






82. 删除排序链表中的重复元素 II
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
示例 1:
输入: 1->2->3->3->4->4->5
输出: 1->2->5
示例 2:
输入: 1->1->1->2->3
输出: 2->3
思路:
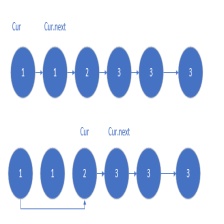
我们要把当前为某个值的前一结点preNode记录下来,和后面值比当前结点的值大的结点相连,详细思路写在了代码对应的位置更容易看懂。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode deleteDuplicates(ListNode head) {
/*由于头结点也可能是重复的会被删除,所以建立虚拟结点dummy,使得操作统一
我们要把当前为某个值的前一结点preNode记录下来,和后面值比当前结点的值大的结点相连*/
if(head == null || head.next == null) return head;
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode preNode = dummy;
//由于要用到p.next.val所以要判断p.next!=null
while(preNode != null && preNode.next != null){
ListNode curNode = preNode.next;
int count = 0;
//让curNode指向第一个值不为preNode.next.val的结点
while(curNode != null && preNode.next.val == curNode.val){
curNode = curNode.next;
count++;
}
//如果curNode只跨越了一个结点,说明curNode跨越的该段不重复,
//那么就不用删除,移动preNode即可
if(count == 1) preNode = preNode.next;
else{//curNode跨越了多个结点,目前指向了第一个值不为preNode.next.val的结点
//故直接让preNode.next = curNode,相当于删除了curNode跨越的重复的那段
preNode.next = curNode;
}
}
return dummy.next;//返回dummy.next
}
}
















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









