







文章目录
SQL51 查找字符串中逗号出现的次数

示例1
输入:
drop table if exists strings;
CREATE TABLE strings(
id int(5) NOT NULL PRIMARY KEY,
string varchar(45) NOT NULL
);
insert into strings values
(1, '10,A,B'),
(2, 'A,B,C,D'),
(3, 'A,11,B,C,D,E');
输出:
1|2
2|3
3|5
知识点:replace函数
题解
string长度减去 将逗号替换为空字符串的长度 即是 逗号数量
select
id,
length(string) - length(replace(string, ",", "")) as cnt
from
strings;

SQL52 获取employees中的first_name

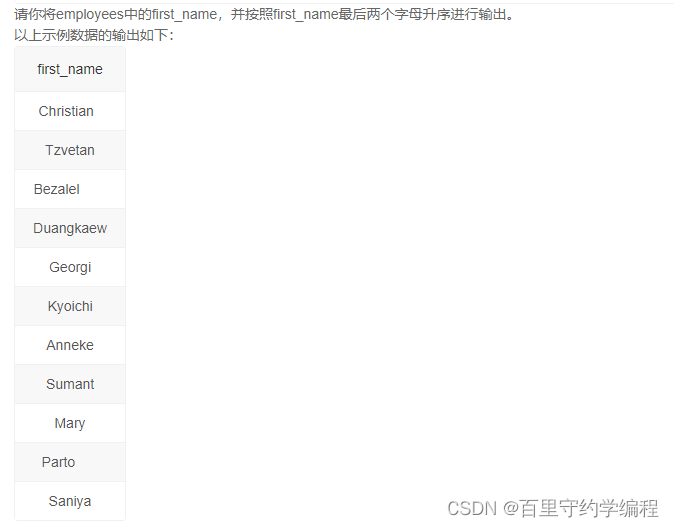
示例1
输入:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
输出:
Chirstian
Tzvetan
Bezalel
Duangkaew
Georgi
Kyoichi
Anneke
Sumant
Mary
Parto
Saniya
知识点:left,right,substr/substring函数
LEFT(s,n)返回字符串 s 的前 n 个字符
RIGHT(s,n)返回字符串 ``s 的后 n 个字符
substr/substring(s,m,n)返回字符串s从m到n的字符,n可以省略,则是到末尾
select
first_name
from
employees
order by
right(first_name, 2);

SQL53 按照dept_no进行汇总

示例1
输入:
drop table if exists `dept_emp` ;
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d004','1995-12-03','9999-01-01');
INSERT INTO dept_emp VALUES(10004,'d004','1986-12-01','9999-01-01');
INSERT INTO dept_emp VALUES(10005,'d003','1989-09-12','9999-01-01');
INSERT INTO dept_emp VALUES(10006,'d002','1990-08-05','9999-01-01');
INSERT INTO dept_emp VALUES(10007,'d005','1989-02-10','9999-01-01');
INSERT INTO dept_emp VALUES(10008,'d005','1998-03-11','2000-07-31');
INSERT INTO dept_emp VALUES(10009,'d006','1985-02-18','9999-01-01');
INSERT INTO dept_emp VALUES(10010,'d005','1996-11-24','2000-06-26');
INSERT INTO dept_emp VALUES(10010,'d006','2000-06-26','9999-01-01');
输出:
d001|10001,10002
d002|10006
d003|10005
d004|10003,10004
d005|10007,10008,10010
d006|10009,10010
知识点:group_concat函数
group_concat()函数将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
注意:当数据太大,group_concat超出了默认值1024,超过就会截断,group_concat查询出来的数据就会不全。
select
dept_no,
group_concat(emp_no) employees
from
dept_emp
group by
dept_no;

SQL54 平均工资

示例1
输入:
drop table if exists `salaries` ;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` float(11,3) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,43699,'2000-12-01','2001-12-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
INSERT INTO salaries VALUES(10004,70698,'2000-11-27','2001-11-27');
INSERT INTO salaries VALUES(10004,74057,'2001-11-27','9999-01-01');
输出:
73292.000
知识点:窗口函数rank
解法一:直接通过两个子查询过滤掉最大最小值
select
avg(salary) as avg_salary
from
salaries
where
to_date = '9999-01-01'
and salary not in (
select max(salary) from salaries where to_date = '9999-01-01')
and salary not in (
select min(salary) from salaries where to_date = '9999-01-01');
解法二:使用rank函数排序后,去掉最大最小值
注意:
- 子查询作为查询表放在
from后面时必须有别名 - 使用
rank函数后的列,如r1,r2不能直接出现在当前的where条件中,只能出现在外层查询中
select
avg(salary) as avg_salary
from
(
select
*,
rank() over (order by salary) r1,
rank() over (order by salary desc) r2
from
salaries
where to_date = '9999-01-01'
) t
where
r1 <> 1
and r2 <> 1;

SQL55 分页查询employees表,每5行一页,返回第2页的数据

示例1
输入:
drop table if exists `employees` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
输出:
10006|1953-04-20|Anneke|Preusig|F|1989-06-02
10007|1957-05-23|Tzvetan|Zielinski|F|1989-02-10
10008|1958-02-19|Saniya|Kalloufi|M|1994-09-15
10009|1952-04-19|Sumant|Peac|F|1985-02-18
10010|1963-06-01|Duangkaew|Piveteau|F|1989-08-24
知识点:limit
LIMIT 语句结构: LIMIT X,Y
Y :返回几条记录
X:从第几条记录开始返回(第一条记录序号为0,默认为0)
select * from employees limit 5,5;

SQL57 使用含有关键字exists查找未分配具体部门的员工的所有信息。
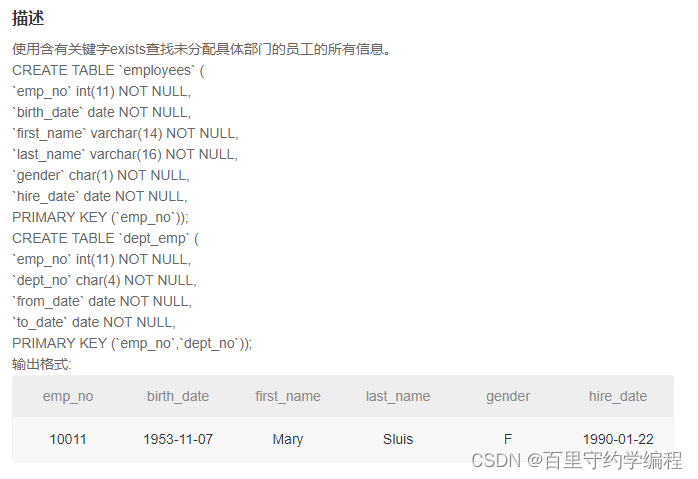
示例1
输入:
drop table if exists employees;
drop table if exists dept_emp;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10003,'1959-12-03','Parto','Bamford','M','1986-08-28');
INSERT INTO employees VALUES(10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
INSERT INTO employees VALUES(10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10');
INSERT INTO employees VALUES(10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15');
INSERT INTO employees VALUES(10009,'1952-04-19','Sumant','Peac','F','1985-02-18');
INSERT INTO employees VALUES(10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
INSERT INTO employees VALUES(10011,'1953-11-07','Mary','Sluis','F','1990-01-22');
INSERT INTO dept_emp VALUES(10001,'d001','1986-06-26','9999-01-01');
INSERT INTO dept_emp VALUES(10002,'d001','1996-08-03','9999-01-01');
INSERT INTO dept_emp VALUES(10003,'d004','1995-12-03','9999-01-01');
INSERT INTO dept_emp VALUES(10004,'d004','1986-12-01','9999-01-01');
INSERT INTO dept_emp VALUES(10005,'d003','1989-09-12','9999-01-01');
INSERT INTO dept_emp VALUES(10006,'d002','1990-08-05','9999-01-01');
INSERT INTO dept_emp VALUES(10007,'d005','1989-02-10','9999-01-01');
INSERT INTO dept_emp VALUES(10008,'d005','1998-03-11','2000-07-31');
INSERT INTO dept_emp VALUES(10009,'d006','1985-02-18','9999-01-01');
INSERT INTO dept_emp VALUES(10010,'d005','1996-11-24','2000-06-26');
INSERT INTO dept_emp VALUES(10010,'d006','2000-06-26','9999-01-01');
输出:
10011|1953-11-07|Mary|Sluis|F|1990-01-22
知识点:exists和in的区别
解法一:关联查询
select
e.*
from
employees e
left join dept_emp d on e.emp_no = d.emp_no
where
d.emp_no is null;
解法二:exists
select *
from employees
where not exists
(
select emp_no
from dept_emp
where employees.emp_no=dept_emp.emp_no
)
EXISTS语句:执行employees.length次
指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
解法三:in
select *
from employees
where emp_no not in
(
select emp_no
from dept_emp
)
IN 语句:只执行一次
确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。

SQL59 获取有奖金的员工相关信息。
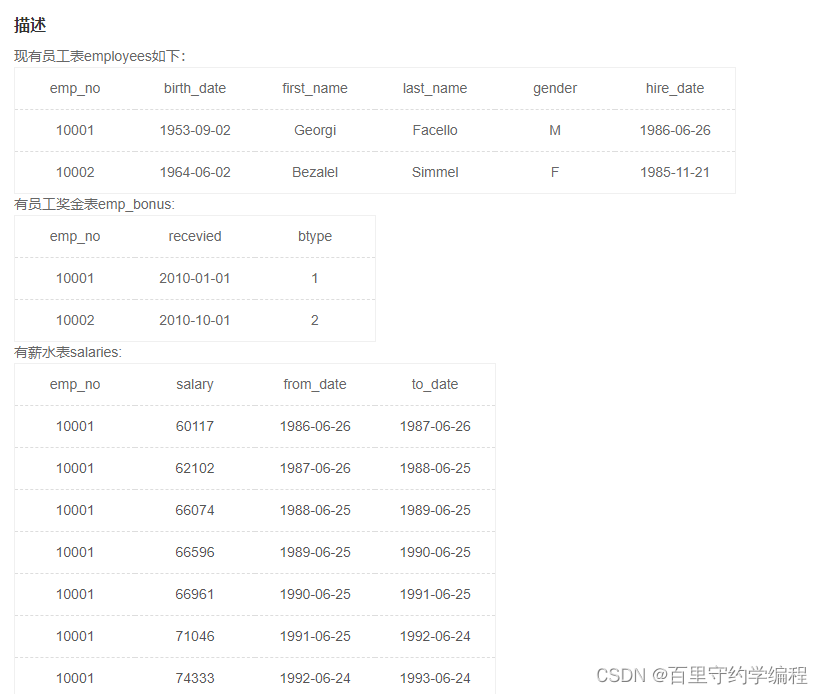

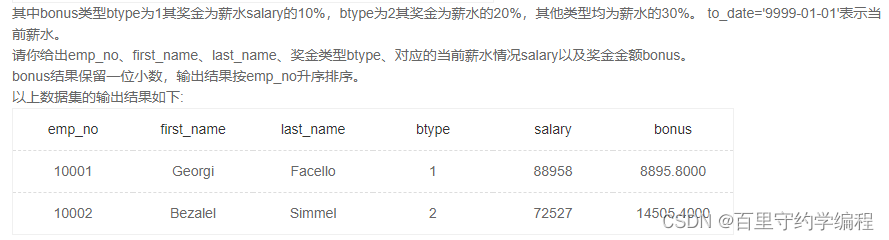
示例1
输入:
drop table if exists `employees` ;
drop table if exists emp_bonus;
drop table if exists `salaries` ;
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
create table emp_bonus(
emp_no int not null,
recevied datetime not null,
btype smallint not null);
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
insert into emp_bonus values
(10001, '2010-01-01',1),
(10002, '2010-10-01',2);
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO salaries VALUES(10001,60117,'1986-06-26','1987-06-26');
INSERT INTO salaries VALUES(10001,62102,'1987-06-26','1988-06-25');
INSERT INTO salaries VALUES(10001,66074,'1988-06-25','1989-06-25');
INSERT INTO salaries VALUES(10001,66596,'1989-06-25','1990-06-25');
INSERT INTO salaries VALUES(10001,66961,'1990-06-25','1991-06-25');
INSERT INTO salaries VALUES(10001,71046,'1991-06-25','1992-06-24');
INSERT INTO salaries VALUES(10001,74333,'1992-06-24','1993-06-24');
INSERT INTO salaries VALUES(10001,75286,'1993-06-24','1994-06-24');
INSERT INTO salaries VALUES(10001,75994,'1994-06-24','1995-06-24');
INSERT INTO salaries VALUES(10001,76884,'1995-06-24','1996-06-23');
INSERT INTO salaries VALUES(10001,80013,'1996-06-23','1997-06-23');
INSERT INTO salaries VALUES(10001,81025,'1997-06-23','1998-06-23');
INSERT INTO salaries VALUES(10001,81097,'1998-06-23','1999-06-23');
INSERT INTO salaries VALUES(10001,84917,'1999-06-23','2000-06-22');
INSERT INTO salaries VALUES(10001,85112,'2000-06-22','2001-06-22');
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','1997-08-03');
INSERT INTO salaries VALUES(10002,72527,'1997-08-03','1998-08-03');
INSERT INTO salaries VALUES(10002,72527,'1998-08-03','1999-08-03');
INSERT INTO salaries VALUES(10002,72527,'1999-08-03','2000-08-02');
INSERT INTO salaries VALUES(10002,72527,'2000-08-02','2001-08-02');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
输出:
10001|Georgi|Facello|1|88958|8895.8
10002|Bezalel|Simmel|2|72527|14505.4
知识点:case when then end 语法
select e.emp_no,e.first_name,e.last_name,b.btype,s.salary,
case when b.btype = 1 then s.salary * 0.1
when b.btype = 2 then s.salary * 0.2
else s.salary * 0.3
end bonus
from employees e
join emp_bonus b on e.emp_no = b.emp_no
join salaries s on e.emp_no = s.emp_no and s.to_date = '9999-01-01';

SQL60 统计salary的累计和running_total
示例1
输入:
drop table if exists `salaries` ;
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
INSERT INTO salaries VALUES(10001,60117,'1986-06-26','1987-06-26');
INSERT INTO salaries VALUES(10001,62102,'1987-06-26','1988-06-25');
INSERT INTO salaries VALUES(10001,66074,'1988-06-25','1989-06-25');
INSERT INTO salaries VALUES(10001,66596,'1989-06-25','1990-06-25');
INSERT INTO salaries VALUES(10001,66961,'1990-06-25','1991-06-25');
INSERT INTO salaries VALUES(10001,71046,'1991-06-25','1992-06-24');
INSERT INTO salaries VALUES(10001,74333,'1992-06-24','1993-06-24');
INSERT INTO salaries VALUES(10001,75286,'1993-06-24','1994-06-24');
INSERT INTO salaries VALUES(10001,75994,'1994-06-24','1995-06-24');
INSERT INTO salaries VALUES(10001,76884,'1995-06-24','1996-06-23');
INSERT INTO salaries VALUES(10001,80013,'1996-06-23','1997-06-23');
INSERT INTO salaries VALUES(10001,81025,'1997-06-23','1998-06-23');
INSERT INTO salaries VALUES(10001,81097,'1998-06-23','1999-06-23');
INSERT INTO salaries VALUES(10001,84917,'1999-06-23','2000-06-22');
INSERT INTO salaries VALUES(10001,85112,'2000-06-22','2001-06-22');
INSERT INTO salaries VALUES(10001,85097,'2001-06-22','2002-06-22');
INSERT INTO salaries VALUES(10001,88958,'2002-06-22','9999-01-01');
INSERT INTO salaries VALUES(10002,72527,'1996-08-03','1997-08-03');
INSERT INTO salaries VALUES(10002,72527,'1997-08-03','1998-08-03');
INSERT INTO salaries VALUES(10002,72527,'1998-08-03','1999-08-03');
INSERT INTO salaries VALUES(10002,72527,'1999-08-03','2000-08-02');
INSERT INTO salaries VALUES(10002,72527,'2000-08-02','2001-08-02');
INSERT INTO salaries VALUES(10002,72527,'2001-08-02','9999-01-01');
INSERT INTO salaries VALUES(10003,40006,'1995-12-03','1996-12-02');
INSERT INTO salaries VALUES(10003,43616,'1996-12-02','1997-12-02');
INSERT INTO salaries VALUES(10003,43466,'1997-12-02','1998-12-02');
INSERT INTO salaries VALUES(10003,43636,'1998-12-02','1999-12-02');
INSERT INTO salaries VALUES(10003,43478,'1999-12-02','2000-12-01');
INSERT INTO salaries VALUES(10003,43699,'2000-12-01','2001-12-01');
INSERT INTO salaries VALUES(10003,43311,'2001-12-01','9999-01-01');
输出:
10001|88958|88958
10002|72527|161485
10003|43311|204796
知识点:窗口函数
窗口函数也称OLAP函数(online analytical processing),意思对数据库进行实时分析。
语法:
<窗口函数> OVER ([PARTITION BY <列清单>]
ORDER BY <排序用列清单>)
[]可省略
窗口函数分为两类:1)聚合函数;2)专用函数
聚合函数:sum,min,max,avg,count
专用窗口函数:rank,dense_rank,row_number
select emp_no,salary,sum(salary) over(order by emp_no) running_total
from salaries
where to_date = '9999-01-01';
















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









