相同,但通常都需要遵守以下原则:
①尊重版权:不得爬取和分发受版权保护的内容。
②保护隐私:不得收集和使用个人隐私信息,除非得到用户同意。
③遵守robots协议:尊重网站的robots.txt文件中的规则,不爬取被禁止的内容。
(2)爬虫技术应用的伦理考量
除了法律问题,爬虫技术的应用还涉及伦理问题。开发者需要考虑以下伦理原则:
①数据使用的目的:确保爬取的数据用于正当目的,不用于欺诈、诽谤或其他恶意行为。
②数据的准确性:确保爬取的数据准确无误,不误导用户或社会。
③对网站的影响:避免对网站的正常运行造成影响,如不过度请求导致服务器负载过大。
二、Python爬虫基础
1、Python爬虫环境搭建
在开始Python爬虫之旅之前,我们需要搭建一个适宜的开发环境。这包括安装Python解释器以及一些必要的第三方库。
(1)Python安装与配置
①安装Python
访问Python官网下载最新版本的Python安装包。
安装Python时,确保勾选“Add Python to PATH”选项,这样可以在命令行中直接调用Python。
②验证安装
打开命令行工具,输入python --version(或python3 --version),如果安装成功,它会显示Python的版本号。
③安装代码编辑器
选择一个代码编辑器,如PyCharm、VSCode、jupyter notebook或Sublime Text,它们都提供了良好的Python开发支持。
(2)必备库的安装:requests、BeautifulSoup、Scrapy
①requests库(用于发送HTTP请求,获取网页内容):
pip install requests
pip install requests②BeautifulSoup库(用于解析HTML和XML文档,提取所需的数据):
pip install Beautifulsoup4
pip install Beautifulsoup4③Scrapy框架(一个强大的爬虫框架,用于构建大型爬虫项目):
pip install Scrapy
pip install Scrapy2、Python爬虫入门实例
(1)简单爬虫代码示例
以下是一个简单的Python爬虫示例,它使用requests库获取网页内容,并使用BeautifulSoup库解析HTML,提取网页的标题。
import requests
from bs4 import BeautifulSoup
# 目标URL
url = 'http://example.com'
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页标题
title = soup.find('title').text
print('网页标题:', title)
else:
print('请求失败,状态码:', response.status_code)(2)爬取数据的基本流程
①发送HTTP请求:使用requests库向目标网站发送GET请求。
②处理响应内容:检查响应状态码,确保请求成功,获取响应的HTML内容。
③解析HTML:使用BeautifulSoup解析HTML文档。
④提取数据:根据HTML结构,使用BeautifulSoup的方法提取所需的数据。
⑤存储数据:将提取的数据保存到文件、数据库或其他存储系统中。
三、爬取百度图片
1.导入库
import requests
import json
import os
import pprintrequests:用于发送HTTP请求。json:用于处理JSON数据。os:用于操作文件系统。pprint:用于漂亮打印数据。
2、设置请求头:
headers变量定义了HTTP请求的头部信息,主要是User-Agent,用于模拟浏览器访问。
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67'
}"User-Agent"在哪
打开"百度浏览器“,搜索你想要搜索的东西,然后按图片,按F12
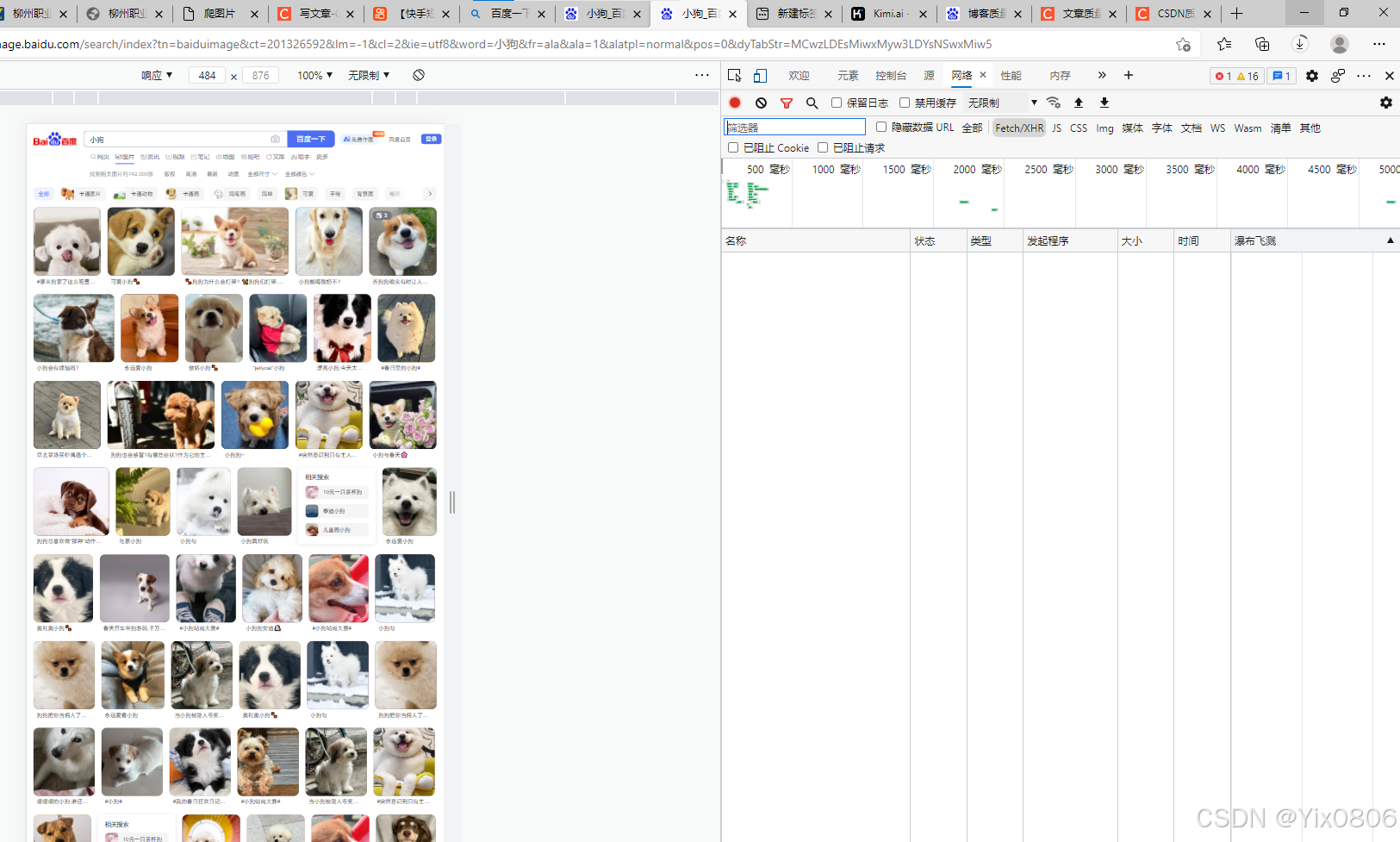
按“网络”,再按“XHR” ,然后下滑图片,找到acjson?开头的点进去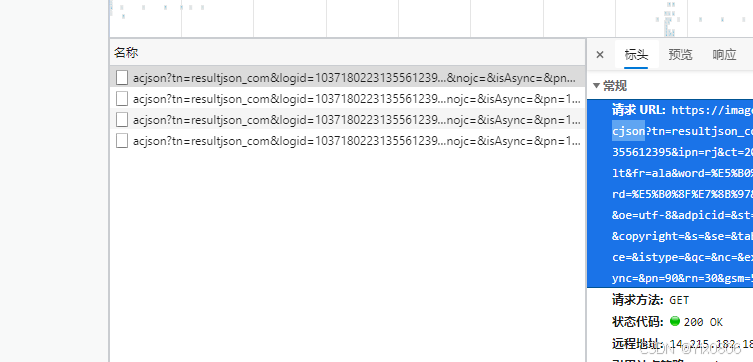
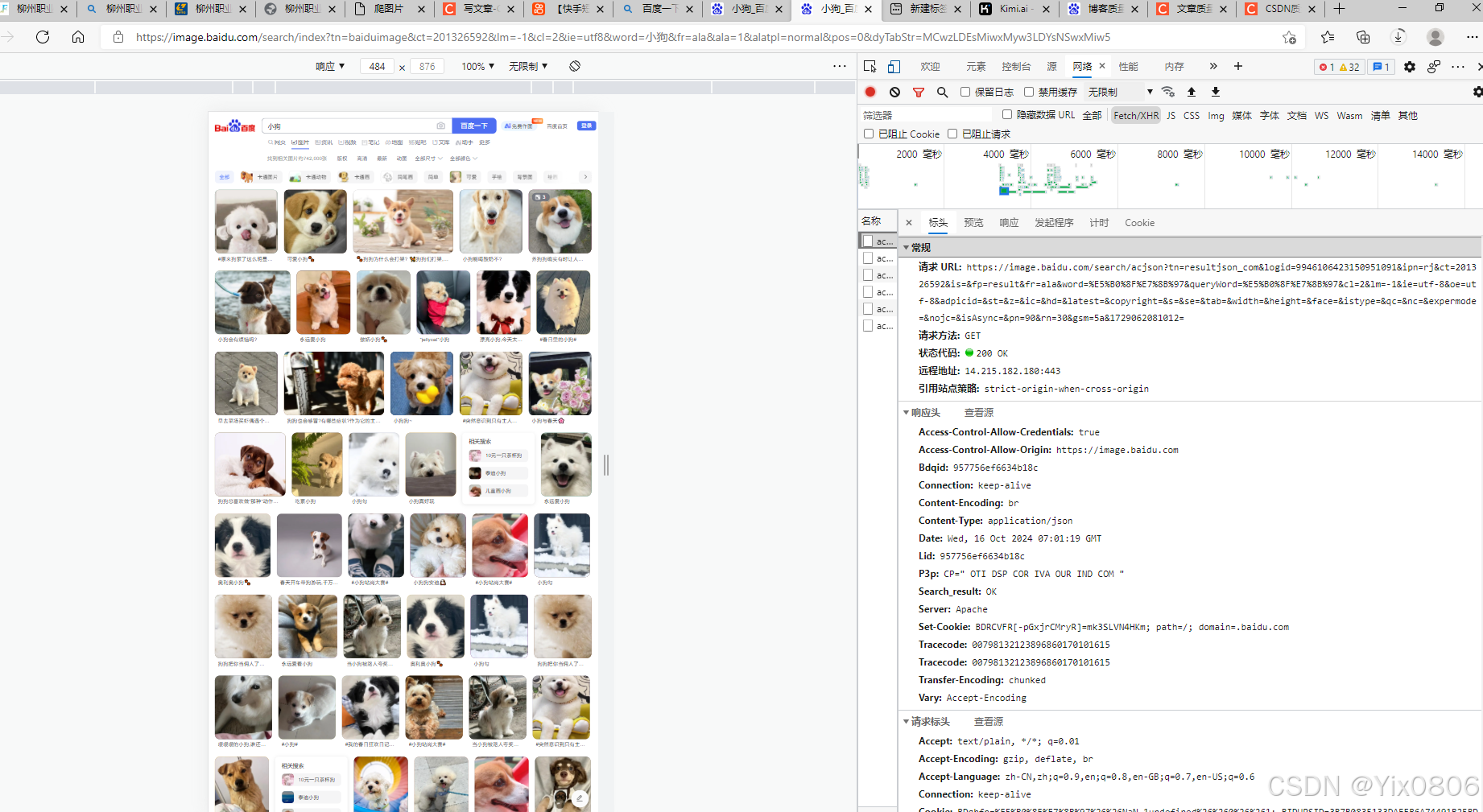
import requests
import json
import os
import pprint
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67'
}
url='https://image.baidu.com/search/acjson?'
param={
'tn': 'resultjson_com',
'logid':'10894587518665420286',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp':'result',
'fr':'',
'word': '小狗',
'queryWord':' 小狗',
'cl': '',
'lm': '',
'ie':'utf-8',
'oe': 'utf-8',
'adpicid':'',
'st':'',
'z': '',
'ic':'',
'hd':'',
'latest':'',
'copyright':'',
's':'',
'se':'',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'expermode': '',
'nojc': '',
'isAsync': '',
'pn': '60',
'rn': '30',
'gsm': '3c'
}
response=requests.get(url=url,headers=headers,params=param)
response.encoding='utf-8'
response=response.text
print(response)
data_s=json.loads(response)
print(data_s)
pprint.pprint(data_s)
a=data_s["data"]
for i in range(len(a)-1):
data=a[i].get("thumbURL","not exist")
print(data)
path=r'D:\wxm'
if not os.path.exists(path):
os.mkdir(path)
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67'
}
keyword=input("请输入你想下载的内容:")
page=input("请输入你想爬取的页数:")
page=int(page)+1
n=0
pn=1
url='https://image.baidu.com/search/acjson?'
for m in range(1,page):
param={
'tn': 'resultjson_com',
'logid':'10894587518665420286',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp':'result',
'fr':'',
'word': keyword,
'queryWord':keyword,
'cl': '',
'lm': '',
'ie':'utf-8',
'oe': 'utf-8',
'adpicid':'',
'st':'',
'z': '',
'ic':'',
'hd':'',
'latest':'',
'copyright':'',
's':'',
'se':'',
'tab': '',
'width': '',
'height': '',
'face': '',
'istype': '',
'qc': '',
'nc': '1',
'expermode': '',
'nojc': '',
'isAsync': '',
'pn': pn,
'rn': '30',
'gsm': '3c'
}
image_url=list()
response=requests.get(url=url,headers=headers,params=param)
response.encoding='utf-8'
response=response.text
data_s=json.loads(response)
a=data_s["data"]
for i in range(len(a)-1):
data=a[i].get("thumbURL","not exist")
image_url.append(data)
for image_src in image_url:
image_data=requests.get(url=image_src,headers=header).content
image_name='{}'.format(n+1)+'.jpg'
image_path=path+'/'+image_name
with open (image_path,'wb') as f:
f.write(image_data)
print(image_name,'下载成功')
f.close()
n+=1
pn +=29


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









