






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!
0. 这篇文章干了啥?
生成多样化和逼真的3D室内场景在计算机视觉和图形学领域引起了广泛的研究。近年来,这一问题在很大程度上受到公寓和房屋室内设计以及视频游戏和数据驱动的三维学习任务中自动3D虚拟环境创建的推动。
我们关注基于对象的3D室内场景合成,其目标是预测一组由语义标签和几何排列特征定义的对象。使用最先进的自回归模型的结果表明,虽然给定房间类型预测合理的对象标签相对容易,但主要瓶颈在于生成准确的对象几何排列,即预测现实的位置和方向。自回归模型可能会失败,因为它们无法撤销之前步骤中的不良预测。因此,“去噪”方法,即迭代细化预测结果的方法,更适合于这种类型的问题。
在这项工作中,我们提出采用扩散模型来解决这个问题,因为迭代去噪方案非常适合于改善3D场景中的对象几何形状。去噪扩散概率模型(DDPM)提出了连续域数据的高斯损坏和去噪,从而实现了扩散模型在图像合成任务中的高效训练。离散去噪扩散概率模型(D3PM)扩展了Hoogeboom等人的开创性工作,将其应用于离散状态空间中数据的结构化分类损坏过程。与连续扩散模型不同,离散扩散涉及使用离散状态之间的转移概率进行数据损坏和恢复。由于对象属性自然定义在离散和连续域上,我们提出将这些方法结合起来,形成用于3D场景合成问题的混合离散-连续扩散模型。
最近有几项工作采用扩散模型或迭代去噪策略来解决3D场景合成问题。与我们的工作最接近的是DiffuScene,它首先将语义标签转换为连续域中的独热编码向量,然后使用argmax检索标签预测,通过DDPM生成没有平面图约束的3D室内场景。相反,我们专注于基于地面的场景合成问题,因为这些问题在自动设计真实或虚拟世界中更为实用。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Mixed Diffusion for 3D Indoor Scene Synthesis
作者:Siyi Hu, Diego Martin Arroyo, Stephanie Debats, Fabian Manhardt, Luca Carlone, Federico Tombari
机构:MIT、谷歌、TUM
原文链接:https://arxiv.org/abs/2405.21066
代码链接:https://github.com/MIT-SPARK/MiDiffusion
2. 摘要
现实条件下的3D场景合成显著增强并加速了虚拟环境的创建,这还可以为计算机视觉和机器人研究等应用提供广泛的训练数据。扩散模型在相关应用中表现出色,例如对无序集合进行精确安排。然而,这些模型在基于地面的场景合成问题中尚未得到充分探索。我们提出了MiDiffusion,这是一种新颖的混合离散-连续扩散模型架构,旨在根据给定的房间类型、平面图和可能预先存在的对象合成合理的3D室内场景。我们通过2D平面图和一组对象来表示场景布局,每个对象都由其类别、位置、大小和方向定义。我们的方法在混合离散语义和连续几何域中独特地实现了结构化损坏,从而为反向去噪步骤提供了更好的条件问题。我们在3D-FRONT数据集上评估了我们的方法。实验结果表明,在基于地面的3D场景合成中,MiDiffusion明显优于最先进的自回归和扩散模型。此外,我们的模型可以通过损坏和掩蔽策略处理部分对象约束,而无需进行特定于任务的训练。我们展示了在场景完成和家具布置实验中,MiDiffusion相对于现有方法具有明显优势。
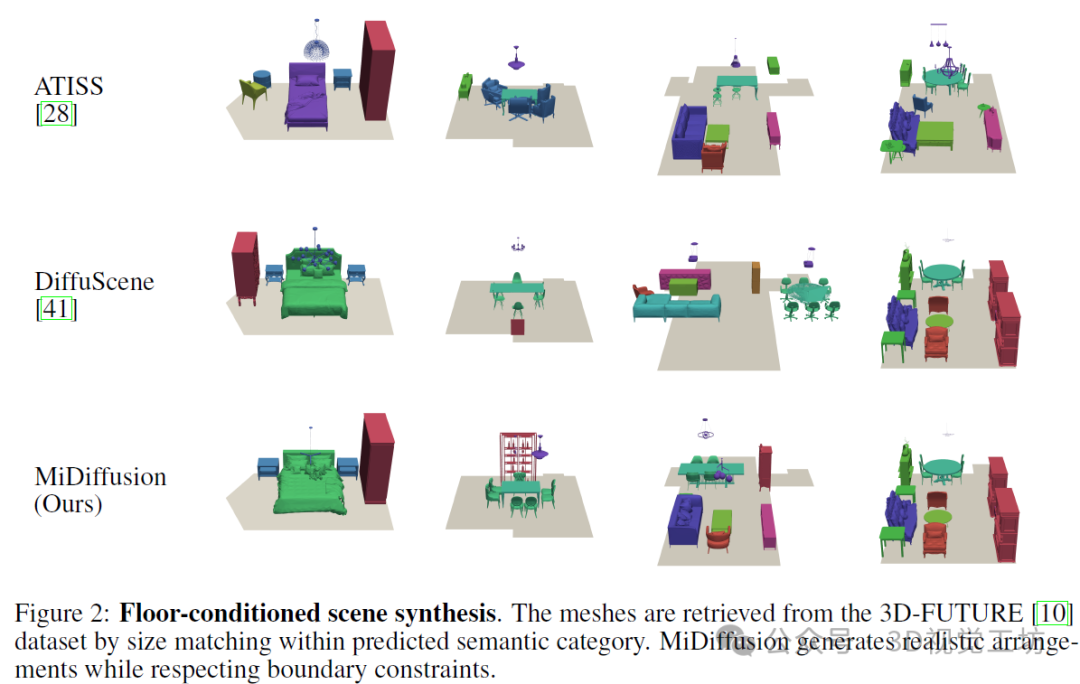
3. 效果展示
我们首先在无现存物体的基于地面的3D场景合成实验中,将MiDiffusion与基线进行比较。图2展示了在PyVista中呈现的定性结果。通过在预测的语义类别下找到尺寸最接近的匹配项,从3D-FUTURE数据集中检索到对象网格。为了清晰起见,我们用特定于标签的颜色替换了CAD模型中的原始纹理。我们在附录中包含了用于定量评估的正射投影图像示例。总的来说,我们的方法能够在尊重边界约束的同时生成逼真的对象排列。与两种基于扩散的方法相比,ATISS生成的对象放置位置略显粗糙,例如,图2中最后一个示例的桌椅家具组合并不完全对称。与我们的方法相比,DiffuScene和ATISS都更倾向于将对象放置在地面边界之外。这个问题在DiffuScene中更为突出,这很可能是由于其去噪网络中的条件U-Net架构没有像Transformer架构那样很好地学习边界约束。
4. 主要贡献
本文提出了以下三个技术贡献:
• 我们提出了MiDiffusion,这是一种新颖的混合离散-连续扩散模型,结合了DDPM和D3PM,以迭代去噪对象的语义和几何属性,这些属性自然定义在离散和连续域上。
• 我们设计了一个基于时间变量的Transformer去噪网络,以平面图特征作为条件向量,用于我们的混合扩散方法。
• 对于具有部分对象约束的应用,例如给定现有对象的场景补全,我们提出了一种损坏和掩蔽策略来处理已知对象条件,而无需重新训练模型。
我们将MiDiffusion与最先进的自回归和扩散模型在基于地面的3D场景合成问题中进行了比较。使用常见的3D-FRONT[9]数据集的实验评估表明,我们的方法能够生成更真实的场景布局,超越了现有方法。我们提供了支持混合扩散模型和去噪网络设计的消融研究。无需重新训练,我们还展示了在场景完成和家具排列上的实验评估,证实了我们的方法在大场景上依然保持卓越的性能。代码和数据可在https://github.com/MIT-SPARK/MiDiffusion上获取。
5. 基本原理是啥?
我们使用如图1所示的基于转换器的去噪网络,该网络在步骤t时接收潜在变量(zt, xt),并预测分类分布pθ(zt−1|zt, xt, y),同时假设固定协方差的高斯均值pθ(xt−1|xt, zt, y)。在测试时,我们可以简单地从这些分布中采样以检索(zt−1, xt−1)。
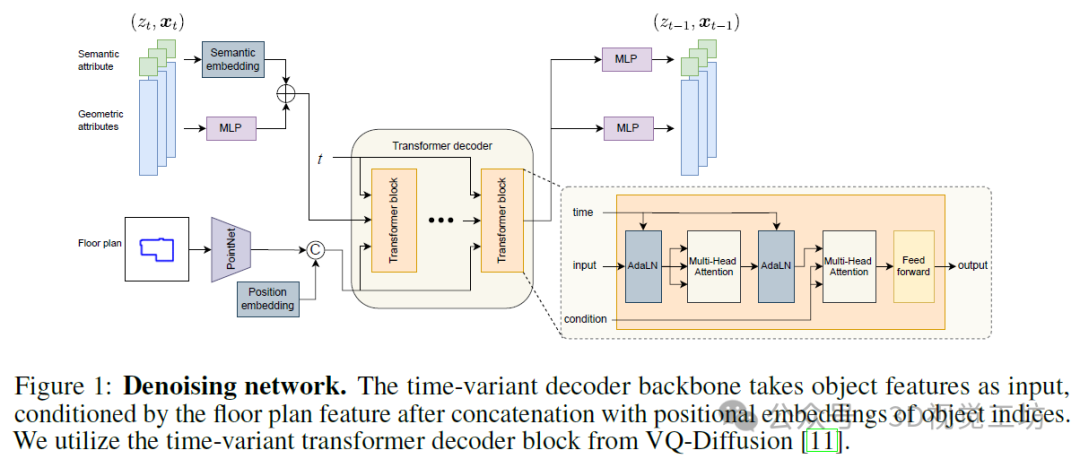
特征编码器。我们通过多层感知器(MLP)传递几何属性来编码对象特征,并将它们与可训练的语义嵌入相结合。对于每个场景,我们从平面图图像中沿着边界采样256个点,并计算向外的法向量。我们使用LEGO-Net中的PointNet平面图特征提取器,因为它比基于图像的特征提取器更轻便,且更好地捕捉地板边界。然后将平面图特征与转换器架构中常用的学习位置嵌入相连接,以形成条件向量。
转换器解码器。我们的去噪网络的主干是一个改编自VQ-Diffusion的时变转换器解码器。我们通过实验表明,转换器解码器中的多头注意力机制比DiffuScene中提出的条件1-D U-Net架构更好地捕捉边界约束。我们的去噪网络如图1所示。在每个转换器块内,通过自适应层归一化(AdaLN)操作器注入时间步长。条件输入通过多头交叉注意力层发送。
特征提取器。我们将转换器解码器的输出馈送到两个MLP中,以生成语义标签的分类分布和几何特征的高斯均值。
6. 实验结果
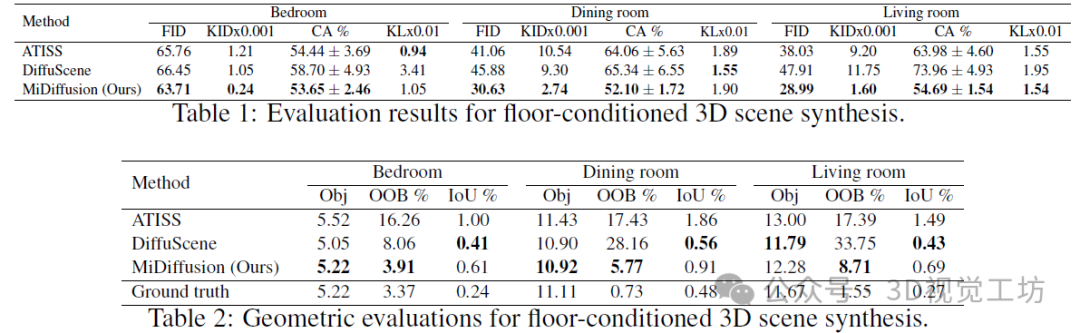
我们在表1和表2中展示了定量结果。总体而言,我们的方法在生成逼真的布局方面取得了显著更好的性能,特别是在餐厅和客厅数据集中。在比较合成布局的图像时,我们的模型与基线模型在FID、KID×0.001和CA%方面存在很大的差距。至于对象标签分布,在KL×0.01方面,各种方法之间似乎没有太大差异。事实上,所有方法的KL值都相当小,差异可能是由于随机抽样造成的。在表2中,在将对象保持在边界内(低OOB%)和保持最小重叠(低IoU%)之间存在权衡。尽管DiffuScene达到了最低的IoU%,但他们的模型往往比其他模型更容易将对象放置在边界之外,这解释了他们在表1中表现不佳的原因。总体而言,就与其他预测对象和地面边界约束兼容的对象放置而言,我们的方法仍然是最好的。
多样性。我们通过测量对象质心位置和边界框大小的平均标准偏差(std)来研究预测布局的多样性。由于垂直位置与语义标签高度相关,这些语义标签已通过KL散度进行评估,因此位置的标准偏差是在两个平面轴上取平均。结果如表3所示,其中“IB”后缀表示结果仅针对“在边界内”的对象进行计算,以消除不良的对象放置。然而,由于不同方法之间的OOB%存在很大差异,这些数字并不直接可比。尽管如此,我们的方法在平面图边界内生成了最多样化的对象放置(即Position-IB)。我们在大小(即Size-IB)上的多样性略低于DiffuScene,但我们的方法在去除边界外对象后,在大小多样性上的下降幅度最小。

消融研究。在表4中,我们研究了我们的混合扩散公式和PointNet平面图特征提取器的影响。我们提供了MiDiffusion的修改版本的结果:(1)使用DDPM和ResNet-18作为平面图特征提取器,如ATISS和DiffuScene中所做的;(2)使用DDPM和PointNet。最后一行展示了我们的方法MiDiffusion(即使用我们的混合扩散公式与PointNet结合)。第一种变体DDPM+ResNet类似于DiffuScene,除了我们使用基于Transformer的去噪网络而不是其U-Net对应物。请注意,表1中相应的结果已经超过了DiffuScene,这表明Transformer架构在学习边界约束方面表现更好。然而,KL散度存在很大的下降。接下来,虽然将ResNet楼层特征提取器替换为更轻量级的PointNet提取器为包含较少训练场景但房间尺寸较大的餐厅和客厅数据集带来了显著的性能提升,但在卧室数据集上的性能却下降了。这可能是因为PointNet在复杂且有限的训练数据下表现更好,但在将楼层平面图像转换为点和法线的过程中,在相反的情况下会受到采样噪声的影响。总的来说,我们使用完整的公式实现了最佳结果,其中混合扩散方法避免了像DDPM公式那样将离散输入提升到连续空间。

7. 限制性 & 总结
尽管我们的方法在不同的布局生成任务中显示出具有竞争力的性能,但它也有一些局限性:当前将对象定义为边界框特征和标签的集合并不是3D设置中最精确的表示,而充分理解3D特征可能会在这方面有所改善。此外,MiDiffusion仍然需要一个模型检索策略来构成最终的3D场景配置。未来,我们想研究使用强大的3D形状先验(例如,以点云或网格编码器的形式)并集成网格和纹理合成能力,类似于SceneTex,以增强真实感。最后,我们还计划研究如何消除每个房间需要单独模型的需求。
在这项工作中,我们介绍了MiDiffusion,这是一种新颖的混合扩散模型,结合了DDPM和D3PM,用于基于对象的3D室内场景合成。这种模型避免了像先前工作那样在连续域中采用语义标签的向量表示。我们设计了一种去噪架构,该架构具有时变Transformer解码器主干,并分别为离散语义属性和连续几何属性输出预测。我们提出了一种独特的损坏和掩蔽策略,以进行场景完成和家具布置,而无需重新训练我们的模型。我们使用常见的基准测试对最先进的自回归和扩散模型进行了广泛的实验评估。结果表明,无论是否存在部分约束,我们的方法都明显优于现有技术。我们还进行了消融研究,支持我们的混合扩散框架和去噪架构设计。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









