






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:dddvision,备注:方向+学校/公司+昵称,拉你入群。文末附行业细分群
扫描下方二维码,加入3D视觉知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门视频课程(星球成员免费学习)、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 这篇文章干了啥?
视频内容主要包含两大组成部分:动态场景和静态场景。在动态场景(也称为动态对象)中,对象会随时间展现出运动或变化,视频帧之间的运动是由摄像机运动和对象本身的运动共同产生的。相反,在静态场景中,对象保持不变,帧间运动仅受摄像机刚性运动的影响。与静态场景相比,动态场景在运动和外观上都更为复杂。
然而,近几年来在建立点对应方面的高级研究总是采用统一的框架来处理两个场景中的不同运动。例如,特征匹配方法试图为密集特征设计学习方法。尽管这些方法在涉及动态对象跟踪的任务中取得了良好的性能,但它们在建模静态场景中一致的运动方面却存在困难。密集光流估计方法将像素对应视为回归问题,通常会在渲染的视频数据集上训练卷积神经网络,并通过构建金字塔成本体积、迭代推理和多帧预测来进一步改进。然而,这些方法在现实世界视频中的鲁棒性仍不尽如人意,尤其是在动态对象上。
在最近的一项研究中,OmniMotion提出了一种新颖的测试时优化方法,该方法利用可靠的对应关系和RGB帧作为监督,来学习具有学习变换的全局一致神经辐射场。该表示在规范空间中存储完整的颜色和准3D几何信息,同时变换可以建立长距离像素轨迹,即使面对遮挡也能实现。尽管前景广阔,但该方法采用统一的神经场和变换进行优化,导致在估计运动物体的高度非刚性运动时性能次优。
在本工作中,为了学习准确的点对应关系,我们提出了一种解耦表示,该表示根据运动和外观将静态场景和动态对象分开。利用它们之间的显著差异,我们分别为它们构建独立的3D神经辐射场进行表示,并仔细设计了每个场景的变换和表示函数。更具体地说,对于动态对象,考虑到帧间运动的复杂性和外观的剧烈变化,我们利用更多的非线性层来近似非刚性运动。此外,我们还对场中的特征进行编码以获得更好的表示,并添加一个特征渲染约束来缓解动态对象上对应不精确的问题。对于静态场景,我们通过具有仿射变换的更简单网络来处理刚性运动,并建模3D点是否变化或移动的置信度。利用这种置信度,我们进一步融合两个神经辐射场和变换,以获得最终的外观和运动表示。这种设计使DecoMotion能够更准确地建立整个视频中任何像素的轨迹,特别是在动态对象上。
下面一起来阅读一下这项工作~
1. 论文信息
标题:Decomposition Betters Tracking Everything Everywhere
作者:Rui Li, Dong Liu
机构:中国科学技术大学
原文链接:https://arxiv.org/abs/2407.06531
代码链接:https://github.com/qianduoduolr/DecoMotion
2. 摘要
最近关于运动估计的研究提倡一种在整个视频中全局一致、最好是针对每个像素的优化运动表示。这是一个挑战,因为统一的表示可能无法解释自然视频的复杂和多样的运动和外观。我们针对这一问题,提出了一种新的测试时优化方法,名为DecoMotion,用于估计每个像素和长距离的运动。DecoMotion明确地将视频内容分解为静态场景和动态对象,两者都使用准3D规范体积来表示。DecoMotion分别协调局部空间和规范空间之间的变换,便于静态场景对应的相机运动进行仿射变换。对于动态体积,DecoMotion利用具有判别性和时间一致性的特征来校正非刚性变换。最后,将这两个体积融合以充分表示运动和外观。这种分而治之的策略通过遮挡和变形实现了更稳健的跟踪,同时获得了分解的外观。我们在TAP-Vid基准上进行了评估。结果表明,我们的方法大大提高了点跟踪的准确性,并且与一些最先进的专用点跟踪解决方案相当。
3. 效果展示
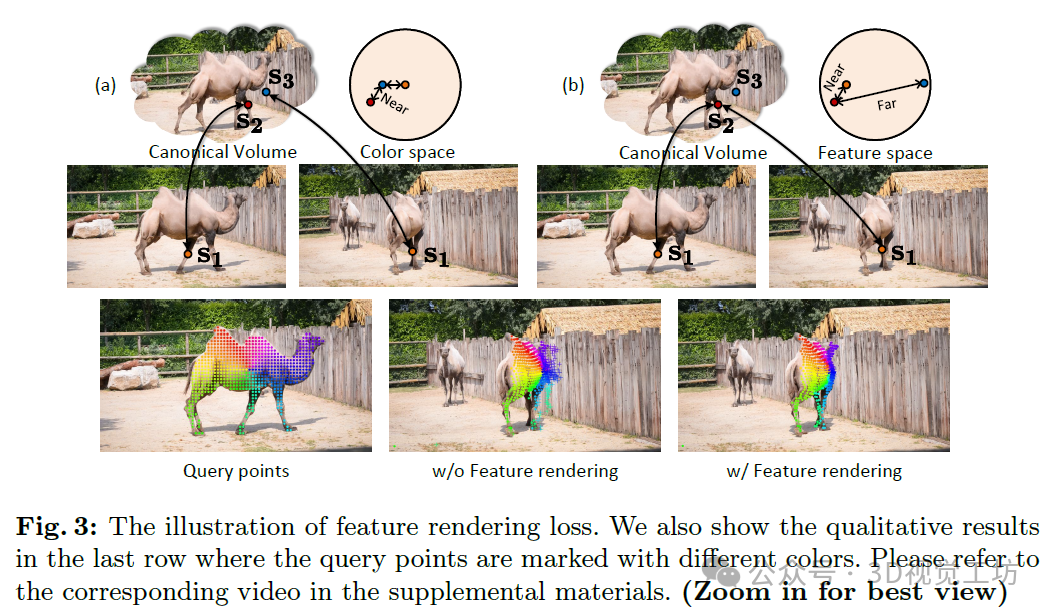
解耦静态场景和动态对象的渲染结果。

如图3最后一行所示,给定的查询点被背景中的干扰物误导。通过使用特征渲染损失,查询点能够准确匹配到另一帧中的对象,即使面对大变形,这也证明了表示和渲染特征的有效性。然而,在静态场景上进行特征渲染帮助不大。我们认为这是由于预训练特征的表示能力相对较差以及背景中帧间变化较小所致。
我们选择了几个具有代表性的视频进行推理,并给出了可视化结果。DecoMotion在视频帧上产生了更准确、更稳定的像素对应关系。例如,在图6的左侧案例中,跳舞的女孩呈现出非常复杂的大变形运动,基线方法要么丢失跟踪,要么得到不精确的结果,而DecoMotion能够持续准确地跟踪点,这验证了DecoMotion在处理动态对象运动方面的卓越能力。

4. 主要贡献
总结而言,本工作的主要贡献在于:
(i) 我们提出了一种优化的3D视频表示方法,该方法将视频分解为动态对象和静态场景,以便更好地追踪每个像素;
(ii) 对于动态对象,我们提出编码和渲染具有判别性和时间一致性的特征,以纠正非刚性变换;
(iii) 我们在TAP-Vid基准数据集上对我们的方法进行了定量验证。我们的方法显著提高了点追踪的准确度,并展示了具有竞争力的性能。
5. 基本原理是啥?
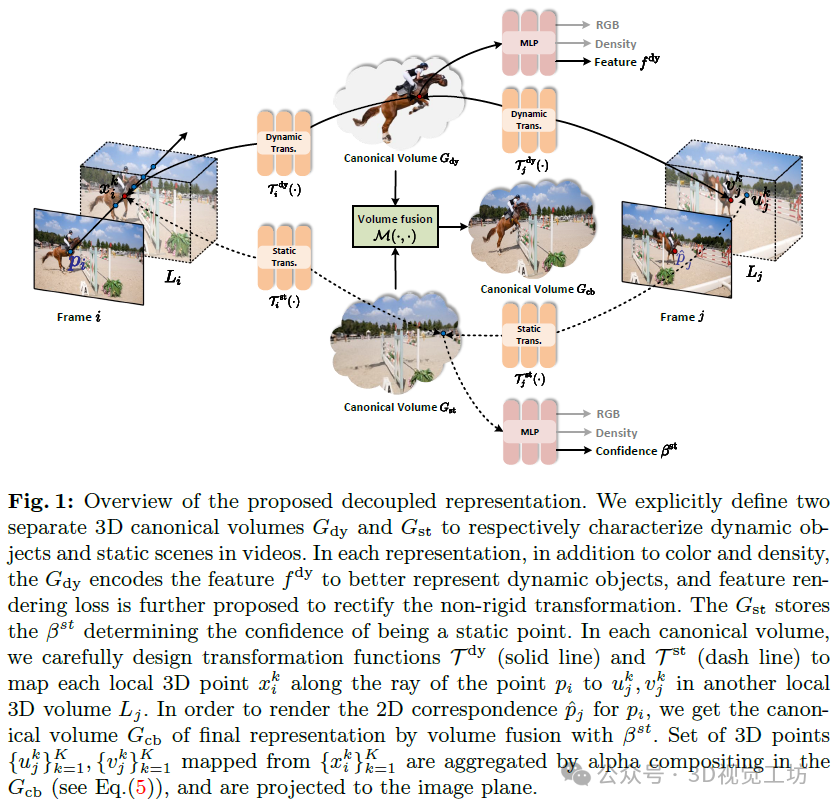
所提出解耦表示的概述。我们明确定义了两个独立的3D规范体积Gdy和Gst,分别用于表征视频中的动态对象和静态场景。在每个表示中,除了颜色和密度外,Gdy还编码了特征fdy以更好地表示动态对象,并进一步提出了特征渲染损失以校正非刚性变换。Gst存储了βst,它决定了某个点是否为静态点的置信度。在每个规范体积中,我们精心设计了变换函数Tdy(实线)和Tst(虚线),以将沿点pi射线的每个局部3D点xki映射到另一个局部3D体积Lj中的ukj和vkj。为了渲染pi的2D对应点ˆpj,我们通过使用βst进行体积融合得到最终表示的规范体积Gcb。将从{xki}Kk=1映射得到的{ukj}Kk=1和{vkj}Kk=1两组3D点,在Gcb中通过alpha合成进行聚合,并投影到图像平面上。
6. 实验结果
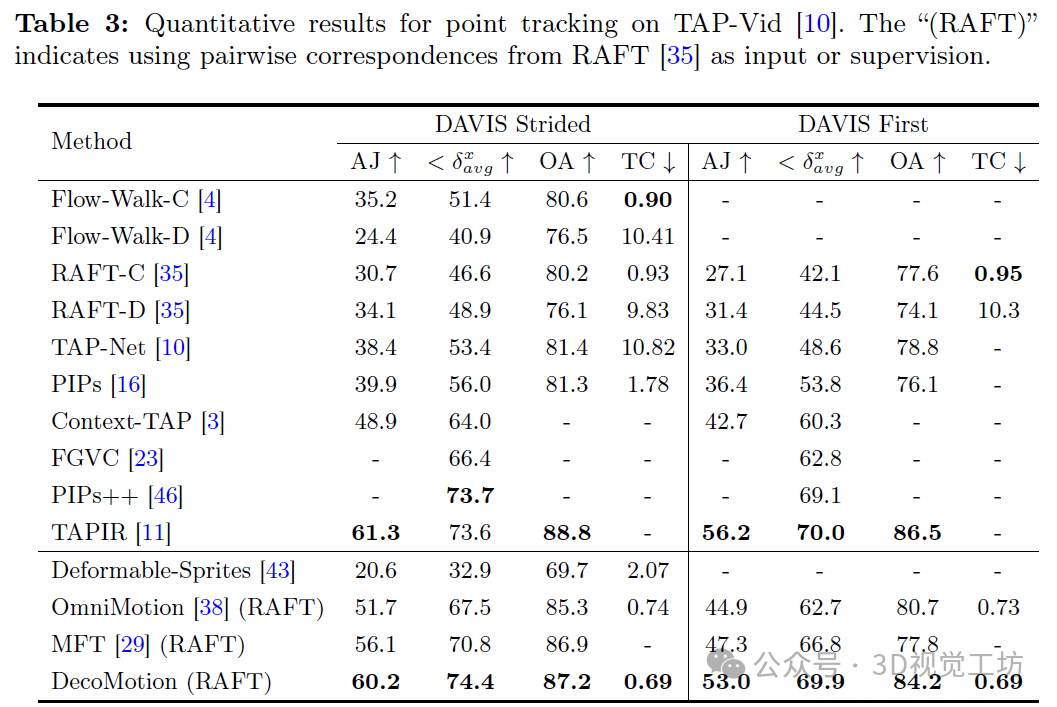
我们将所提出的方法与最新的点跟踪方法进行了比较。定量结果如表3所示。除了基于优化的方法Deformable-Sprites和OmniMotion外,我们还加入了利用RAFT输入点对对应关系的MFT作为我们的竞争对手。与最直接的竞争对手OmniMotion相比,DecoMotion在DAVIS-Strided和DAVIS-First上的跟踪位置精度<δx_avg分别领先6.9%/7.2%。同时,DecoMotion也优于Deformable-Sprites和MFT,比MFT高出3.6%/3.1%。我们还包括了一些通过估计多帧点轨迹来跟踪遮挡的专用点跟踪方法进行比较。需要注意的是,DecoMotion仅由RAFT进行监督,而RAFT在提供精确点对应关系方面的能力有限,但DecoMotion仍然表现出相当的性能,在DAVIS-Strided上领先0.7%的跟踪位置精度。
7. 限制性 & 总结
尽管取得了显著进步,但DecoMotion仍然高度依赖预计算的光流。然而,最近的成对光流方法在建模快速和大范围运动时存在困难,在某些情况下无法提供可靠且密集的对应关系。使用先进的多帧运动估计器可能缓解这一问题。此外,我们观察到如果视频中存在场景切换,训练可能会失败或陷入局部最小值。此外,我们还观察到,对于包含多个物体的更具挑战性的场景,DecoMotion的改进较小,这值得进一步研究。
在本工作中,我们介绍了一种创新的测试时优化方法,用于建立准确的像素对应关系。我们分别为静态场景和动态对象建立了3D表示。对于动态对象,我们通过添加更多非线性层和特征渲染损失来解决其复杂模式问题。对于静态场景,我们使用更简单的网络来处理刚性运动,同时建模3D点是静态还是非静态的置信度。然后,我们将这两个规范体积融合在一起,以更好地表示运动和外观。点跟踪的定量结果和外观分解的定性结果验证了所提出的方法。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊交流群
目前我们已经建立了3D视觉方向多个社群,包括2D计算机视觉、大模型、工业3D视觉、SLAM、自动驾驶、三维重建、无人机等方向,细分群包括:
2D计算机视觉:图像分类/分割、目标/检测、医学影像、GAN、OCR、2D缺陷检测、遥感测绘、超分辨率、人脸检测、行为识别、模型量化剪枝、迁移学习、人体姿态估计等
大模型:NLP、CV、ASR、生成对抗大模型、强化学习大模型、对话大模型等
工业3D视觉:相机标定、立体匹配、三维点云、结构光、机械臂抓取、缺陷检测、6D位姿估计、相位偏折术、Halcon、摄影测量、阵列相机、光度立体视觉等。
SLAM:视觉SLAM、激光SLAM、语义SLAM、滤波算法、多传感器融合、多传感器标定、动态SLAM、MOT SLAM、NeRF SLAM、机器人导航等。
自动驾驶:深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器、多传感器标定、多传感器融合、自动驾驶综合群等、3D目标检测、路径规划、轨迹预测、3D点云分割、模型部署、车道线检测、Occupancy、目标跟踪等。
三维重建:3DGS、NeRF、多视图几何、OpenMVS、MVSNet、colmap、纹理贴图等
无人机:四旋翼建模、无人机飞控等
除了这些,还有求职、硬件选型、视觉产品落地、最新论文、3D视觉最新产品、3D视觉行业新闻等交流群
添加小助理: dddvision,备注:研究方向+学校/公司+昵称(如3D点云+清华+小草莓), 拉你入群。

3D视觉工坊知识星球
3D视觉从入门到精通知识星球、国内成立最早、6000+成员交流学习。包括:星球视频课程近20门(价值超6000)、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步。

3DGS、NeRF、结构光、相位偏折术、机械臂抓取、点云实战、Open3D、缺陷检测、BEV感知、Occupancy、Transformer、模型部署、3D目标检测、深度估计、多传感器标定、规划与控制、无人机仿真、三维视觉C++、三维视觉python、dToF、相机标定、ROS2、机器人控制规划、LeGo-LAOM、多模态融合SLAM、LOAM-SLAM、室内室外SLAM、VINS-Fusion、ORB-SLAM3、MVSNet三维重建、colmap、线面结构光、硬件结构光扫描仪,无人机等。

3D视觉相关硬件
| 图片 | 说明 | 名称 |
|---|---|---|
 | 硬件+源码+视频教程 | 精迅V1(科研级))单目/双目3D结构光扫描仪 |
 | 硬件+源码+视频教程 | 深迅V13D线结构光三维扫描仪 |
 | 硬件+源码+视频教程 | 御风250无人机(基于PX4) |
 | 低成本+体积小 +重量轻+抗高反 | YA001高精度3D相机 |
 | 抗高反+无惧黑色+半透明 | KW-D | 高精度3D结构光 开源相机 |
 | 硬件+源码 | 工坊智能ROS小车 |
 | 配套标定源码 | 高精度标定板(玻璃or大理石) |
| 添加微信:cv3d007或者QYong2014 咨询更多 | ||
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









