






作者:LRS | 来源:新智元
【导读】来自华南理工大学的研究团队提出了一种基于文本驱动的三维模型及材质生成方法Fantasia3D,是第一个被接收的能够产生逼真效果的AIGC3D工作。
受益于预训练的大型语言模型和图像扩散模型(Satble Diffusion等)的可用性,自动化三维内容生成近期取得了快速进展。
现有的文本到三维模型的生成方法通常使用NeRF等隐式表达,通过体积渲染将几何和外观耦合在一起,但在恢复更精细的几何结构和实现逼真渲染方面存在不足,所以在生成高质量三维资产方面效果较差。
在这项研究中,华南理工大学提出了一种用于高质量文本到三维内容创建的新方法Fantasia3D,关键之处在于对几何和外观进行解耦的建模和学习。

项目地址:https://fantasia3d.github.io/
对于几何学习,Fantasia3D依赖于显隐式结合的表达,并提出将渲染的表面法线图编码为Satble Diffusion的输入;对于外观建模,Fantasia3D引入了空间变化的双向反射率分布函数(BRDF)到文本生成三维模型的任务中,并学习生成表面的逼真渲染所需的表面材质。
解耦框架兼容目前的图形引擎,支持生成的三维资源的重新照明、编辑和物理仿真。
研究人员也进行了全面的实验,展示了该方法在不同的文本到三维生成任务设置下相对于现有方法的优势。
模型效果
对于给定的文本,Fantasia3D能够生成具有不同拓扑形状的三维模型以及具有照片级真实感的渲染表面。
同时,如下图1中右上角的狮子所示,由于使用了BRDF建模表面,Fantasia3D能产生较强的金属反射效果。

图1:三维模型生成效果
同时,Fantasia3D支持根据用户给定的粗糙三维物体和文本进行生成。
如下图2所示,给定一个粗糙的三维模型,Fantasia3D可将输入的粗糙模型作为初始化生成三维模型,这种优化方式可让生成过程更加快速和稳定,缓解文本到三维模型生成中的多面问题(Janus Problem)。

图2:根据用户给定的粗糙三维模型和文本进行生成。
另外,不同于现有的基于隐式表达(NeRF等)的方法,Fantasia3D采用了显隐式相结合的表达,生成的3D资产可以很好地与现有的图形渲染和仿真引擎相结合。
如下图3 (a) (b) 所示,生成的三维模型可以导入Blender中进行布料和软体的物理仿真,图3 (c) 则展示了用Blender替换生成材质的实验结果。

图3: 在Blender中进行编辑。
如下图4 (a) 所示,Fantasia3D生成的模型还可在Blender中替换不同的光照,从而产生不同的渲染效果。
(b) 中展示了将Fantasia3D生成的物体插入其他场景中的能力,插入的物体能与原环境中的光照环境进行交互,从而产生自然的反射效果。
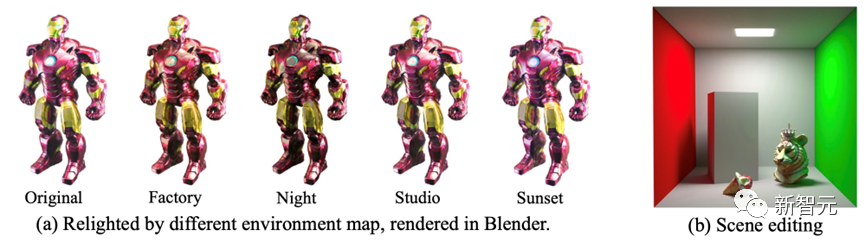
图4: 给生成物体进行重新打光。
原理方法
Fantasia3D的方法概览如下图5所示。我们的方法可以根据文本提示生成解耦的几何和外观(见图 (a) ),二者分别通过 (b) 几何建模和 (c) 外观建模生成。
在 (b) 中,我们采用DMTet作为我们的三维几何表示,这里初始化为一个三维椭球体。
为了优化DMTet的参数,我们将从DMTet提取的网格的法线贴图(在早期训练阶段还会同时使用物体掩码)渲染为Stable Diffusion的形状编码。
在 (c) 中,对于外观建模,我们引入了空间变化的双向反射率分布函数(BRDF)建模,并学习预测外观的三个分量(即kd、krm和kn)。几何和外观建模都由分数蒸馏采样损失函数(SDS loss)进行监督。
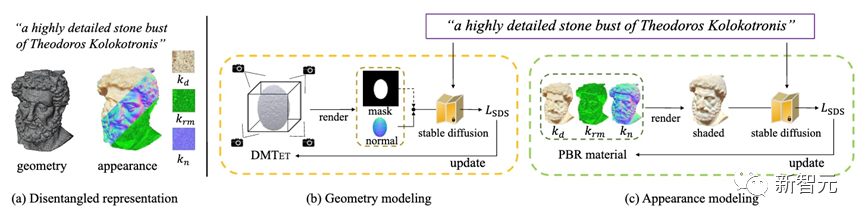
图5: Fantasia3D流程图。
总结
本文介绍了一种名为Fantasia3D的自动化文本到三维生成的新方法,基于DMTet的混合表达,采用几何和外观的解耦建模和学习,能够生成精细的表面和丰富的材质/纹理。
对于几何学习,研究人员提出将渲染的法线贴图编码,并将法线的形状编码作为预训练的Stable Diffusion的输入。
对于外观建模,引入了空间变化的BRDF到文本生成三维对任务中,从而实现对学习表面的逼真渲染所需的材质的学习。
除了文本提示外,该方法还可以根据自定义的三维形状来生成,这对用户来说更加灵活,可以更好地控制生成的内容。
另外,该方法还方便支持生成的三维资产的重新照明、编辑和物理仿真。
作者介绍

陈锐是一名华南理工大学的在读研一学生,导师是贾奎教授。他的研究兴趣在于计算机视觉和计算机图形学的结合,特别是使用生成模型和基于物理的渲染技术创建高质量的3D资产领域。

个人主页:https://cyw-3d.github.io/
陈永炜,华南理工大学GorillaLab研究生三年级。师从贾奎教授,研究方向为三维视觉,多模态学习,可微渲染,扩散模型等,相关研究工作曾在CVPR、ECCV、NeurIPS、ICCV等计算机视觉和人工智能顶级会议上发表。近期研究方向侧重探索能够自动生成3D资产的AI模型,包括材质、形状、动作和其他相关参数。

个人主页:http://kuijia.site/
贾奎,华南理工大学教授,几何感知与智能实验室主任,广东省「珠江人才计划」创新创业团队带头人。曾先后于中科院深圳先进技术研究院、香港中文大学、伊利诺伊大学香槟分校先进数字科学研究中心、及澳门大学从事教学和科研工作。
研究领域包括计算机视觉、机器学习、人工智能等,近年来主要侧重于深度学习理论与泛化、几何深度学习、以及3D AIGC等研究;成果发表于TPAMI/CVPR/ICML/NeurIPS等顶级期刊和会议。担任TMLR/TIP等期刊副主编及ICML/ICCV/NeurIPS等会议领域主席。
几何感知与智能实验室(Gorilla Lab)聚焦机器学习、计算机视觉、三维感知等人工智能核心方向,侧重从语义感知和内容生成等角度,以学习数据内在的几何规律性和外在的几何表征为核心方法指导,对图像、视频、点云等高维数据进行智能处理,以推进相关领域发展和产业化落地。自成立以来,实验室先后获得来自国家自然科学基金委、广东省科技厅、华为技术有限公司等数千万的经费支持。
贾奎教授实验室提供多个博士后、博士、研究型硕士及研究助理岗位,有兴趣从事人工智能、计算机视觉、三维感知与生成研究的同学,请发信至 kuijia@gmail.com 。
参考资料:
https://fantasia3d.github.io/
—END—高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]如何高效学习基于LeGo-LOAM框架的激光SLAM?
[2]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[3](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[4]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[5]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2]面向自动驾驶领域目标检测中的视觉Transformer


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









