






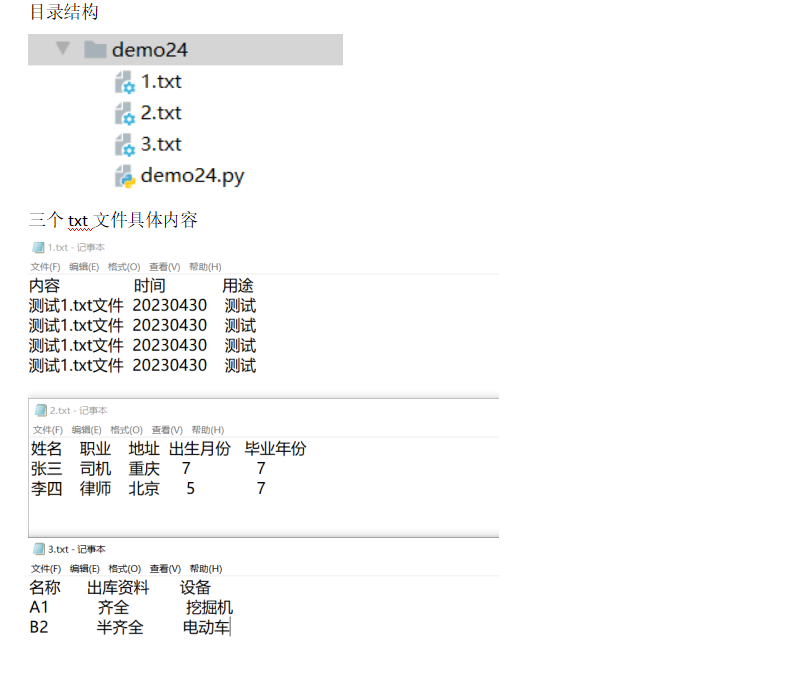
1.单个文件,双个文件,三个文件的读取方式
新建1.txt文件,2.txt文件,3.txt文件,效果如下
执行代码
"""
单文件,双文件,三文件的读取方式
Python的读写
file.read() ———— 一次性读取整个文件内容,推荐使用read(size)方法,size越大运行时间越长
file.readline() ———— 每次读取一行内容,
file.readlines() ———— 一次行读取整个文件内容,并按行返回到list
file.write(str) ————— 它的参数是一个字符串,就是你要写入文件的内容
file.writelines(sequence) ————— 它的参数功能比较强大,它可以是字符串,也可以是字符串序列,比如列表
"""
# 读 1.txt文件
with open('1.txt',encoding='utf-8') as f:
print('f.read()',f.read())
# print('f.readlines()',f.readlines())
# 把1.txt文件内容(从第二行开始)追加到2.txt文件后面
with open('1.txt',encoding='utf-8') as f:
text = ('\n',*f.readlines()[1:])
with open('2.txt','a',encoding='utf-8') as w:
w.writelines(text)
# 把1.txt文件内容(从第二行开始)和2.txt文件内容(从第二行开始)追加到3.txt后面
with open('1.txt',encoding='utf-8') as f:
text = ('\n',*f.readlines()[1:])
with open('3.txt','a',encoding='utf-8') as w:
w.writelines(text)
with open('2.txt',encoding='utf-8') as f:
text = ('\n',*f.readlines()[1:])
with open('3.txt','a',encoding='utf-8') as w:
w.writelines(text)
示图如下

2.判断文件夹是否为空,如果不为空,取后缀为.xlsx的文件
"""
判断文件夹是否为空,如果不为空,取后缀为.xlsx的文件
os.path.exists() 方法用于检验文件/文件夹是否存在
os.listdir() 遍历该文件夹下的所有文件名
"""
import os
import pandas as pd
filenamelist = []
folder_path = '需要检验该文件夹绝对位置'
for filename in os.listdir(folder_path):
if filename.endswith('xls') or filename.endswith('.xlsx'):
# 拼接单个.xlsx路径
filename_li = os.path.join(folder_path,filename)
# 读这个.xlsx
filename_li_content = pd.read_excel(filename_li)
# 罗列所有后缀是.xlsx文件的名称
filenamelist.append(filename_li)
3.DataFrame里面的增删改查
"""
DataFrame里面的增删改查,因为方法很多,重点记录最常用,最好用的方法
"""
import pandas as pd
# 新建测试dataframe数据
table = pd.DataFrame({
'姓名':['大','搭','达','答'],
'时间':[199991101,19991102,19991103,19991104],
'性别':['男','男','女','男'],
})
print(table)
# 增
# 增加的一行
table.loc["增加的一行"] = pd.Series([1,2,3],index=table.columns)
# 增加的一列
table['增加的一列'] = '1'
# print(table)
# 删除
"""
常用del和drop方法删除DataFrame中的列,使用drop方法一次删除多列或者多行
1.用del,一次只能删除一列,不能一次删除多列
常用:del table['性别']
不能使用:del table['姓名','性别']
2.用drop方法,三种用法
df = df.drop(['A','B'].axis=1) -----表示删除 A、B两列
df.drop(['A','B'].axis=1,insplace=True) ---- 表示删除 A、B两列,直接从内部删除,不用赋值给新对象
df.drop(df.columns[0,4,8],axis=1,inplace=True) # 表示删除索引为0、4、8的列
"""
# 改
# 特别注意,假设五列数据,你如果单拎出两列数据进行逻辑变换,放回去的时候不能直接放回去,用拼接函数,不然直接放回去会造成每一行数据都会错误。
# 需求:把数字这一列的数值全部改成负数
table[['数字']] = table[['数字']].apply(lambda x:-x,axis=1)
# 或 默认列
table[['数字']] = table[['数字']].apply(lambda x:-x)
# 或
table['数字'] = -table['数字']
# 或者
table['数字'] = table['数字'] * -1
# 查看特定行列
print(table.loc['0':'1','姓名':'时间'])
# 不看最后一行 特点,包头不包尾
print(table.iloc[:-1,:])
# 总结table['性别']和table[['性别']]的区别
"""
[[]]:返回的是 DataFrame
[]:返回的是pandas.core.series.Series
"""
# 总结loc和iloc的区别
"""
loc里面是字符串,比如行名,列名
iloc里面是int,比如行的索引,列的索引
"""
# 查
print(table.dtypes)
print(table.info())
print(table['A','B'])
"""
筛选出某列属于某个范围的行
df.loc[df['column_name'].isin(some_values)]
筛选出某列含有特定值的行
df.loc[df.loc[:,'column_name'].isin(some_values)]
筛选多个列,包含多个条件
df[df['column_name1].isin(['条件1']) & df['column_name2].isin(['条件2'])]
例如:
df = df.loc[df['B'].isin(['454'])]
df = df.loc[df['B'].isin(['454','121','333'])]
df = df[df.loc[:,'B'].isin(['454','121','333'])]
"""
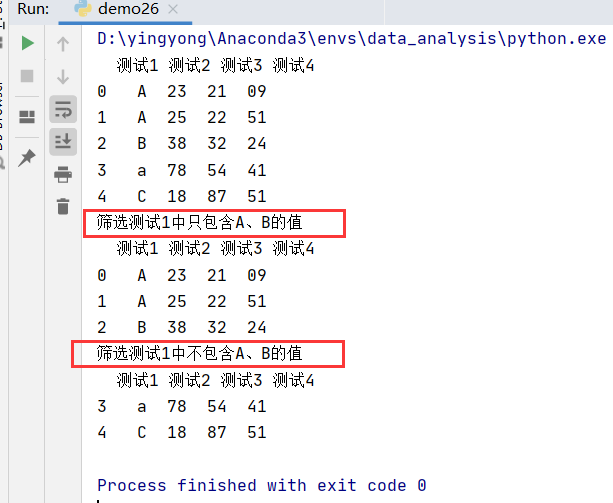
df_a = pd.DataFrame({
'测试1':['A','A','B','a','C'],
'测试2':['23','25','38','78','18'],
'测试3':['21','22','32','54','87'],
'测试4':['09','51','24','41','51']
})
print(df_a)
# 筛选测试1中只包含A、B的值
df_b = df_a[df_a['测试1'].isin(['A','B'])]
print('筛选测试1中只包含A、B的值')
print(df_b)
# 筛选测试1中不包含A、B的值
df_c = df_a[~df_a['测试1'].isin(['A','B'])]
print('筛选测试1中不包含A、B的值')
print(df_c)
示图:
4.小数点后保留七位小数的方法
import pandas as pd
table = pd.DataFrame({
'姓名':['大','搭','达','答'],
'时间':[199991101,19991102,19991103,19991104],
'性别':['男','男','女','男'],
})
# 这个方法最多保留小数点后四位 4.0500
table['时间'] = table['时间'].round(decimals=4)
# 保留五位以上的方法
table['时间'] = table['时间'].map(lambda x:('%.7f') % x)
5.如何对姓名这一列的每个名字做隐藏处理
"""
如何对姓名这一列做**处理,如:张三变成张**,王麻子变成王**
"""
import pandas as pd
table = pd.DataFrame({
'姓名':['大','搭','达','答'],
'时间':[199991101,19991102,19991103,19991104],
'性别':['男','男','女','男'],
})
for i in range(len(table)):
table['姓名'][i] = table['姓名'][i][:1] + '**'
print(table)
6.Python的序列化和json的序列化
"""
Python的序列化和json的序列化
1.为什么要序列化
内存中的字典、列表、集合以及各种对象,如何保存到一个文件中?
之前往往都是将这些对象转成字符对象,然后再写入到文件中。
设计一套协议,按照某种规则,把内存中的数据保持到文件中,文件是一个个字节序列。
所以必须把数据转换陈字节序列,输出到文件,这就是序列化,反之,从文件中的字节序列恢复到内存中,就是反序列化
"""
# python的序列化
# pickle 是python的内置函数
# 用法:import pickle
# pickle的优点
# 针对于数据量大的列表、字典,可以采用将其加工为数据包来调用,减少文件大小;也就是一个压缩-->保存-->提取的一个过程。
# import pickle
"""
pickle.dumps() 序列化 将对象序列成bytes对象
pickle.loads() 反序列化 将bytes对象反序列成对象
pickle.dump() 将一个对象序列以二进制写入到文件中
pickle.load() 从文件中把序列化对象反序列成一个对象
# 特别注意:pickle不是一个安全的模块,经常使用dumps和loads
"""
# 用法:生成一个excel字节流,就是把excel表格转成字符串
import pickle
import zlib
from openpyxl import workbook,load_workbook
# 生成随机的ascii符号
a = [chr(i) for i in range(1000,1256)]
# print(a) <openpyxl.workbook.workbook.Workbook object at 0x089D8970>
excel_table = load_workbook('1.xlsx')
print(excel_table)
# 写入文件
write_bin = pickle.dumps(excel_table)
# print(write_bin)
# 压缩
zip_write_bin = zlib.compress(write_bin)
# print(zip_write_bin)
# 将字节流拼接
b = ''.join([a[i] for i in zip_write_bin])
print(b) # Ѡ҄ӕѥϯѠҼЮҟҞУьϫѬѺ϶бЄҏЩϺҨϭӃРϱЉшыЈϳѮӀϬ҄ЪЄѡпӞвцҗҔѹϾы...
# 将字节流生成excel
b1 = b''.join(a.index(i).to_bytes(1,'little') for i in b)
c = zlib.decompress(b1)
writh_file = pickle.loads(c)
# 激活并修改表头
writh_file_test = writh_file.active
writh_file_test.cell(1,1,'测试数据')
# 将字节流写入excel
writh_file.save('test.xlsx')
# json的序列化与反序列化
import json
"""
序列化:将python中的字典或字符串转换为一种特殊的字符串(json)
反序列化:将json字符串转化为python字典或者字符串
json.dumps() 序列化 将dict或者str 类型的数据转成json字符串
json.loads() 反序列化 将json字符串转成python字典
json.dump() 用于将python字典或者字符串裂隙的数据转成json字符串,并写入到json文件中
json.load() 用于从文件中读取json字符串转成python字典或者对象
"""
import json
data = {
'name':'张三',
'age':18,
'hometown':'上海'
}
print(data)
print(type(data))
data_json = json.dumps(data)
print(data_json) # {"name": "\u5f20\u4e09", "age": 18, "hometown": "\u4e0a\u6d77"}
print(type(data_json))
# 原因:在json序列化的时候,使用的是默认编码是ASCII,而中文是Unicode编码,ASCII不包含中文,所以出现了乱码
# 解决方法 ensure_ascoo=False
data_json1 = json.dumps(data,ensure_ascii=False)
print(data_json1) # "name": "张三", "age": 18, "hometown": "上海"}
print(type(data_json1))
data1 = 'test1tset2'
# 把pyhton字符串转成json字符串,写入到demo1.txt文件里
with open('demo1.txt','w') as fp:
# 一个对象序列以二进制写入到文件中
json.dump(data1,fp)
# 把json字符串转成python字符串,写入dmmo2.txt文件里
with open('demo1.txt','r',encoding='utf-8') as f:
# 文件中读取json字符串转成python字典或者对象
python_str = json.load(f)
with open('demo2.txt','w') as f:
f.write(python_str)
示图如下


7.如何处理当前时间提前1天,提前四小时
"""
提前当前时间的处理
"""
import time
import datetime
print(time.localtime())
print(time.time()) # 时间戳
print('*'*30)
# 当前时间提前两天
print('当前时间',datetime.date.today())
print('当前时间提前两天',(datetime.date.today() - datetime.timedelta(days=2)))
# 或
# print('当前时间提前两天',(datetime.date.today() - datetime.timedelta(days=2)).strftime('%Y/%m/%d'))
print('当前时间加一天',(datetime.date.today() + datetime.timedelta(days=1)))
print('*'*30)
print('当前时间',datetime.datetime.now())
print('当前时间加四个小时',datetime.datetime.now() + datetime.timedelta(hours=4))
print('当前时间加四个小时',(datetime.datetime.now() + datetime.timedelta(hours=4)).strftime('%Y-%m-%d %H:%M:%S'))
print('当前时间减去四个小时',(datetime.datetime.now() - datetime.timedelta(hours=4)).strftime('%Y-%m-%d %H:%M:%S'))
示图如下

除上述资料外,还附赠全套Python学习资料,包含面试题、简历资料等具体看下方。
👉CSDN大礼包🎁:全网最全《Python学习资料》免费赠送🆓!(安全链接,放心点击)
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python学习路线

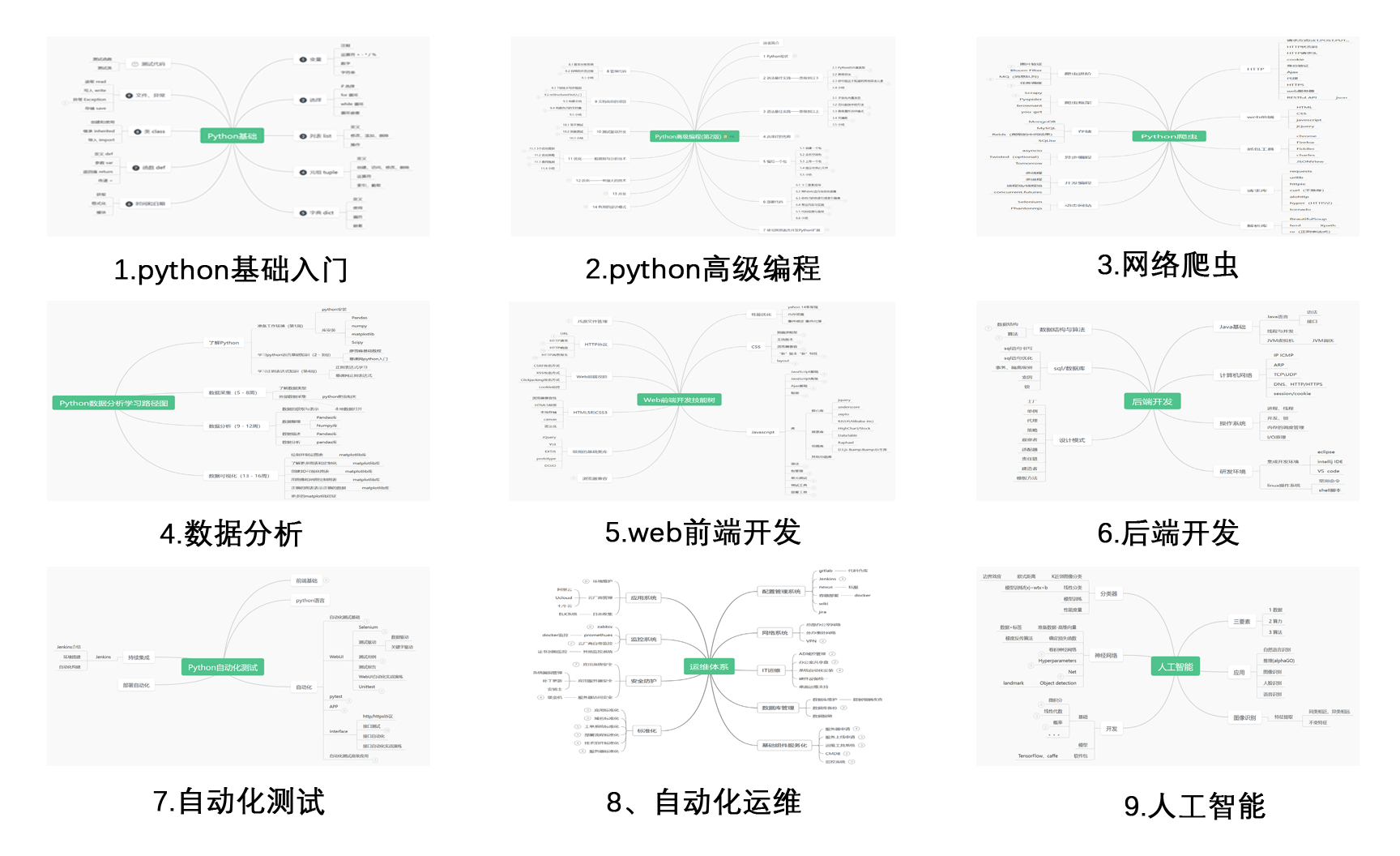
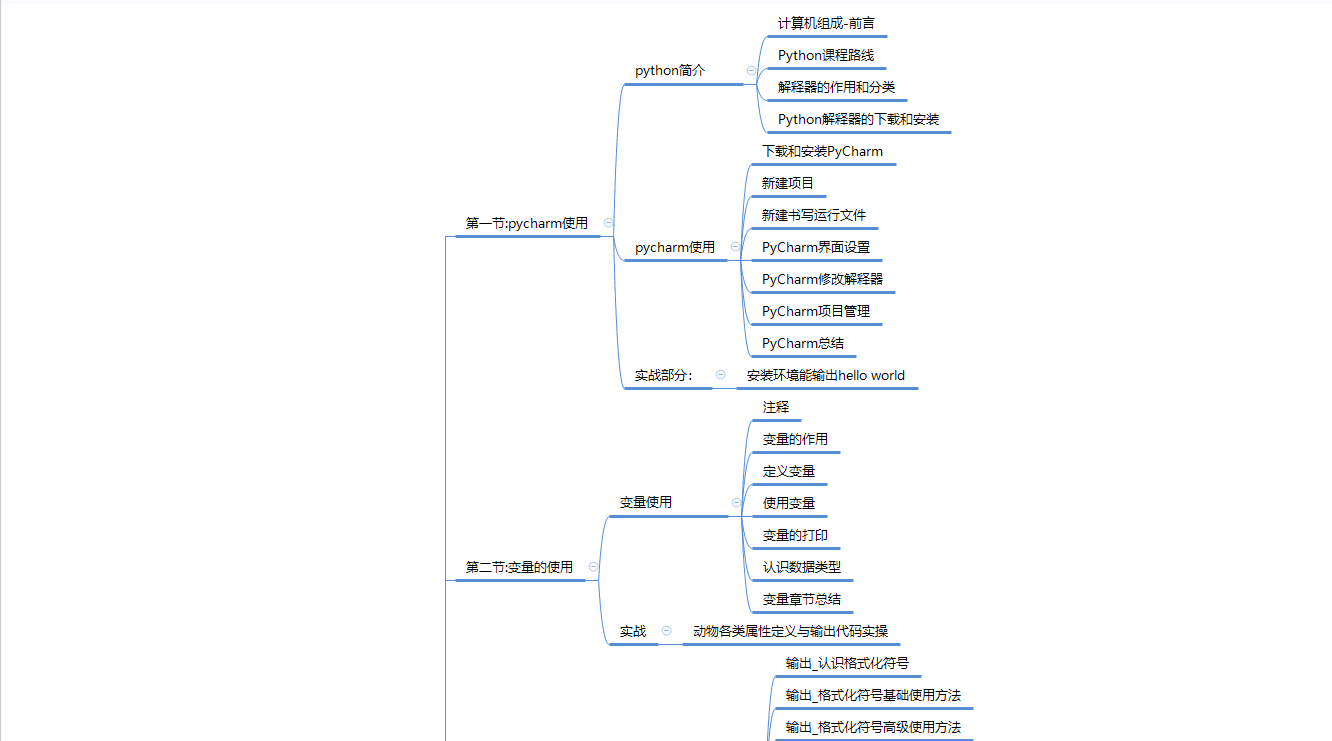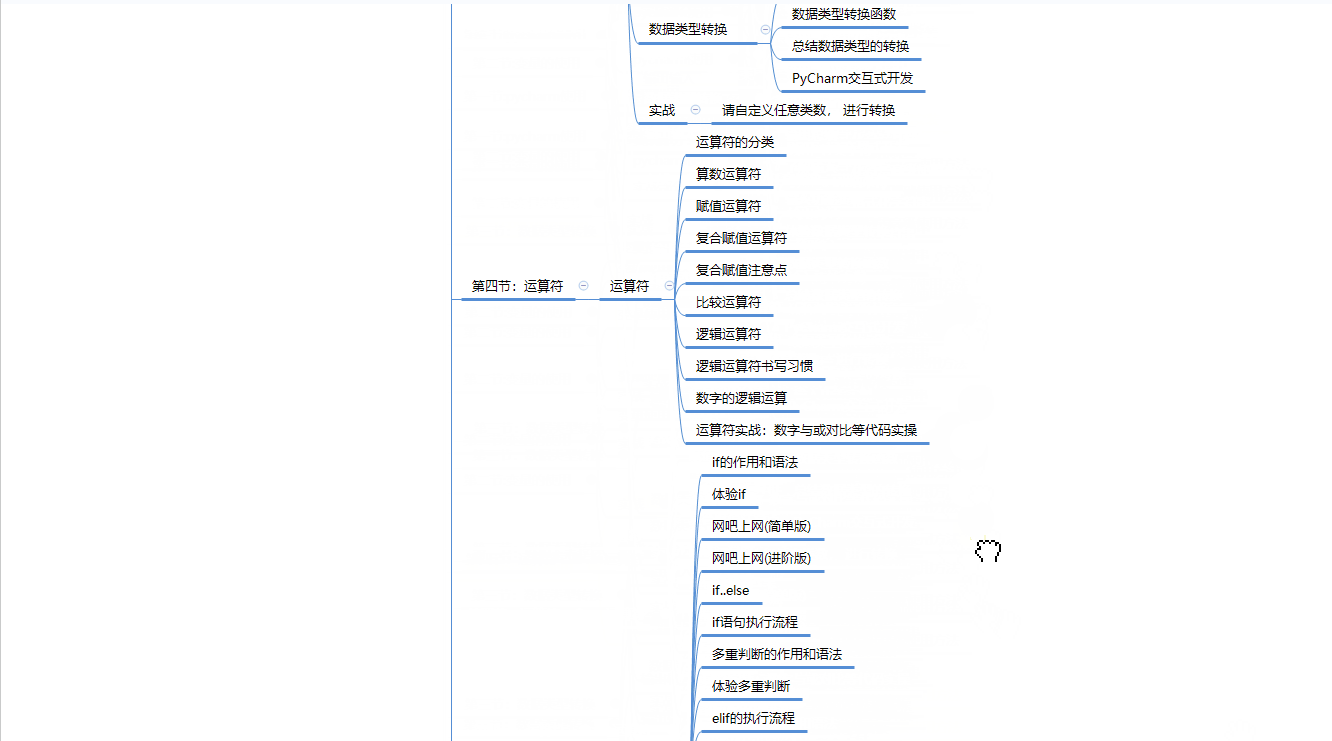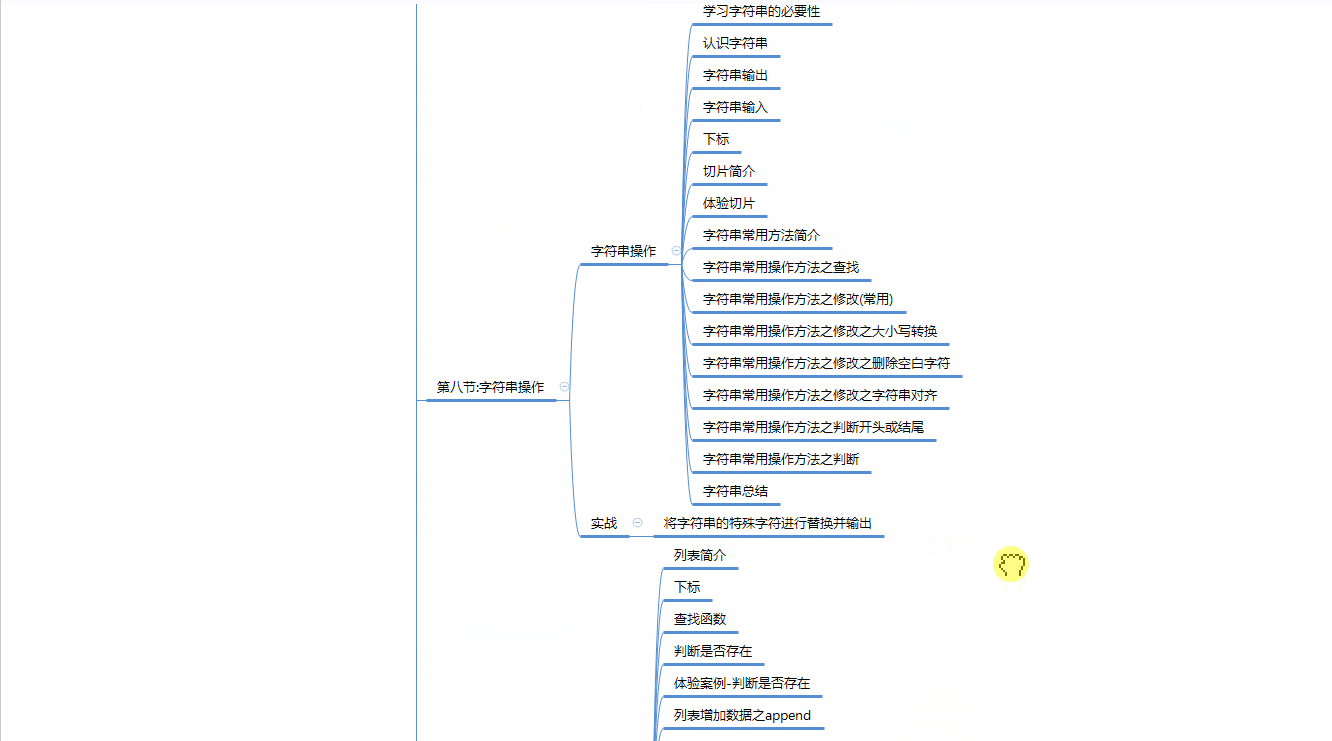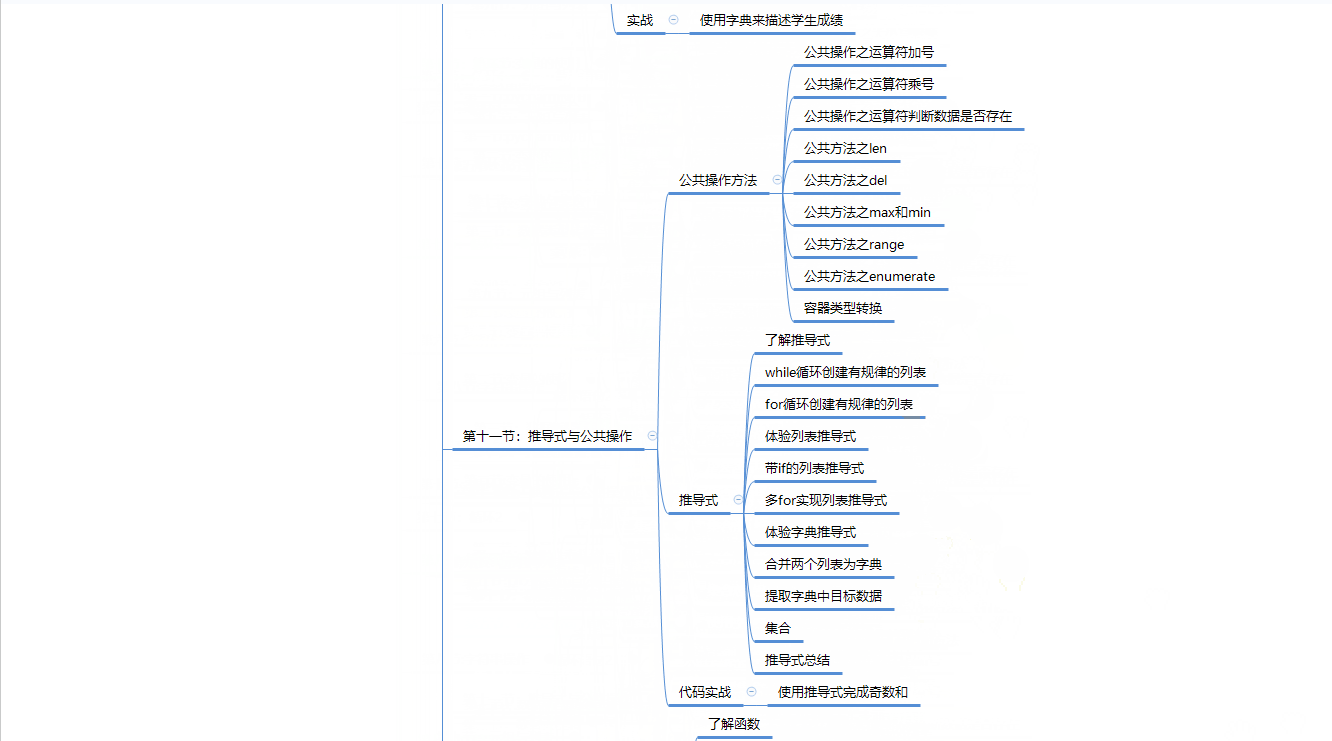
二、Python基础学习
1. 开发工具
2. 学习笔记
3. 学习视频
三、Python小白必备手册

四、数据分析全套资源

五、Python面试集锦
1. 面试资料


2. 简历模板
因篇幅有限,仅展示部分资料,添加上方即可获取














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









