






作者丨twn29004@知乎
来源丨https://zhuanlan.zhihu.com/p/457026913
编辑丨3D视觉工坊

论文链接:https://arxiv.org/abs/2004.04962
问题
本文首先说明了一个问题就是NMS是一个非常重要的去除预测结果中重复的后处理过程。一些工作已经发现在NMS中使用IOU来作为排序的标准能够取得更好的效果。这里作者还用一个实验证明了上述说法的正确性。
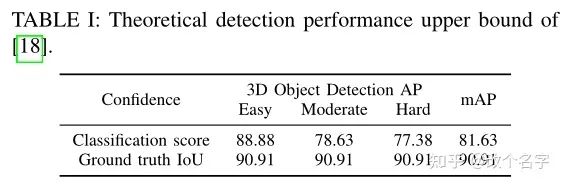
上表中的Ground truth IoU表示的是通过计算预测的边界框与基准值之间的IoU作为NMS中的分数的标准。从上表的结果可以看出,在使用IoU来知道NMS之后,模型的精度得到了非常大的提高。此外,之前的一些工作已经做出了使用预测IoU而不是预测class score来作为NMS的评分标准。大部分方法是通过增加一个IoU分支来直接简单的预测IoU,但是这些方法存在着两个问题:
1)直接增加一个IoU预测分支,而没有提取一些对于IoU预测很重要的特征。
2)另一个问题是IoU的预测存在着不对齐的问题。
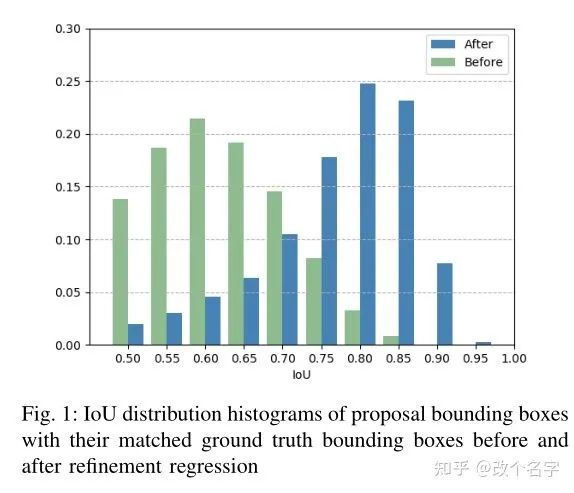
具体情况如上图所示,上述结果展示的是经过refine之后的IoU的分布和没有经过Refine的IoU的分布。在训练的时候,IoU预测分支是使用的proposal的特征和基准框之间IoU,但是在测试时候,这个预测值被当成了是预测的边界框与基准框之间的IoU.两者的IoU分布又不一致,这就带来了一定的不对齐问题。下面介绍作者针对上述两个问题提出的解决方案。
解决方法
没有相关特征的问题
针对上述问题,作者通过提出两个模型来解决。这两个模型分别叫 Attentive Corner Aggregation(ACA), Corners Geometry Encoding(CGE)模块。作者使用这两个模型来提取预测IoU所需的特征。从名字可以看出,都是关于Corner的。下面分别介绍这两个模块的工作方式。
ACA模块
首先介绍ACA模块,在介绍该模块之前,作者首先介绍了设计该模块的动机。
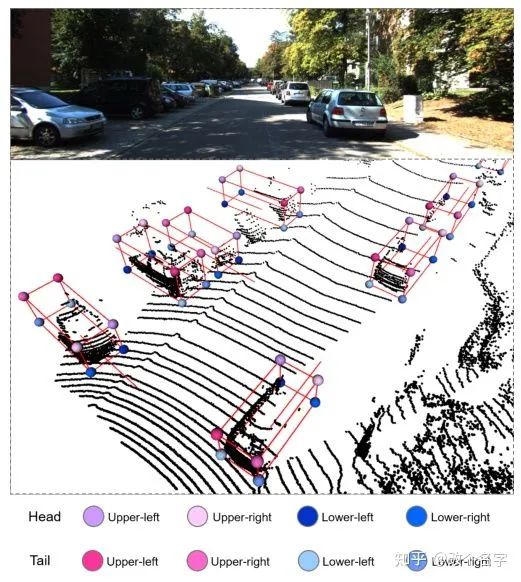
从上图中可以看出,不同角度观察到的目标的可视部分是一样的,这可能是不利于我们提取特征的,同时也不利于我们来提取对于预测IoU很重要的特征,因此作者设计了一下这个模块,按照作者的说法是这个模块可以在一定程度上减少因为观察的角度不同带来的提取特征的差异。
具体设计如下:
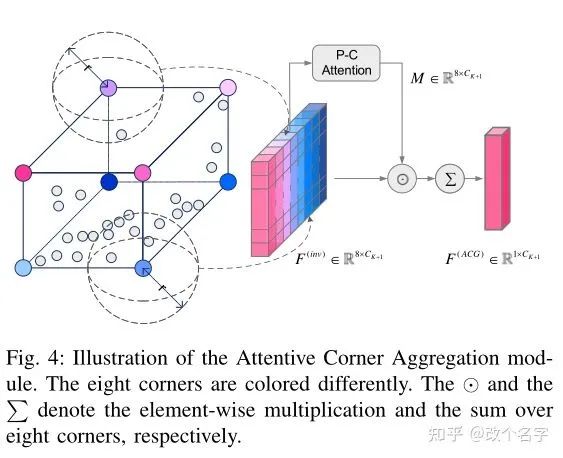
在使用PoineNet2生成Proposal,以及生成逐点的语义特征之后,作者使用上述方法来聚合proposal中的点,以生成每个proposal的特征。与PointRCNN中相似,作者同样使用PointNet2来提取Proposal中的特征,区别在于,是叠加了$K$个SA层之后,在第$K+1$层,作者没有再使用FPS来采样点,而是使用proposal的八个角点来作为采样后的点,然后搜索位于这个八个角点半径$r$以内的点,在使用PointNet来提取这些区域的特征,然后再在这些特征上应用注意力机制。具体的注意力机制如下图所示:
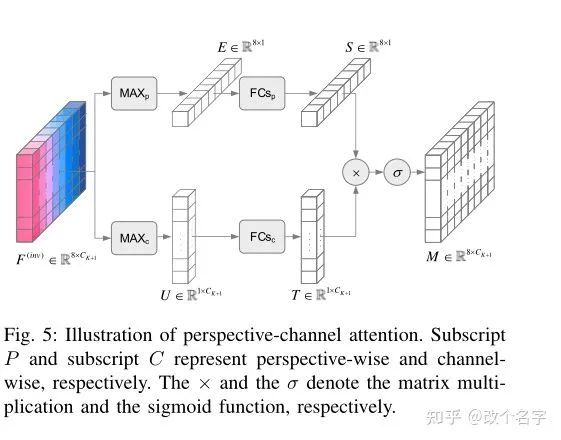
就是分别在不同的角点以及不同的通道层面做一次注意力机制。然后最后的特征是这八个角点的特诊之和。
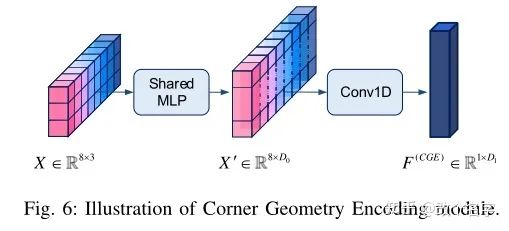
CGE模块
这个模块提出的目的是为了利用proposal的几何特征。上面提取的我们可以理解为语义特征。这部分的结果也非常简单,就是将proposal的八个角点的世界坐标作为神经网络的输入,其具体结构如下:
关于IoU预测不对齐的问题
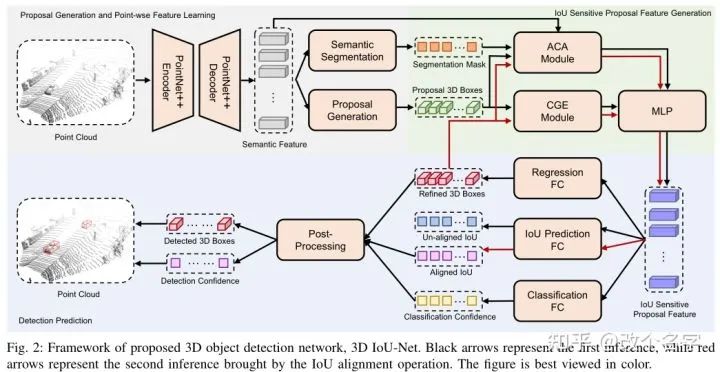
这部分的设计也很简单。具体操作看下图。在进行一次IoU预测之后,将预测的边界框作为Proposal在输入Proposal模块中重复一下,这样IoU分支最终预测的就是refine后的box和基准狂之间的IoU,这样就解决了不对齐的问题。值得注意的是,在重复一次的时候,只有IoU分支改变,其余分支是不变的。不然又会带来不对齐的问题。
解决效果
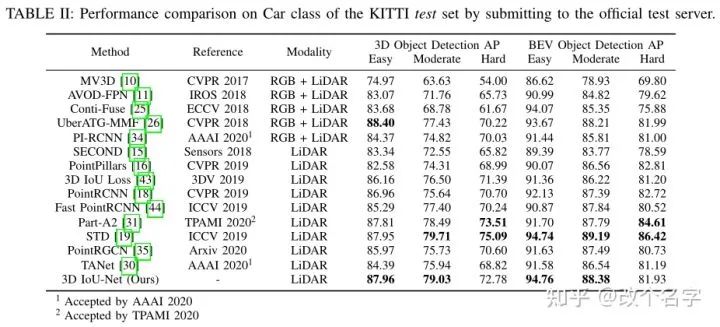
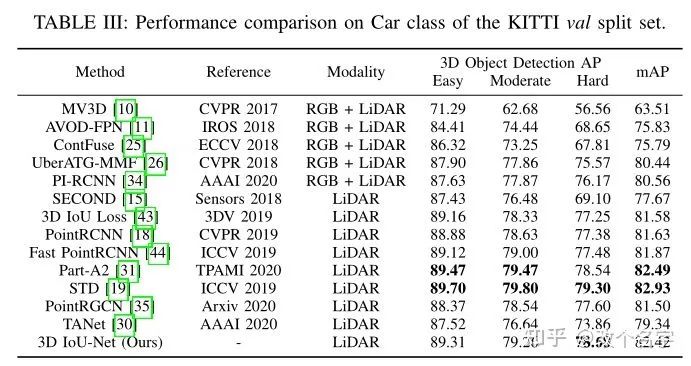
这是本文在Kitti测试集上取得的效果,这个效果一般般吧。为什么有的模型在验证集和测试集上的差距很小,而有的很大。是方法设计的问题吗?
消融实验
IoU对齐是否有效
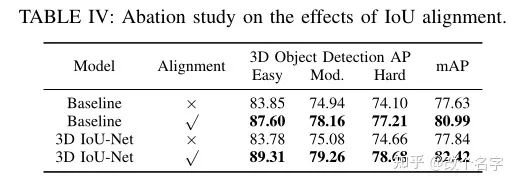
这里的baseline表示的是PointRCNN增加了一个IoU分支。Alignment中$\times$表示的是没有将预测生成的bbox在送到网络中,$\checkmark$表示的是重复了一次,此外,作者还做了一个关于置信度对齐的实验。其结果如下:
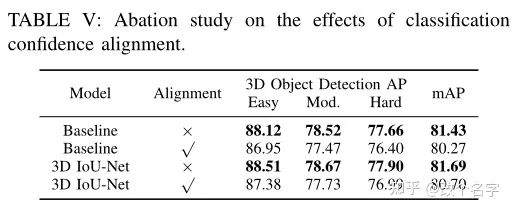
从上述表格中可以看出,置信度对齐不仅没有带来效果提升,来带来了下降。作者在文中仅简单的将其解释为置信度不使用于对齐操作。这个解释有点牵强,置信度同样也是预测的proposal的特征得到的置信度啊。
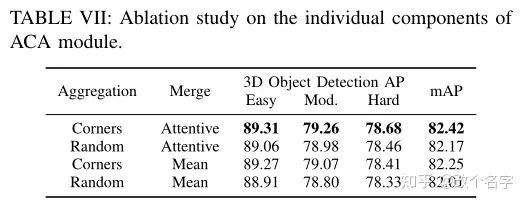
IoU相关特征模块有效性验证
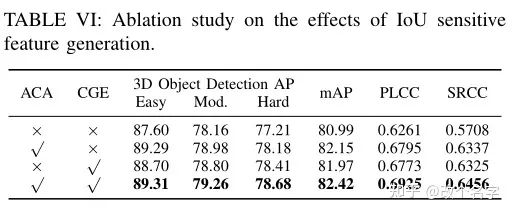
ACA模块中一些操作的对比实验。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉精品课程推荐:
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









