






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0.这篇文章干了啥?
这篇文章介绍了一种名为SPVLoc的方法,用于在室内环境中进行6D相机定位,即准确确定相机在室内环境中的位置和方向。该方法利用了简单的语义纹理化的3D场景模型,并通过新颖的图像匹配方法将透视图像与全景图像、RGB图像与语义图像进行匹配。通过在稀疏参考采样下进行高效和可扩展的匹配和检索,该方法能够提高定位的准确性和推理速度。与现有技术方法相比,SPVLoc方法在定位准确性和推理速度方面表现更好,并且通过包含3D模型,能够减少估计6D姿态时的歧义。文章还探讨了未来将定位和图像分析相结合以增强数字建筑模型或在增强现实场景中应用的可能性。
下面一起来阅读一下这项工作~
1. 论文信息
论文题目:SPVLoc: Semantic Panoramic Viewport Matching for 6D Camera Localization in Unseen Environments
作者:Niklas Gard等
作者机构:Fraunhofer Heinrich Hertz Institute等
论文链接:https://arxiv.org/pdf/2404.10527.pdf
2. 摘要
本文介绍了SPVLoc,一种全球室内定位方法,能够准确确定查询图像的六维(6D)相机姿态,需要最少的场景特定先验知识和无需场景特定训练。我们的方法采用一种新颖的匹配过程,在室内环境的一组全景语义布局表示中定位透视相机的视口,该表示以RGB图像形式给出。这些全景图是从未纹理化的3D参考模型中渲染出来的,该模型仅包含关于房间形状的近似结构信息,以及门和窗户的注释。我们证明了一个直接的卷积网络结构可以成功实现图像到全景图的匹配,最终实现图像到模型的匹配。通过视口分类分数,我们对参考全景图进行排名,并选择最佳匹配的查询图像。然后,估计所选全景图与查询图像之间的6D相对姿态。我们的实验表明,这种方法不仅有效地弥合了域之间的差距,而且对于以前未见过的不属于训练数据的场景具有很好的泛化能力。此外,与最先进的方法相比,它实现了更高的定位精度,还估计了相机姿态的更多自由度。我们将在以下网址公开我们的源代码:https://github.com/fraunhoferhhi/spvloc。
3. 效果展示
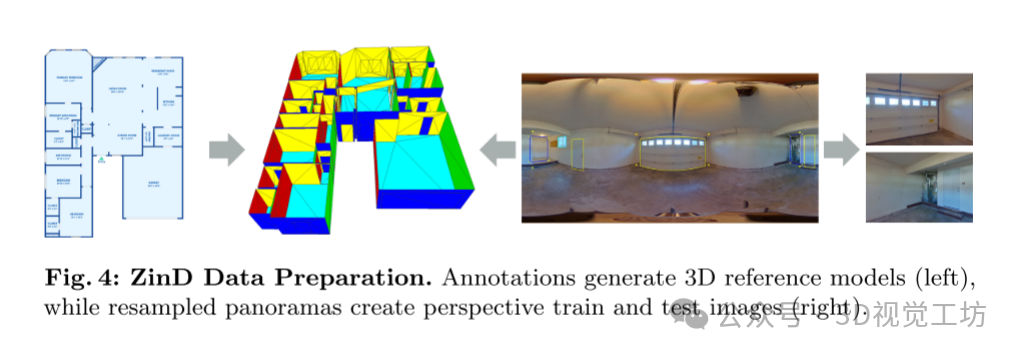
ZinD数据准备。注释生成3D参考模型(左),而重新采样的位图创建透视训练和测试图像(右)。
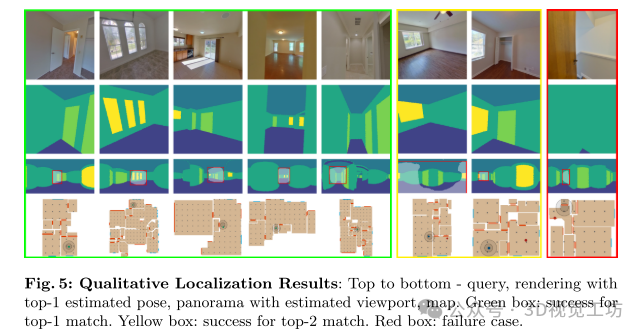
定性定位结果:从上到下-查询,使用top-1估计姿势渲染,使用估计视口的全景,地图。绿色框:前1名匹配成功。黄框:前2名比赛成功。红框:失败案例。
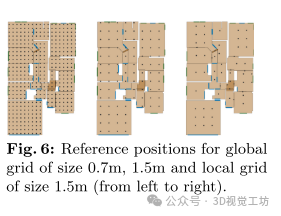
0.7m、1.5m全球网格和1.5m局部网格的参考位置(从左至右)。
4. 主要贡献
为未知室内环境引入了一种基于模型的6D相机姿态估计系统,无需进行特定场景的训练。
提出了一种新颖的透视到全景图像匹配概念,即使在宽基线相机下也具有很高的检索准确性。
与最先进的方法相比,我们的方法表现出更高的定位精度,同时估计更多的自由度。
5. 基本原理是啥?
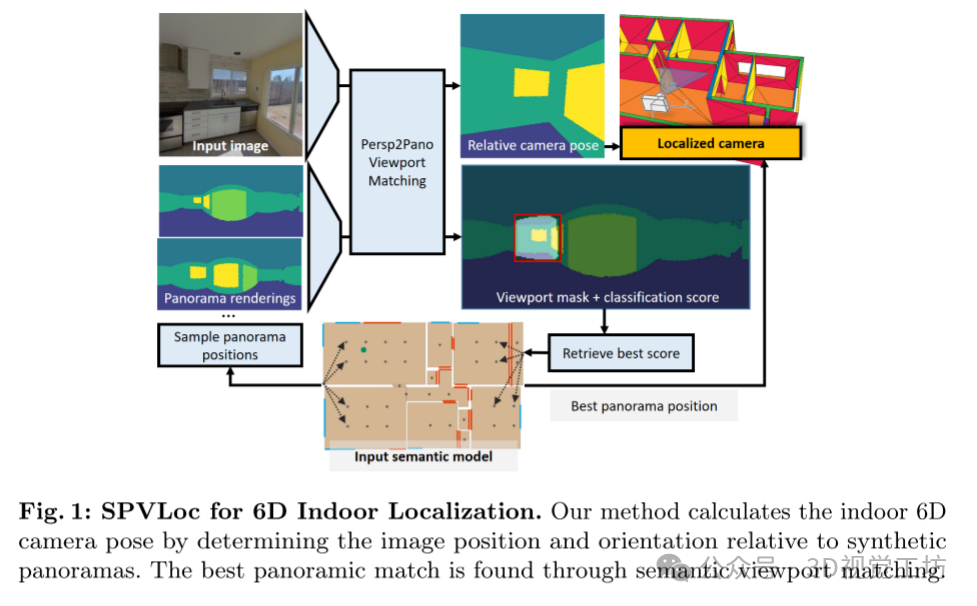
这篇文章介绍了一种名为SPVLoc的方法,用于在室内进行2D RGB图像的6D定位。该方法的基本原理是利用语义无纹理的3D场景模型,通过跨领域图像到全景图像匹配来估计图像的视口,然后通过相对6D姿态回归来确定图像相对于最佳匹配的参考全景图的姿态。文章主要包括以下几个步骤和关键点:
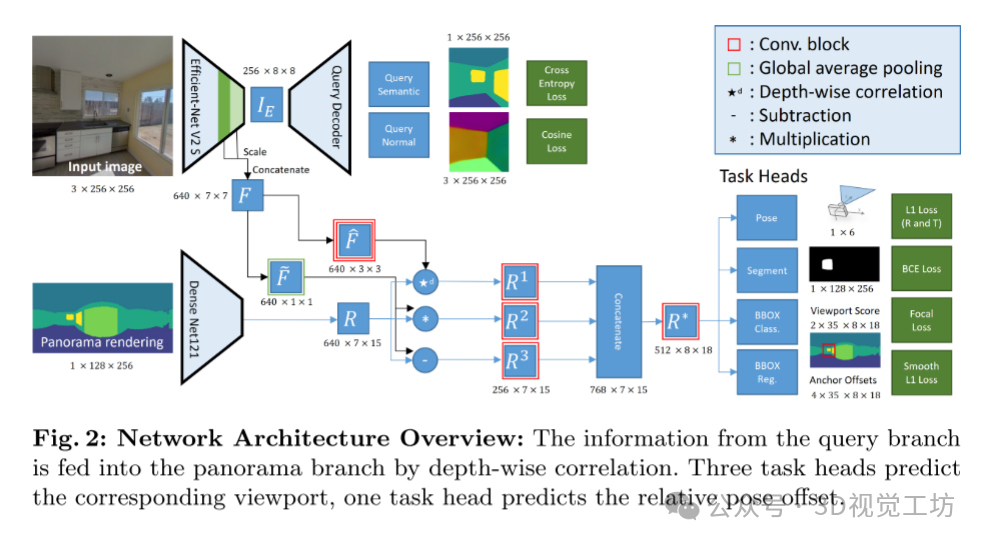
语义全景视口匹配(Semantic Panoramic Viewport Matching):将室内定位问题重新定义为跨领域图像到全景图像匹配问题。通过创建语义全景参考渲染,并利用透视摄像机的视角来确定全景图中视口的位置。视口的确定涉及计算视口蒙版和边界框,并通过网络预测。
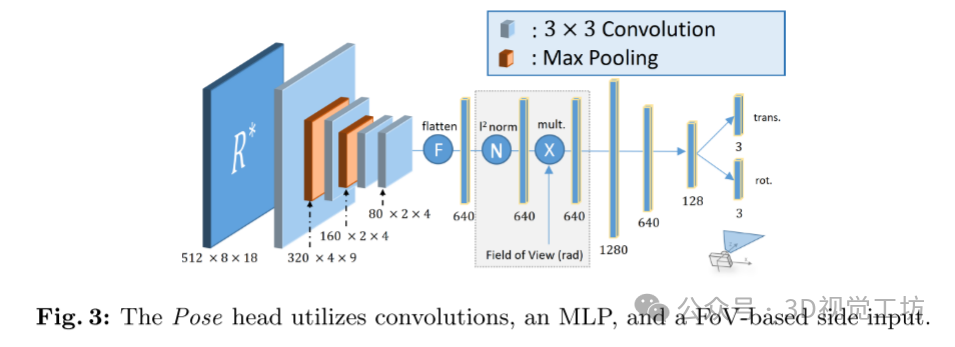
特征相关的姿态回归(Feature-Correlation-based Pose Regression):通过对视口信息进行特征相关,编码了图像在全景图中的视口信息,并使用这些信息来估计相机的相对姿态偏移。这一步骤的目的是确定图像相对于全景图的精确位置。
优化(Optimization):在训练过程中,使用多任务学习来平衡不同损失函数的权重,以提高模型的准确性和稳健性。优化过程包括对姿态偏移和视口的预测进行损失计算和权重调整。
推理(Inference):在推理阶段,通过在楼层平面上叠加的固定2D网格确定全景位置,并选择具有最高分类分数的参考位置。然后根据Pose头的结果确定绝对姿态,并通过渲染新的参考全景图来提高姿态估计的精度。
6. 实验结果
本文主要介绍了一种用于室内环境的6D相机定位的方法,通过结合全景图像和语义3D模型,实现了在未知场景中的高精度定位。
数据集:
使用了两个公开数据集:Structured3D (S3D) 和 Zillow Indoor (ZInD)。
S3D包含3500个近乎照片般逼真的室内环境模型,每个模型都带有地面真实的3D结构信息,包括21835个全景图像。
ZInD包含67448个全景图像,拍摄于1575个未装修的住宅,所有图像都在全球范围内对齐并注册到一个楼层平面图上。
数据预处理:
在训练之前,将所有数据转换为统一的格式。
训练细节:
使用变焦视角的模型进行训练,其中随机采样视角在45到135度之间。
对每个查询一致地在±r1(xy方向)和±r2(向上)的半径内渲染s个随机位置的全景图像。
使用一个随机负例在不同房间生成,以增强网络对细微房间差异的识别能力。
使用随机偏航和±10°的随机俯仰和滚动角度对图像进行采样。
批处理大小设置为40,包括40个查询图像和200个全景图像,并在单个NVIDIA A100 GPU上进行训练。
在损失计算过程中,忽略语义类别少于三个的查询图像。
训练大约42000步,初始学习率为2.5×10^-4,在训练过程中减半两次。
测试细节:
在测试期间,对全景图像进行1.2×1.2米的网格采样。
为了评估2D定位的准确性,报告了3D旋转和平移误差。
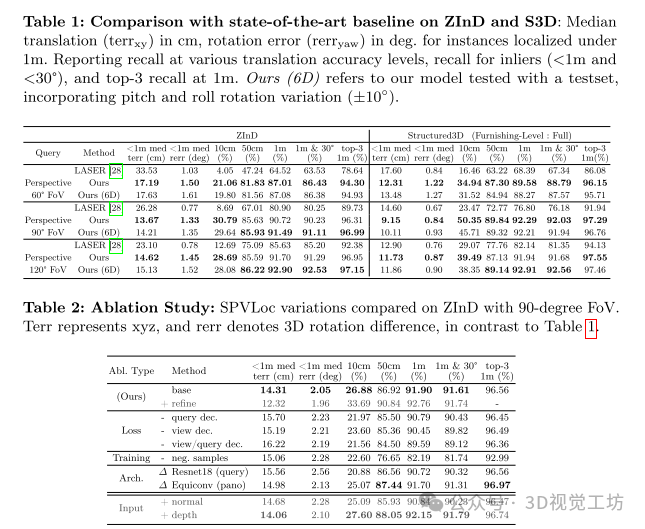
与最新技术的比较:
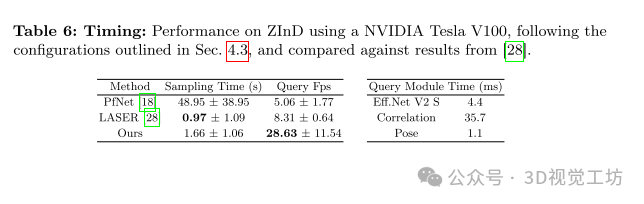
与LASER方法进行比较,表现出更高的定位准确性和召回率。
LASER方法只估计两个位置和一个旋转自由度,而SPVLoc方法估计完整的6D姿态。
消融研究:移除特定组件会降低网络性能,如透视监督和视图分段任务头。
移除来自不同房间的负样本会显著降低定位准确性。
将图像编码器EfficientNet-S替换为更小的ResNet-18会导致性能下降。
将全景编码器的所有卷积层替换为Equiconv不会带来性能提升。
添加额外的全景图像输入模态会略微提高结果。
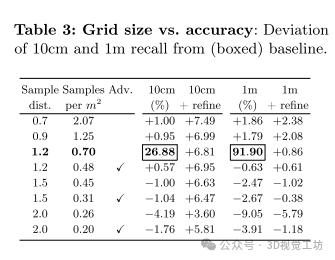
性能研究:
使用本地网格代替全局网格可降低完全错过房间的风险,并在10cm召回率上提高性能。
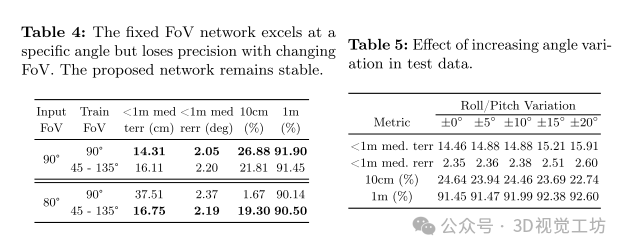
使用已知相机焦距训练的网络在匹配图像方面表现略好,但在测试不同焦距的图像时失去精度。
网络能够处理不同俯仰和滚转角度的测试图像,表现出鲁棒的估计能力。
限制:
在大型重复房间布局的空间中,方法的有效性可能受到语义参考模型细节的限制。
7. 总结 & 未来工作
本文介绍了一种用于室内场景的场景无关基于模型的6D定位方法,涉及一种新颖的多模态图像匹配方法(全景图像到透视图像,RGB到语义)。匹配和检索在稀疏参考采样下高效且可扩展。定位准确性和推理速度优于现有技术方法,而3D模型的包含减少了估计6D姿态的歧义。未来的工作涉及将定位和图像分析相结合,以增强数字建筑模型或探索在增强现实场景中的应用。
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









