






点击下方卡片,关注「3D视觉工坊」公众号
选择星标,干货第一时间送达
来源:3D视觉工坊
添加小助理:cv3d001,备注:方向+单位+昵称,拉你入群。文末附行业细分群。
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),星球内汇总了众多3D视觉实战问题,以及各个模块的学习资料,包括20+门独家视频课程、100+场顶会直播讲解、最新顶会论文分享、计算机视觉书籍、优质3D视觉算法源码、3D视觉入门环境配置教程、求职招聘等。想要入门3D视觉、做项目、搞科研,欢迎扫码加入!

0. 论文信息
标题:ERUPT: Efficient Rendering with Unposed Patch Transformer
作者:Maxim V. Shugaev, Vincent Chen, Maxim Karrenbach, Kyle Ashley, Bridget Kennedy, Naresh P. Cuntoor
机构:BlueHalo、Carnegie Mellon University
原文链接:https://arxiv.org/abs/2503.24374
1. 导读
这项工作解决了从RGB图像的小集合的不同场景中的新颖视图合成的问题。我们提出了一个最新的场景重建模型,能够使用未定位的图像进行高效的场景渲染。与现有的基于像素的查询相比,我们引入了基于补丁的查询,以减少渲染目标视图所需的计算。这使得我们的模型在训练和推理过程中都非常高效,能够在商用硬件上以600 fps的速度进行渲染。值得注意的是,我们的模型被设计为使用学习的潜在相机姿态,这允许使用具有稀疏或不准确地面真实相机姿态的数据集中的未定位目标进行训练。我们表明,我们的方法可以在大型真实世界数据上进行推广,并引入一个新的基准数据集(MSVS-1M),用于使用从mapi pile收集的街景图像进行潜在视图合成。与需要密集影像和精确元数据的NeRF和Gaussian Splatting相反,input可以使用少至五幅未发布的输入图像渲染任意场景的新颖视图。对于未发布的图像合成任务,ERUPT实现了比当前最先进的方法更好的渲染图像质量,将标记数据需求减少了约95 %,并将计算需求减少了一个数量级,为多样化的真实世界场景提供了高效的新视图合成。
2. 效果展示
MSN-1M的渲染结果:

MSN数据集的定性结果:

3. 引言
从少量图像中恢复三维场景表示是计算机视觉领域的基础挑战,在导航、机器人和增强现实等领域具有广泛应用。近期在隐式(如NeRF)和显式(如高斯溅射)场景表示学习方面的进展,展示了在复杂环境中渲染高保真新视图的卓越能力。这些模型通常依赖带有精确相机位姿的密集图像来重建高精度模型,从而实现场景的新视图渲染。然而,NeRF和高斯溅射框架的核心问题在于,每个场景都需要训练新网络或一组高斯函数。这需要大量训练时间,并限制了在输入视图有限或相机位移较大等情况下融入先验知识的能力。
已有多项方法通过引入深度、法线、语义等先验,利用外部数据信息进行特定场景学习,以减轻这种场景依赖性。但这些框架仍存在固有局限:若未针对每个新场景训练足够数量的输入视图及相关相机信息,则无法执行新视图合成。
最近的研究探索了使用潜在场景表示变换器(SRT)和可学习位姿估计器(RUST)的有限图像广义三维重建技术,以减少对精确相机位姿的依赖。通过在大型多样数据集上训练,这些模型学会了使用更少图像和有限相机位姿信息进行任意场景重建。推荐课程:卡尔曼滤波及其在多传感器融合的应用[PX4 EKF2讲解]。
虽然SRT允许使用任意相机位姿直接查询图像,但其缺乏从无位姿目标视图学习的机制,这使其在真实相机位姿含噪或未知的数据集上难以应用。RUST通过可学习位姿估计器解决了这一限制,但需要目标图像的部分信息来查询模型,这限制了推理时的相机控制。两种方法在训练和推理时均需对每个渲染图像的像素进行独立查询解码,导致显著的计算开销。此外,现有足够规模的基准数据集或为合成数据(如MSN),或为非公开的专有数据集,这使得这些技术的验证和实际应用变得困难。
针对这些局限,我们提出ERUPT——一种在计算上高效的新视图合成方法,支持在带位姿和无位姿目标图像上训练,并在推理时提供直接相机控制。我们的模型通过联合采样可学习潜在相机位姿与稀疏真实位姿,解决了目标相机位姿稀疏或不准确的问题。我们引入基于图像块的射线解码策略,替代传统像素级射线,使渲染计算效率相比现有模型提升了一个数量级。为加速收敛,我们在训练时复用场景表示生成多目标,并采用预训练特征提取器进行迁移学习。我们在MSN基准数据集上将模型与现有方法对比,即使与完全依赖带位姿目标图像的方法相比,也达到了最先进(SOTA)性能。此外,我们发布了新的真实世界视图合成数据集MSVS-1M(Mapillary街景合成1百万数据集),以便未来研究开展真实场景下的直接性能对比。
4. 主要贡献
我们的贡献总结如下:
基于潜在表示的新视图合成高效网络架构与训练方案。支持在带位姿和无位姿目标图像上训练,推理时提供直接相机控制。实验表明,即使仅使用5%的带位姿目标数据进行训练,性能下降也微乎其微。
解码器中的像素级射线替代方案。引入基于图像块的射线,使渲染和训练时间以及显存需求均降低一个数量级。具体而言,224×224图像的合成速率超过600帧/秒。
适用于未知输入位姿的图像合成优化架构。在MSN数据集上,针对未知输入位姿的图像合成任务,建立了新的PSNR和SSIM指标SOTA。
对抗学习与扩散渲染的探索。以ERUPT为基础,研究对抗学习和基于扩散的渲染在潜在新视图合成中的应用。两种方法均显著提升了输出感知质量,并在MSN数据集上超越了先前的感知指标SOTA。
真实世界多场景视图合成新基准。发布了从Mapillary图像库构建的MSVS-1M数据集,以促进大规模真实场景广义视图合成实验。
5. 方法
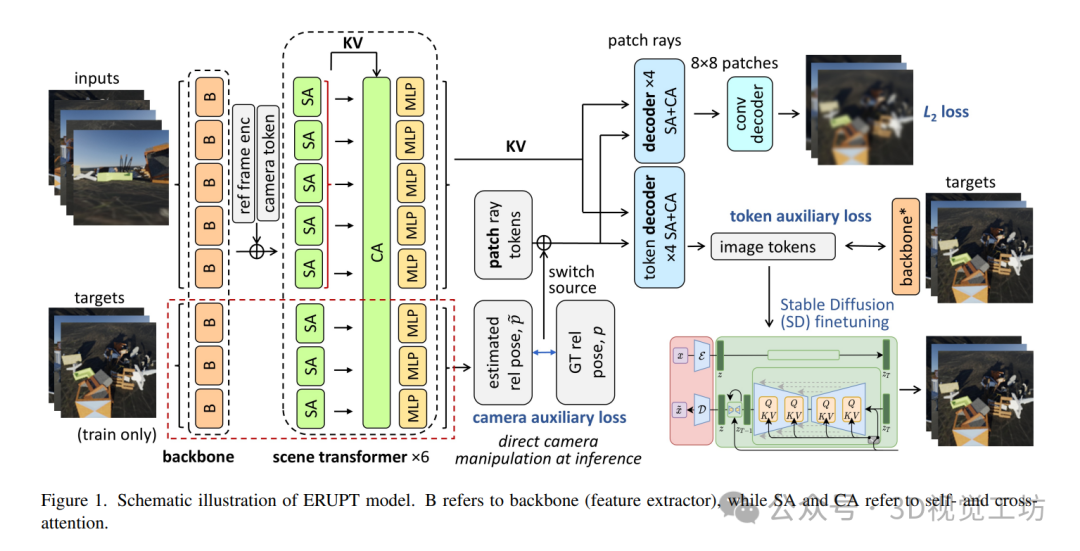
图1示意性地展示了本研究提出的ERUPT模型。输入场景由一组无序(无位姿)视图组成,首先通过基于变换器的特征提取器处理。将参考帧编码与位置编码添加到图像特征集合中,并将生成的令牌序列扩展为可学习相机令牌。随后,令牌序列通过场景变换器处理,该变换器旨在生成紧凑的场景和相机表示。该变换器交替执行图像内部和整个场景图像间的令牌混合,为每个图像生成场景表示和相机位姿估计(相对于参考帧)。最终的场景表示被查询用于图像解码器和令牌解码器中的每个图像块射线。
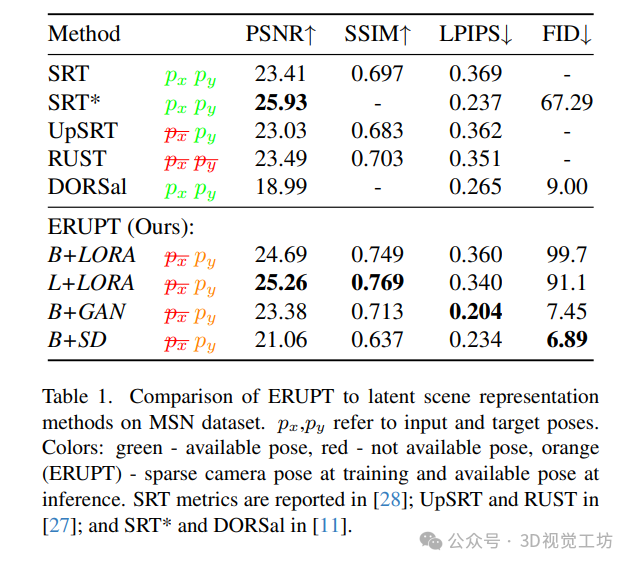
6. 实验结果
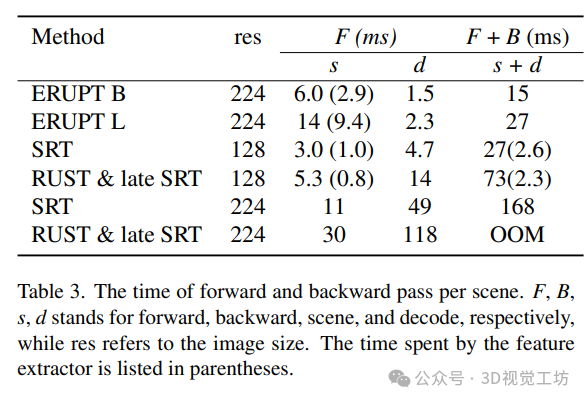
7. 总结 & 未来工作
我们提出了ERUPT,一个潜视图合成模型,用于在高度无约束的环境中进行高效的无位置场景表示学习。我们的新姿态估计策略和基于补丁的编码器-解码器变换器结构学会了在姿态和未姿态图像上进行训练,以高效地呈现新视图我们展示了一种有效的全可控视图合成方法通过指定相对于输入图像的凸轮位置,可以直接查询目标图像。我们的方法实现了一个数量级的计算效率的改善,同时提供国家的最先进的精度,在基准数据集呈现新颖的观点。此外,我们引入了一个大规模、真实世界场景重建数据集,包含来自32k序列的100万张图像。我们预计,我们创新和计算效率高的方法以及开放的基准数据集将在大规模港在场景重建方面取得重大进展。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。


3D硬件专区

「3D视觉从入门到精通」知识星球
扫描下方二维码,加入「3D视觉从入门到精通」知识星球(点开有惊喜),已沉淀7年,星球内资料包括:3D视觉系列视频近20+门、100+场直播顶会讲解、项目对接、3D视觉学习路线总结、最新顶会论文&代码、3D视觉行业最新模组、3D视觉优质源码汇总、书籍推荐、编程基础&学习工具、实战项目&作业、求职招聘&面经&面试题等。欢迎加入3D视觉从入门到精通知识星球,一起学习进步!

3D视觉全栈学习课程:www.3dcver.com

3D视觉交流群

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
3D视觉科技前沿进展日日相见 ~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









