






本次分享我们邀请到了香港科技大学在读博士生曹洋,为大家详细介绍他们的工作:CoDAv2.如果您有相关工作需要分享,欢迎文末联系我们!

Collaborative Novel Object Discovery and Box-Guided Cross-Modal Alignment for Open-Vocabulary 3D Object Detection
代码主页:https://github.com/yangcaoai/CoDA_NeurIPS2023
直播信息
时间
2024年6月11日(周二)晚上20:00
主题
开放词汇3D物体检测新SOTA-CoDAv2
直播平台
3D视觉工坊哔哩哔哩
扫码观看直播,或前往B站搜索3D视觉工坊观看直播
3DCV视频号也将同步直播
嘉宾介绍

曹洋
香港科技大学在读博士生。研究方向为3D视觉,开放词汇感知和多模态学习,获Huawei PhD Fellowship,担任TPAMI, TIP, NeurIPS, CVPR, ICCV, ECCV, ICLR, ICML, ICRA等学术期刊及会议审稿人。
直播大纲
NeurIPS2023工作CoDA详解
最新拓展工作CoDAv2详解
代码、数据用法简介
论交流
参与方式

摘要
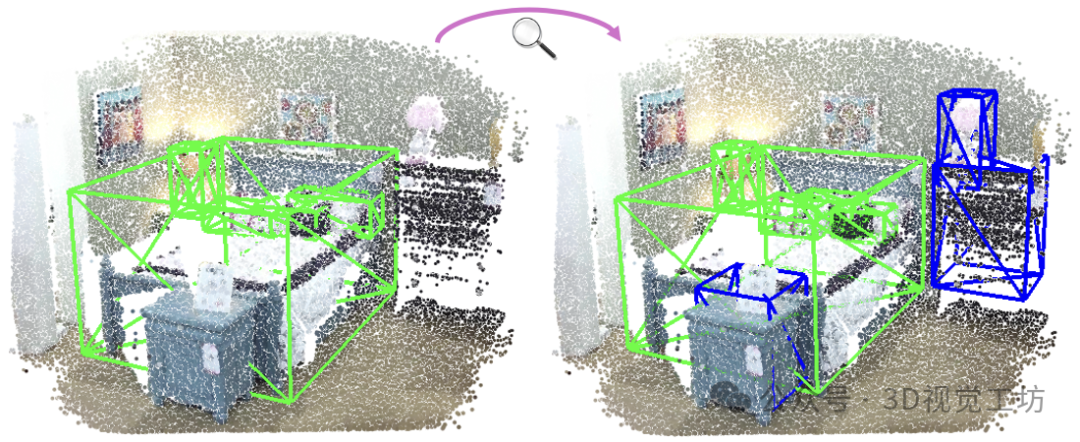
开放词汇3D物体检测(OV-3DDet)针对的是在3D场景中检测来自任意新类别列表的物体。如上图所示,模型仅由绿色框表示的基础类别 (base category) 的标注训练,但却可以检测出蓝色框表示的新颖类别 (novel category) 的物体。这仍然是一个非常具有挑战性的新问题。在这项工作中,我们提出了CoDAv2,这是一个统一的框架,旨在创新地解决有限基础类别条件下新颖3D物体的定位和分类问题。对于定位,我们提出的3D新颖物体发现(3D novel object discovery, 3D-NOD)策略利用3D几何先验和2D开放词汇语义先验在训练期间发现新物体的伪标签。3D-NOD进一步扩展了一个数据丰富策略(Enrichment),显著增加了训练场景中新颖物体的分布,然后提高了模型定位更多新物体的能力。带有Enrichment策略的3D-NOD被称为3D-NODE。对于分类,发现驱动的跨模态对齐(Discovery-driven cross-modal alignment, DCMA)模块将3D点云和2D/文本模态的特征进行对齐,采用类不可知和类特定的对齐方式,这些对齐方式经过迭代细化,以应对不断扩展的物体词汇表。此外,2D框指导提高了模型在复杂背景噪声中的分类准确性,这被称为Box-DCMA。广泛的评估证明了CoDAv2的优越性。CoDAv2的表现大幅超过了最佳性能方法(在SUN-RGBD上的AP_Novel为9.17 vs. 3.61,在ScanNetv2上为9.12 vs. 3.74)。
方法
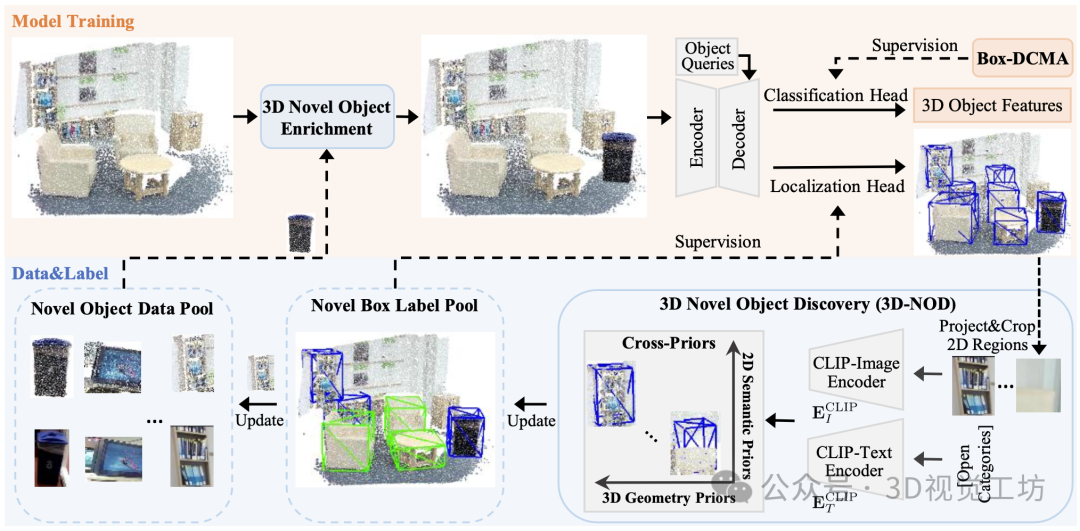
上图展示了CoDAv2的整体框架,该框架的检测backbone选择了3DETR,采用其编码器和解码器网络。在这个设置中,物体查询和点云特征由解码器处理,以细化查询特征,然后将这些特征引导到3D物体的分类和定位头。我们提出了一种新的方法,3D新颖物体发现(3D-NOD),该方法利用预测中的3D几何先验和预训练CLIP模型中的2D开放词汇语义先验,促进在训练阶段发现新颖物体。在此基础上,我们设计了3D新颖物体丰富(Enrichment)方法来扩展3D-NOD。此方法在整个训练过程中维护一个在线新颖物体数据池,并通过从该池中采样的新颖物体来增强训练场景。带有丰富策略的3D-NOD被统称为3D-NODE。发现的新颖框标签也被收集到一个在线新颖框标签池中,以支持我们的发现驱动的跨模态对齐(DCMA),该对齐包括类不可知蒸馏 (class-agnostic distillation) 和类特定的对比对齐 (class-specific contrastive alignment)。3D-NOD和DCMA之间的协同作用通过端到端的方式促进了有效的新颖物体检测和分类。此外,我们提出用2D框指导扩展DCMA,称为Box-DCMA,该方法通过来自OV-2DDet模型的预测2D框增强了区分背景框和前景框的能力。
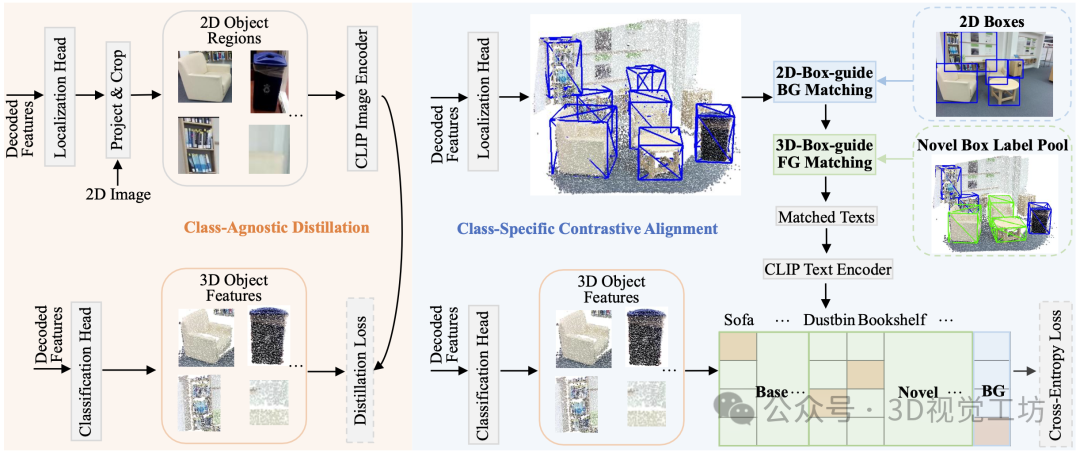
上图展示了Box-DCMA。其由两个主要组件组成:类不可知蒸馏(class-agnostic distillation, 左面板)和类特定对比特征对齐(class-specific contrastive alignment, 右面板)。首先,从检测头预测的3D框被投影以获得2D图像物体区域。这些区域随后由CLIP图像编码器编码以生成相应的2D物体特征。接下来,这些从CLIP导出的2D特征和3D点云物体特征被输入到类不可知蒸馏模块中以实现特征对齐。此外,通过3D-NOD动态更新的新颖框标签池在训练期间通过3D-Box-guide FG Matching将预测的3D前景物体框与前景类别文本对齐。背景区域使用2D-Box-guide BG Matching与背景类别文本对齐。我们对匹配的框执行对比对齐,以学习更具辨别性的3D物体特征。这些增强的3D物体特征随后有助于准确预测新颖物体。
实验
我们的实验在两个具有挑战性的3D物体检测数据集上进行,即SUN-RGBD和ScanNetv2。SUN-RGBD包含超过5000个训练样本,而ScanNetv2包含超过12000个训练样本。其中,SUN-RGBD包含10类基础类别(base category)和36类新颖类别(novel category),ScanNetv2包括10类基础类别和50类新颖类别。评估指标是交并比(IoU)阈值为0.25的mAP。
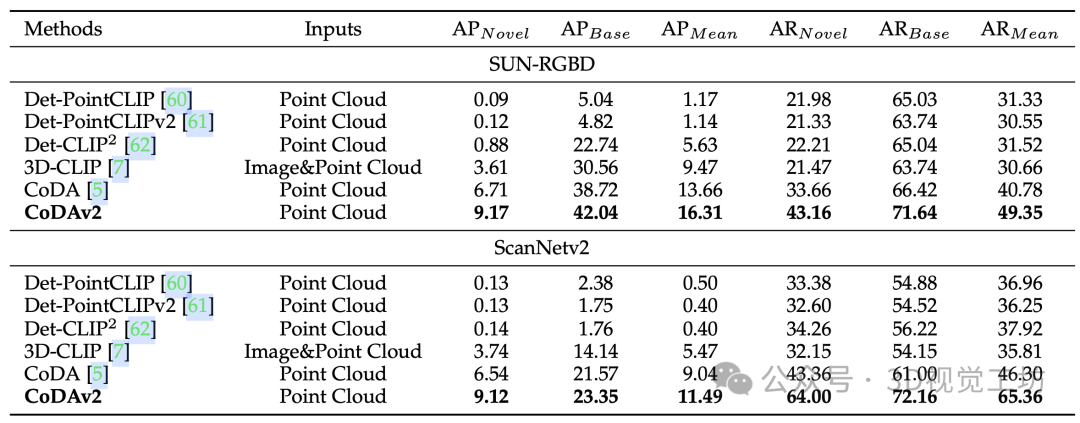
上图是在SUN-RGBD和ScanNetv2上的效果对比,我们的CoDA和CoDAv2显著地领先了其他方法。其中,在SUN-RGBD数据集中,CoDAv2比3D-CLIP高出超过 150%。同样地,在ScanNetv2数据集中,CoDAv2比3D-CLIP高出超过140%。这些优势充分证明了我们方法的有效性。
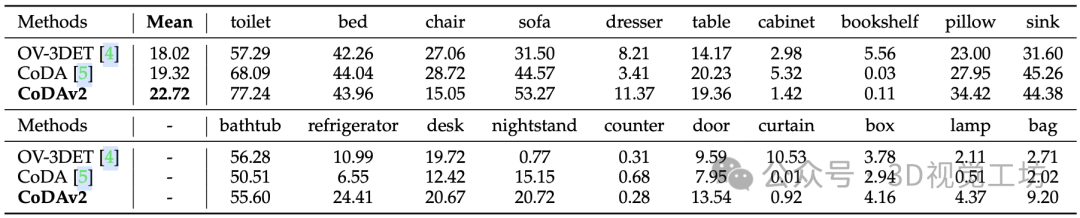
同时,我们也在OV-3DET的setting上进行了更多对比,如上图所示,在ScanNetv2数据集中,CoDAv2模型实现了平均AP的显著提升,增加了4.7点,从而验证了我们方法的优越性。

上图是关于不同方法预测样本的对比。通过对前两列样本的比较可以观察到,借助我们3D-NODE的增强,CoDAv2能够检测到更多的新颖物体,例如在2D彩色图像中由蓝色框标出的边桌。在分析后两列时,受益于我们的Box-DCMA,CoDAv2不仅识别出更多的新颖物体,例如由蓝色框标出的回收箱,还有效避免了引入额外的背景噪声框。
总结
在本文中,我们提出了一个统一的框架,称为CoDAv2,以应对开放词汇3D物体检测(OV-3DDet)中的核心挑战,该挑战目标是同时定位和分类新颖物体。为了实现3D新颖物体的定位,我们提出了3D新颖物体发现(3DNOD)策略,该策略利用3D几何先验和2D开放词汇语义先验,在训练期间增强新颖物体的发现。对于新颖物体的分类,我们设计了一个发现驱动的跨模态对齐模块(DCMA)。该模块结合了类不可知对齐和类区分对齐,以同步3D、2D和文本模态的特征。进一步地,我们通过设计3D新颖物体丰富策略 (Enrichment)和加入框指导 (Box guidance)来增强我们的贡献。Enrichment策略将新发现的新颖物体纳入训练3D场景中,从而增强模型检测新颖物体的能力,而Box guidance则在DCMA中设计,以提高背景与前景物体的区分能力。得益于我们的贡献,CoDAv2在两个具有挑战性的数据集上,即SUN-RGBD和ScanNetv2,显著优于表现最好的方法,超过140%。
注:本次分享我们邀请到了香港科技大学在读博士生曹洋,为大家详细介绍他们的工作:CoDAv2.如果您有相关工作需要分享,欢迎联系:cv3d008


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









