






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 这篇文章干了啥?
近几十年来,自动驾驶领域取得了突破性的成就。端到端范式,即寻求将感知、预测和规划任务整合到一个统一框架中的方法,已成为其中一个代表性的分支。端到端自动驾驶的最新进展极大地激发了研究人员的兴趣。然而,尽管先前在环境建模中证明其效用的手工设计和资源密集型的监督子任务(用于感知和预测)仍然不可或缺。
那么,我们从最近的进展中获得了哪些启示呢?我们注意到,其中一项最具启发性的创新是基于Transformer的管道,其中查询作为连接各种任务的纽带,无缝地连接它们。此外,环境建模的能力也由于监督子任务的复杂交互而显著提高。但凡事都有两面性。与原始设计相比,模块化方法不可避免地带来了计算和标注的开销。最近的UniAD方法的训练需要48个GPU日,并且仅能以每秒2.1帧(FPS)的速度运行。此外,现有的感知和预测设计模块需要大量的高质量标注数据。人类标注的财务开销极大地阻碍了具有监督子任务的模块化方法利用大量数据的可扩展性。正如大型基础模型所证明的,扩大数据量是将模型能力提升到下一个层次的关键。因此,我们自问:是否有可能设计一个高效且鲁棒的端到端自动驾驶框架,同时减轻对3D标注的依赖?
在这项工作中,我们通过提出一种创新的端到端自动驾驶(UAD)的无监督预训练任务,展示了答案是肯定的。该预训练任务旨在高效地模拟环境。该预训练任务包含一个角度感知模块,通过学习预测鸟瞰图(BEV)空间中每个扇区区域的目标性来学习空间信息,以及一个角度梦想解码器,通过预测无法访问的未来状态来吸收时间知识。引入的角度查询将这两个模块作为一个整体的预训练任务连接起来,以感知驾驶场景。值得注意的是,我们的方法完全消除了对感知和预测的标注需求。这种数据效率是当前的复杂监督模块化方法无法实现的。
学习空间目标性的监督是通过将一个现成的开放集检测器的2D感兴趣区域(ROIs)投影到BEV空间来获得的。虽然利用了在其他领域(如COCO)使用手动标注预训练的公开可用的2D检测器,但我们避免了在我们的范式和目标领域(如nuScenes和CARLA)中需要任何额外的3D标签,从而创建了一个实用的无监督设置。
此外,我们引入了一种自监督的方向感知学习策略来训练规划模型。具体来说,视觉观测被增强为不同的旋转角度,并将一致性损失应用于预测以实现稳健的规划。无需任何额外的花哨手段,所提出的UAD在nuScenes的平均L2误差上比UniAD低0.13米,在CARLA的路线完成分数上比VAD高出9.92分。这种前所未有的性能提升是在3.4倍的推理速度、UniAD的仅44.3%的训练预算和零标注的情况下实现的。
下面一起来阅读一下这项工作~
1. 论文信息
标题:End-to-End Autonomous Driving without Costly Modularization and 3D Manual Annotation
作者:Mingzhe Guo, Zhipeng Zhang, Yuan He, Ke Wang, Liping Jing
机构:北京交通大学、KargoBot
原文链接:https://arxiv.org/abs/2406.17680
代码链接:https://github.com/KargoBot_Research/UAD
2. 摘要
我们提出了UAD,一种基于视觉的端到端自动驾驶(E2EAD)方法,在nuScenes中取得了最佳的开环评估性能,同时在CARLA中展示了稳健的闭环驾驶质量。我们的动机源于观察到当前的E2EAD模型仍然模仿典型驾驶堆栈中的模块化架构,通过精心设计的监督感知和预测子任务为定向规划提供环境信息。尽管取得了突破性的进展,但这种设计仍存在一定的缺点:1)先前的子任务需要大量的高质量3D标注作为监督,给训练数据的扩展带来了重大阻碍;2)每个子模块在训练和推理中都涉及大量的计算开销。为此,我们提出了UAD,一个带有无监督代理的E2EAD框架,以解决所有这些问题。首先,我们设计了一种新颖的角度感知预训练任务,以消除标注要求。该预训练任务通过预测角度方向的空间目标性和时间动态来模拟驾驶场景,无需手动标注。其次,提出了一种自监督训练策略,该策略学习在不同增强视图下预测轨迹的一致性,以增强转向场景中的规划鲁棒性。我们的UAD在nuScenes中的平均碰撞率上相对于UniAD实现了38.7%的相对改进,并在CARLA的Town05 Long基准测试中在驾驶分数上超过了VAD 41.32分。此外,所提出的方法仅消耗UniAD的44.3%的训练资源,并在推理中快3.4倍。我们的创新设计不仅首次展示了相对于监督方法的无可争议的性能优势,而且在数据、训练和推理方面也具有前所未有的效率。代码和模型将在https://github.com/KargoBot_Research/UAD上发布。
3. 效果展示
(a) 端到端自动驾驶范式:1)原始架构,直接预测控制命令。2)模块化设计,结合各种前置任务。3)我们提出的框架,带有无监督的预训练任务。
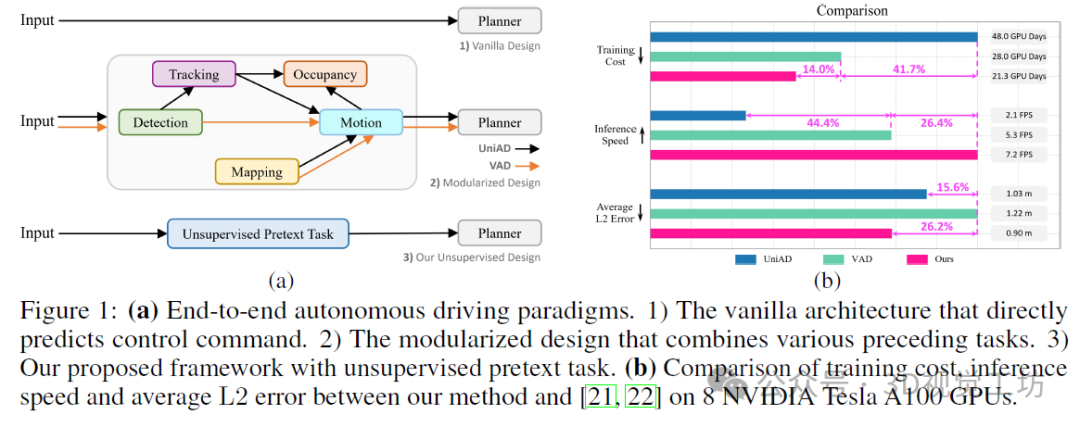
4. 主要贡献
总结来说,我们的贡献如下:1)我们提出了一种无监督的预训练任务,以消除端到端自动驾驶中对3D手动标注的需求,从而有可能在没有任何标注负担的情况下将训练数据扩展到数十亿级别;2)我们引入了一种新颖的自监督方向感知学习策略,以最大化不同增强视图下预测轨迹的一致性,这增强了转向场景中的规划鲁棒性;3)与其他基于视觉的E2EAD方法相比,我们的方法在开放和闭环评估中都显示出优越性,同时计算和标注成本大大降低。
5. 基本原理是啥?
如图2所示,我们的UAD框架由两个关键组件组成:1)角度感知预训练任务,旨在以无监督的方式将端到端自动驾驶(E2EAD)从昂贵的模块化任务中解放出来;2)方向感知规划,学习增强轨迹的自监督一致性。具体来说,UAD首先使用预训练任务对驾驶环境进行建模。通过估计鸟瞰图(BEV)空间内每个扇区区域的物体性来获取空间知识。引入负责每个扇区的角度查询来提取特征并预测物体性。监督标签是通过将2D感兴趣区域(ROIs)投影到BEV空间来生成的,这些ROIs是使用现有的开放集检测器GroundingDINO预测的。这种方式不仅消除了对3D标注的需求,还大大降低了训练成本。此外,由于驾驶本质上是一个动态和连续的过程,我们因此提出了一个角度方向的梦想解码器来编码时间知识。梦想解码器可以看作是一个增强的世界模型,能够自回归地预测未来状态。
随后,引入方向感知规划来训练规划模块。原始的BEV特征通过不同的旋转角度进行增强,产生旋转的BEV表示和自车轨迹。我们对每个增强视图的预测轨迹应用自监督一致性损失,这有望提高方向变化和输入噪声的鲁棒性。这种学习策略也可以被视为一种专为端到端自动驾驶定制的新型数据增强技术,增强了轨迹分布的多样性。
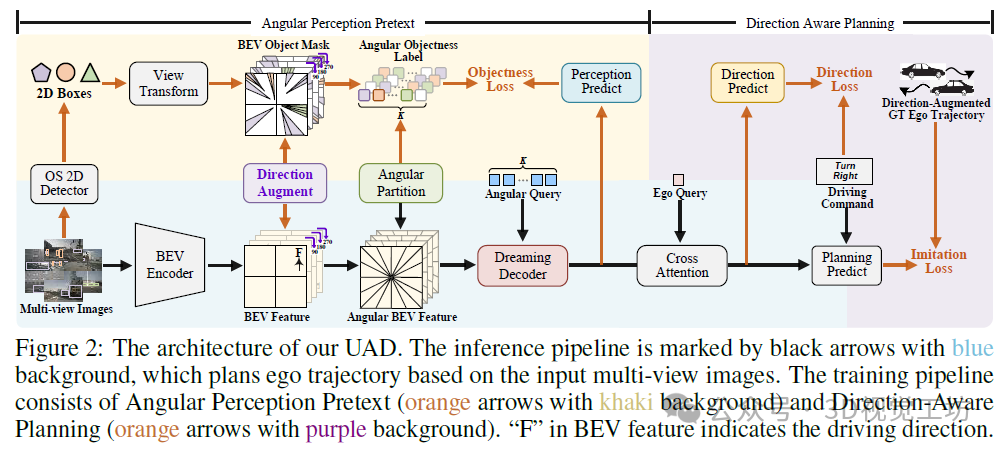
6. 实验结果
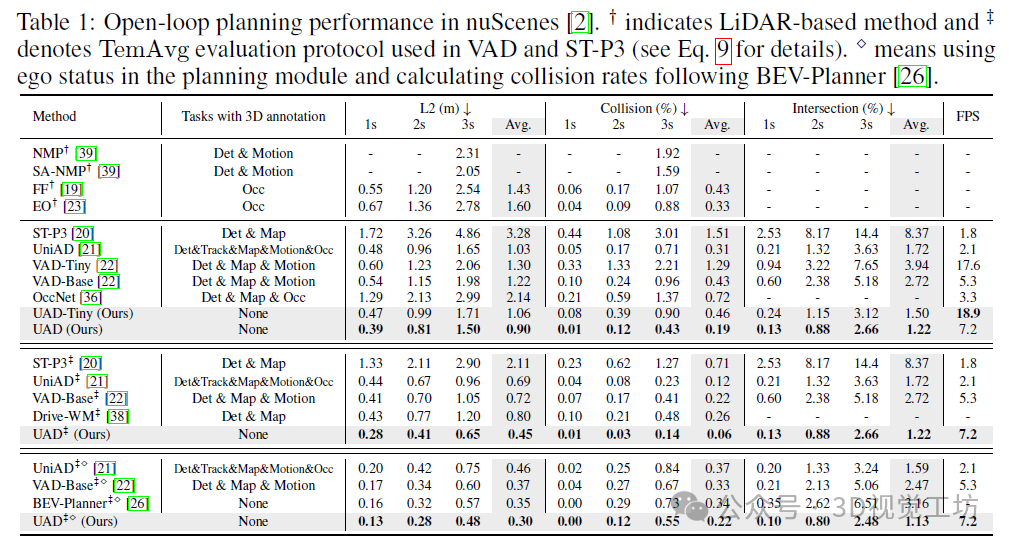
开放循环评估。表1展示了在L2误差、碰撞率、与道路边界的交叉率以及每秒帧数(FPS)方面的性能比较。由于ST-P3和VAD采用与UniAD不同的评估协议来计算L2误差和碰撞率,我们分别在不同的设置下(即NoAvg和TemAvg)计算了结果。如表1所示,提出的UAD在所有指标上都优于UniAD和VAD,同时运行速度更快。值得注意的是,在NoAvg评估协议下,与UniAD和VAD相比,UAD在Collision@3s上分别获得了39.4%和55.2%的相对改进(例如,39.4%=(0.71%-0.43%)/0.71%),这展示了我们的方法在长期内的鲁棒性。此外,UAD以7.2FPS的速度运行,分别是UniAD和VAD-Base的3.4倍和1.4倍快,验证了我们的框架的高效性。
令人惊讶的是,我们的轻量级版本UAD-Tiny,在主干网络、图像大小和BEV分辨率方面与VAD-Tiny保持一致,以最快的18.9FPS的速度运行,同时明显优于VAD-Tiny,甚至达到了与VAD-Base相当的性能。这再次证明了我们的设计的优越性。
除非另有说明,否则在以下消融实验中我们采用NoAvg评估协议。最近的工作讨论了在规划模块中使用自我状态的影响。遵循这一趋势,我们也公平地将配备自我状态的模型版本与这些工作进行了比较。结果表明,UAD的优越性仍然保持,并且与对比方法相比也取得了最佳性能。此外,BEV-Planner引入了一个新的名为“交互”的指标,以更好地评估E2EAD方法的性能。如表1所示,我们的模型获得了1.13%的平均交互率,明显优于其他方法。这再次证明了我们的UAD(无监督自动驾驶)方法的有效性。另一方面,这也说明了设计一个适合感知环境的预训练任务的重要性。仅仅使用自我状态信息对于安全驾驶是不够的。
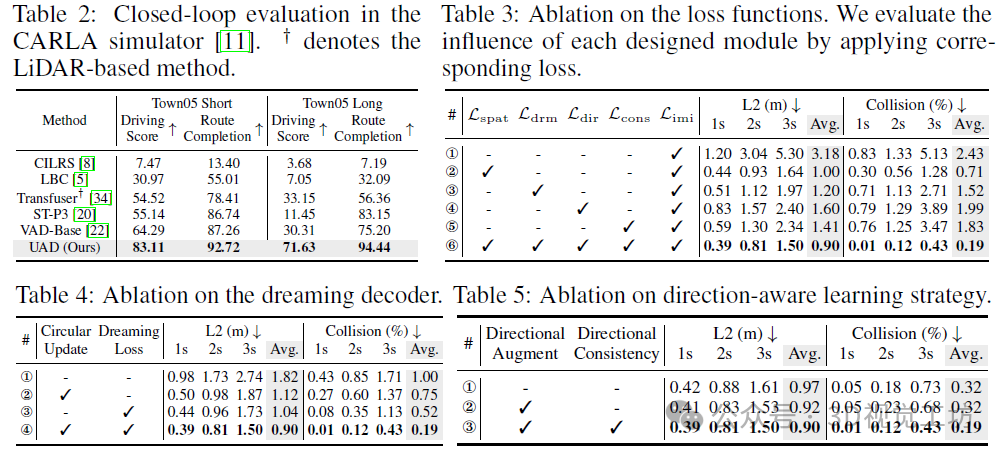
在闭环评估中,CARLA的仿真结果显示在表2中。我们的UAD在所有场景下都取得了比最近的端到端规划器ST-P3和VAD更好的性能,证明了其有效性。值得注意的是,在具有挑战性的Town05 Long基准测试中,UAD在驾驶得分上比最近的端到端方法VAD高出41.32分,在路线完成度上高出19.24分。这证明了我们的UAD在长期自动驾驶中的可靠性。
损失函数分析。我们首先分析了与所提出的预训练任务和自监督轨迹学习策略相对应的不同损失函数的影响。实验在nuScenes的验证集上进行,如表3所示。仅使用模仿损失Limi的模型被视为基线(①)。通过空间物体性损失Lspat增强的感知能力,平均L2误差和碰撞率分别从3.18m和2.43%显著提高到1.00m和0.71%(②与①相比)。梦想损失Ldrm、方向损失Ldir和一致性损失Lcons也分别给基线模型带来了平均L2误差上的显著增益,分别为1.98m、1.58m、1.77m(③、④、⑤与①相比)。最后,这些损失函数被组合起来构建我们的UAD(⑥),获得了平均L2误差为0.90m和平均碰撞率为0.19%的结果。这些结果证明了所提出的每个组件的有效性。
时间学习与梦想解码器。时间学习通过提出的梦想解码器实现,这主要依赖于循环更新和梦想损失。循环更新负责从观察到的场景中提取信息并生成伪观测值以预测未来帧的自车轨迹。我们在表4中研究了每个模块的影响。循环更新和梦想损失分别将平均L2误差降低了0.70m和0.78m(②,③与①相比),这证明了我们设计的有效性。同时应用这两个模块(④)达到了最佳性能,显示了它们在时间表示学习中的互补性。
方向感知学习策略。方向增强和方向一致性是提出的方向感知学习策略的两个核心组件。我们在表5中证明了它们的有效性。结果显示,方向增强将平均L2误差降低了显著的0.05m(②与①相比)。一个有趣的观察是,应用增强对于长期规划比短期规划带来了更多的收益,即与①相比,1s/3s的L2误差分别降低了0.01m/0.08m,这证明了我们的增强对于增强更长时间的信息是有效的。方向一致性进一步将平均碰撞率降低了令人印象深刻的0.13%(③与②相比),这增强了驾驶方向变化的鲁棒性。
7. 总结 & 未来工作
我们的工作旨在将端到端自动驾驶(E2EAD)从昂贵的模块化和3D手动标注中解放出来。为此,我们提出了一个无监督的预训练任务,通过预测角度方向的物体性和未来动态来感知环境。为了提高转向场景中的鲁棒性,我们引入了方向感知的训练策略用于规划。实验证明了我们的方法的有效性和效率。正如所讨论的,虽然自车轨迹可以很容易地获得,但收集数十亿级带有感知标签的精确标注数据几乎是不可能的。这阻碍了端到端自动驾驶的进一步发展。我们相信我们的工作为这一障碍提供了一个潜在的解决方案,并在大量数据可用时可能将性能提升到新的水平。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









