






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 这篇文章干了啥?
本文深入探讨了度量单幅图像深度估计领域,主要关注真实世界中的高分辨率输入。高分辨率深度估计在自动驾驶、增强现实、内容创作和3D重建中发挥着关键作用。尽管取得了显著进展,但现实世界场景中的高分辨率深度估计仍然具有挑战性。这一挑战主要是由于大多数最先进的深度估计架构固有的分辨率限制以及高质量现实世界深度数据集的稀缺性。
目前最先进的高分辨率深度估计方法PatchFusion采用了一种基于瓦片(tile-based)的策略来处理分辨率限制,将任务视为粗略和精细深度估计的融合过程。由于真实高分辨率深度数据集的稀缺性,PatchFusion转而使用合成4K数据集进行训练。然而,PatchFusion存在两个我们希望改进的限制:1) 它采用了一个三步训练过程,这不仅耗时且成本高,还可能导致框架达到阶段性局部最优,并限制了从端到端学习中可能获得的性能提升。2) PatchFusion在真实领域表现出较差的泛化能力。
从一般的角度来看,合成数据到真实数据的泛化能力较差是一个长期存在的问题。在深度估计的背景下,合成数据集与真实世界在度量尺度和深度分布上的差异进一步加剧了领域偏移。这导致在合成数据集上训练的深度模型在真实数据上的尺度准确性特别低。另一方面,真实数据集不仅分辨率低,而且由于传感器限制、遮挡等原因,往往还缺少真实值。这增加了深度模型在真实数据集上训练时捕捉锐利细节的能力不足。因此,人们面临着一个两难的选择——在真实数据集上训练可以获得良好的尺度准确性但高频细节较差,而在合成数据集上训练可以获得更锐利的结果但在真实图像上的尺度性能较差。
我们提出了PatchRefiner,一个将高分辨率深度估计重新定义为细化粗糙深度过程的新颖框架。我们在两个层面上提出了改进:
首先,与直接深度回归方法[30,42,46]不同,PatchRefiner利用一个冻结的粗糙深度模型,并通过预测残差深度来进行细化以提高质量。这种方法不仅简化了模型训练,还显著提高了性能。
其次,我们提出了一种方法,旨在结合两者的优点来解决上述的合成-真实数据之间的困境。我们采用了一种教师-学生框架,利用合成数据的清晰度,同时从真实数据中学习尺度。
预训练在合成数据上的教师模型为真实域训练样本生成伪标签。我们认识到,尽管这些伪标签提供了详细的特征,但存在尺度不准确的问题,因此我们引入了细节和尺度解耦(Detail and Scale Disentangling,DSD)损失。该损失结合了排序监督和尺度偏移不变性,其灵感来自于最近在相对深度估计方面的进展。它构建了一个框架,能够在现实环境中提供高分辨率的深度估计,同时保持精确的尺度和清晰的细节。
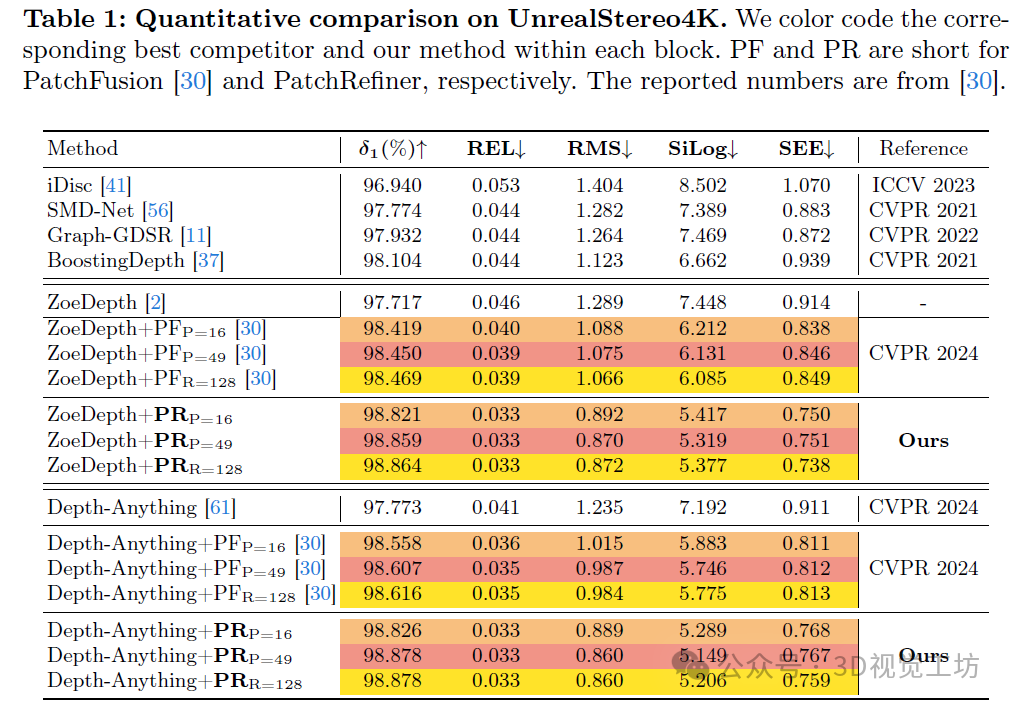
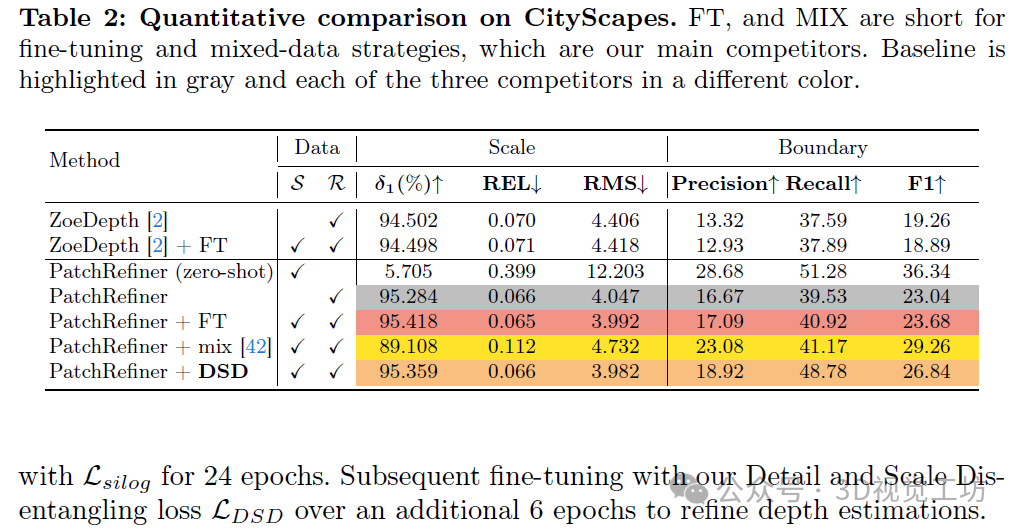
我们在Unreal4KStereo合成数据集上对PatchRefiner进行评估,结果显示与当前最先进的方法相比有显著的改进,RMSE降低了18.1%,REL降低了15.7%。此外,我们还评估了该框架在利用合成数据跨多个真实世界数据集(包括CityScape(室外,立体视觉),ScanNet++(室内,激光雷达和重建),以及ETH3D[49](混合,激光雷达))时的有效性。我们的发现表明,在保持准确尺度估计的同时,深度边界的界定得到了显著的增强(例如,在CityScape上边界召回率增加了19.2%),展示了该框架在不同设置和传感器技术中的适应性和有效性。
下面一起来阅读一下这项工作~
1. 论文信息
标题:PatchRefiner: Leveraging Synthetic Data for Real-Domain High-Resolution Monocular Metric Depth Estimation
作者:Zhenyu Li, Shariq Farooq Bhat, Peter Wonka
机构:KAUST
原文链接:https://arxiv.org/abs/2406.06679
代码链接:https://github.com/zhyever/PatchRefiner
2. 摘要
本文介绍了PatchRefiner,这是一种先进的度量单图像深度估计框架,旨在处理高分辨率的真实域输入。虽然深度估计对于自动驾驶、3D生成建模和3D重建等应用至关重要,但由于现有架构的限制和详细真实世界深度数据的稀缺性,在现实世界场景中实现准确的高分辨率深度估计具有挑战性。PatchRefiner采用基于瓦片的方法论,将高分辨率深度估计重新概念化为一个细化过程,从而显著提高了性能。PatchRefiner利用合成数据的伪标签策略,结合细节和尺度解耦(DSD)损失,以在保持尺度准确性的同时增强细节捕获,从而促进了从合成数据到真实世界数据的有效知识迁移。我们的广泛评估展示了PatchRefiner的卓越性能,在Unreal4KStereo数据集上,其均方根误差(RMSE)相比现有基准显著提高了18.1%,并在CityScape、ScanNet++和ETH3D等多样化的真实世界数据集上显示出细节准确性和一致尺度估计的显著改进。
3. 效果展示
在UnrealStereo4K数据集上,PatchRefiner不仅超越了基础深度模型,而且在与PatchFusion的对比中显示出显著的改进,将RMSE降低了18.1%,REL降低了15.7%。这一进步通过实现最低的SEE进一步得到强调,突显了我们的模型在捕获边缘细节方面的能力。如图5所示的定性比较表明,PatchRefiner在边界描绘方面取得了卓越的性能。

图6、7描述了利用合成数据进行真实域学习时的性能差异。虽然基于合成数据训练的模型在边界细节上表现出色,但由于域间差异,它在尺度准确性上表现不佳。仅使用真实域数据进行训练可以提高基线的尺度预测能力,但由于边界周围缺少深度真实值,细节准确性不足。无论是微调还是混合训练都没有在尺度和细节指标上显著提高性能,这反映了我们任务中固有的挑战。相比之下,我们的策略在保持与基线模型相当的尺度精度的同时,使模型在边界准确性方面取得了显著的提升(边界召回率提高了19.2%)。


4. 基本原理是啥?
框架比较。(a) 单次前向传递的低分辨率深度估计框架。(b) 基于融合的高分辨率框架,结合了粗粒度和细粒度深度预测的最佳结果。(c) 我们的基于细化器的框架预测残差以细化粗粒度预测。
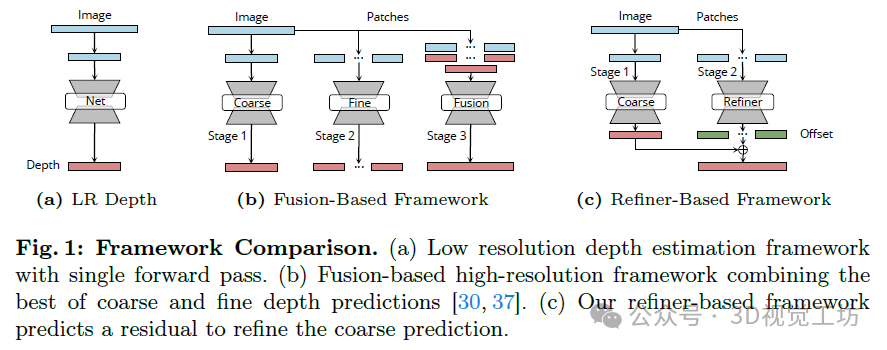
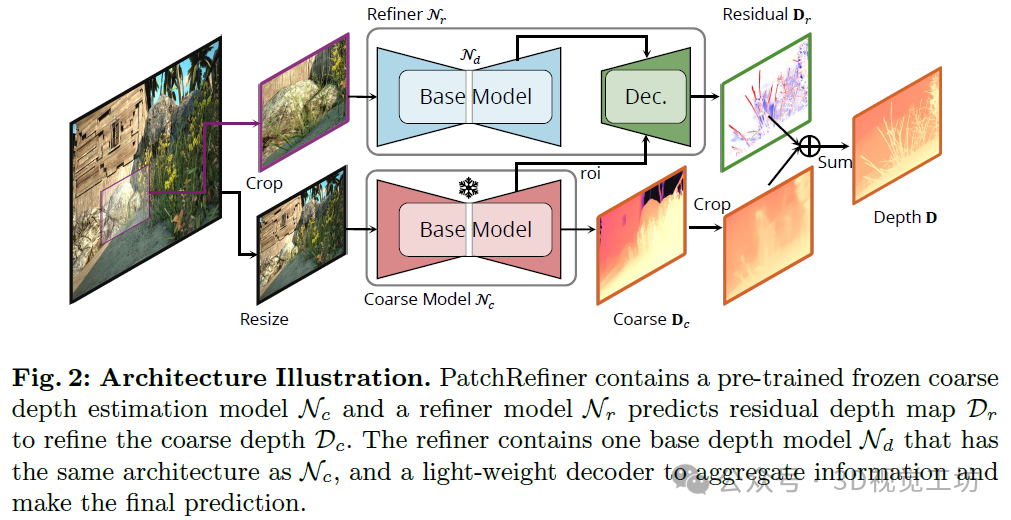
PatchRefiner采用基于瓦片(tile-based)的策略来应对4K等高分辨率带来的巨大内存和计算需求。然而,认识到现有模型的局限性,我们提出了一种简化的两步高分辨率深度估计方法:(i) 粗粒度尺度感知估计,(ii) 细粒度深度细化,如图2所示。
(i) 粗粒度尺度感知估计:PatchRefiner的基础是粗深度估计网络Nc,它处理输入图像的降采样版本来生成全局深度预测Dc。与先前的工作类似,这一步对于建立捕获场景整体结构和深度一致性的基线深度图至关重要,尽管没有高分辨率的细节。此外,Nc可以是任意深度估计模型,并在训练的第一步之后冻结。
(ii) 深度细化过程:不同于传统方法使用单独的精细深度网络和融合机制,我们的框架引入了一个统一的细化网络Nr。该网络旨在通过关注丢失细节的恢复和基于瓦片的深度精度增强来细化粗深度图。
本文的第二个目标是使用合成数据集S和真实领域数据集R来训练一个真实领域的高分辨率深度估计模型。
我们的主要见解是区分尺度误差和边界误差。在高分辨率深度估计领域,当前最先进的方法论使用合成数据集来训练模型,这提供了配对的高分辨率图像以及对应的密集高分辨率深度真值图。这种合成训练方式虽然在受控环境中是有益的,但当模型应用于真实世界数据时,由于合成环境和真实世界环境之间的内在领域差异,会引入重大挑战。这种差异通常在真实领域数据集上的推理过程中表现为显著的尺度误差。
直接在真实领域数据集上进行训练以解决这个问题会带来其自身的一系列挑战。真实世界的高分辨率深度数据集非常稀缺,通常受限于有限的分辨率和无法获得的缺失真值像素。这些限制源于生成真实世界深度标注所使用的方法,如Kinect、LiDAR或双目视觉技术,每种方法都有其固有的缺点,如图3所示。

例如,使用Kinect技术生成的深度图受限于640×480的分辨率,对于高分辨率深度估计而言是不足够的。虽然基于LiDAR的深度图很有用,但它们往往很稀疏或在分辨率上有限(例如,在Scannet++中为256x192),并且从LiDAR点云重建高分辨率密集深度图的过程存在级联错误和遗漏,非常脆弱。另一方面,立体视觉技术也可能因为校正变换而在物体边界周围引入缺失值。重要的是要认识到,现有边缘周围有缺失值的高分辨率真实数据集并不能帮助减少边界错误。
这些限制凸显了使用现实世界数据集训练高分辨率深度估计器时固有的困难。在真实世界中缺乏高质量、高分辨率的真实深度图,使得训练能够准确预测精细物体边界周围尖锐深度的模型变得具有挑战性。我们的主要想法是设计一种训练策略,当在真实数据上进行微调时,可以改进尺度误差,同时保持边缘周围的高分辨率信息以最小化边界错误。
基于深度估计任务中半监督学习框架的成功经验,我们提出的框架采用了教师-学生架构,如图4所示,有效地整合了合成数据和真实领域数据以进行高分辨率深度估计。
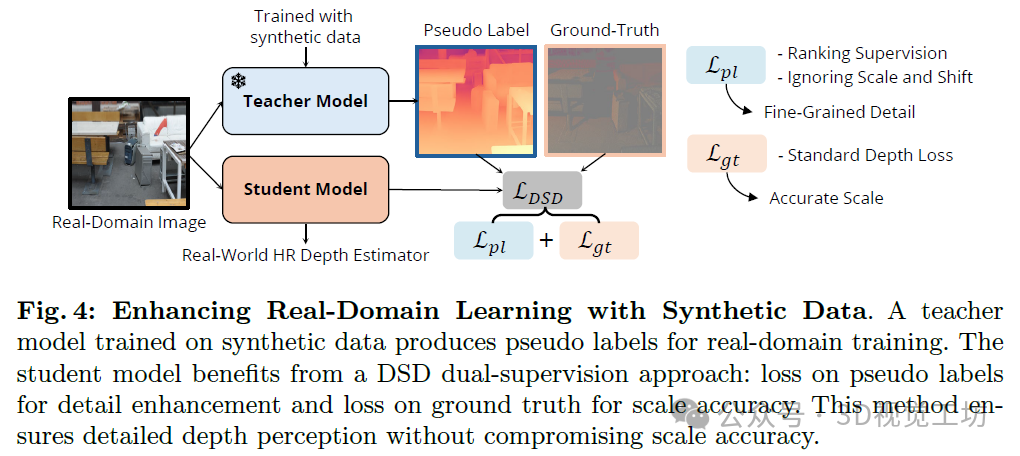
它采用两步过程:
教师模型训练:教师模型首先在合成数据集S上进行预训练。由于合成数据集的高质量和详细的标注,该模型能够预测具有精确边界的高分辨率深度图。
学生模型训练(带有伪标签和真实深度标签):在后续阶段,教师模型被冻结,而学生模型在真实领域数据集R上进行训练,同时利用真实深度标签D~和教师模型生成的伪标签D^。如真实领域数据集的局限性所述,虽然真实深度标签提供了准确的深度信息,但它们缺失了对于高分辨率深度学习至关重要的边界附近的关键信息。为了解决这个问题,学生模型在教师生成的伪标签的指导下进行训练,这些伪标签在边界附近表现优秀。然而,由于合成数据和真实世界数据之间的领域差异,这些伪标签虽然清晰,但存在尺度差异。
5. 实验结果
深度估计的定量指标:
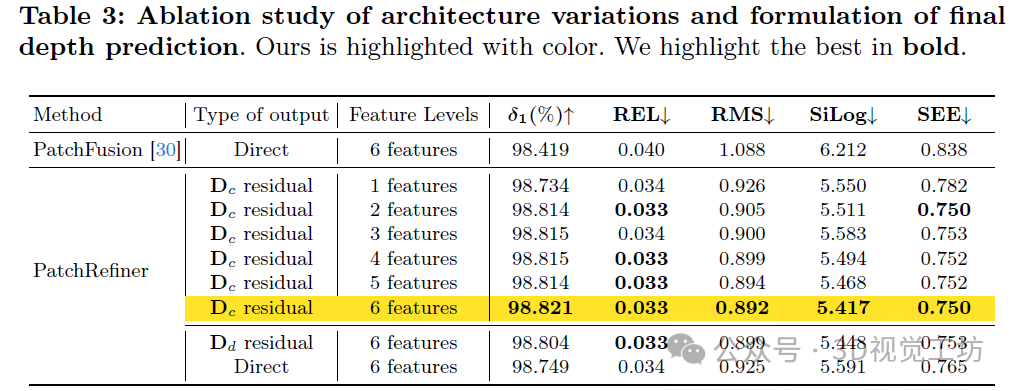
架构和公式变化:我们首先验证了我们的架构设计有效性。利用ZoeDepth模型,我们在前向传播过程中提取了六个级别的中间特征,表示为F = f1,f2,...,f6,其分辨率逐渐提高。然后,我们依次从细化器的解码器输入中省略较低分辨率的特征图。如表3所示,随着特征图的减少,性能会下降,但即使仅使用最高分辨率的特征图,我们的模型性能也优于PatchFusion。
此外,我们通过将其与两种替代方案进行比较来探索我们细化公式的有效性:(1)在细化器内基于基础模型Nd进行残差深度调整。(2)与PatchFusion类似,直接从细化器的解码器进行深度预测(在这种情况下,D = Dr)。我们的基于残差的方法展示了卓越的性能,凸显了其在优化和训练效率方面的优势。
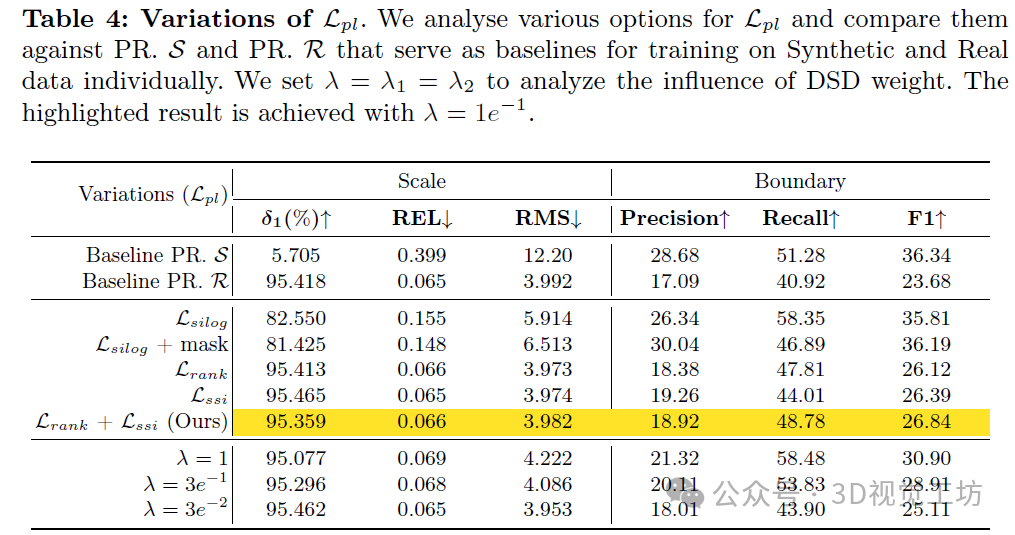
伪标签监督的有效性:我们评估了我们的细节和尺度解耦(DSD)损失与传统尺度不变损失Lsilog在伪标签监督方面的有效性。表4表明,虽然Lsilog有助于将细节从教师模型转移到学生模型,但由于伪标签中的显著差异,它会损害尺度准确性。
仅关注缺乏深度区域的掩膜方法并不能缓解这个问题,这表明存在普遍的负面影响。相比之下,Lpl中的Lrank和Lssi组合不仅提高了细节保真度,而且还保持了尺度准确性,这表明排序约束和尺度偏移不变性是增强高分辨率细节而不牺牲尺度准确性的有效正交策略。
6. 总结
我们提出了PatchRefiner,一个针对现实世界高分辨率单目度量深度估计的基于瓦片(tile-based)的框架。它将高分辨率深度估计重新概念化为一个细化过程。通过利用合成数据的伪标签策略,我们提出了一个细节和尺度解耦(DSD)损失,以在保持尺度准确性的同时增强细节捕获。我们提出的框架在UnrealStereo4K数据集上显著超越了当前的SOTA方法(RMSE降低17.3%),同时在CityScape、ScanNet++和ETH3D等现实世界数据集上显著提高了细节准确性。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 低成本+体积小 +重量轻+抗高反 | YA001高精度3D相机 |
 | 抗高反+无惧黑色+半透明 | KW-D | 高精度3D结构光 开源相机 |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









