







文章目录
在日常工作中,redis可以说是最常用的一个组件了,而当redis并发高到一定的程度就可能会出现HotKey的问题,今天我们来看下Redis中的HotKey如何解决。
一:介绍
1. 什么是HotKey
在较短的时间内,海量请求访问一个Key,这样的Key就被称为HotKey。具体而言,redis 集群部署方式大部分采用类 Twemproxy 的方式进行部署。即通过 Twemproxy 对 redis key 进行分片计算,将 redis key 进行分片计算,分配到多个 redis 实例中的其中一个。tewmproxy 架构图如下:
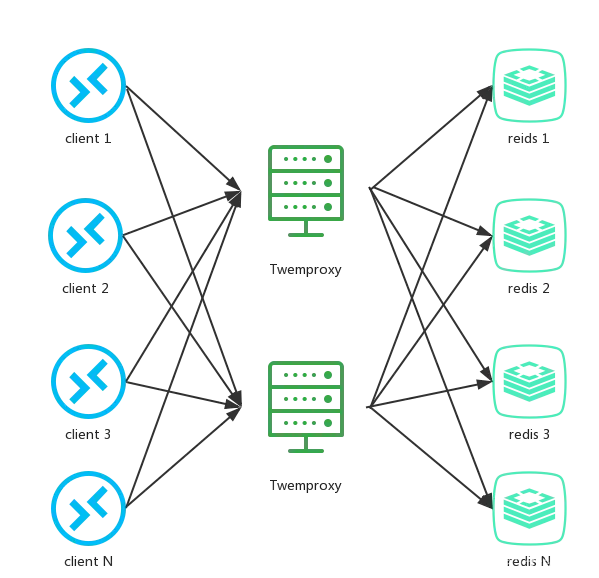
Hot key,即热点 key,指的是在一段时间内,该 key 的访问量远远高于其他的 redis key, 导致大部分的访问流量在经过proxy分片之后,都集中访问到某一个 redis 实例上。hot key 通常在不同业务中,存储着不同的热点信息。比如
-
新闻应用中的热点新闻内容;
-
活动系统中某个用户疯狂参与的活动的活动配置;
-
商城秒杀系统中,最吸引用户眼球,性价比最高的商品信息;
……
2. HotKey的危害
- 海量请求在较短的时间内,访问一个
Key,势必会导致被访问的Redis服务器压力剧增,可能会将Redis服务器击垮,从而影响线上业务; - HotKey过期的一瞬间,海量请求在较短的时间内,访问这个
Key,因为Key过期了,这些请求会走到数据库,可能会将数据库击垮,从而影响线上业务。(这是缓存击穿问题)
二:系统上解决(事前)
1. Redis部署
通常来说,Redis有两种集群形式:数据分片集群、主从+哨兵集群,其实这两种集群形式或多或少的都一定程度上缓解了HotKey的问题。
单主部署:
所有的读写请求都打到该节点上,都不用管Key是什么,只要并发一高,就会导致Redis服务器压力剧增;一旦仅有的一个Redis服务器挂了,就没有第二个Redis服务器顶上去了,无法继续提供服务,因为这是唯一的服务实例节点。一般仅用于个人学习和测试。
主从模式:
写请求由主节点处理,读请求走从节点,一般会部署一主一从,或一主两从,主节点挂掉后,从节点不会升级为主节点的。一般也是用于个人学习和测试。
主从+哨兵集群:
- 读请求会被分散到
Master节点或者多台Slave节点,将请求进行了初步的分散; Master节点挂了,Slave节点会升级为新的Master节点,继续提供服务。- 业务规模不大时,可采用该模式部署。
数据分片集群:
- 多个主从+哨兵集群在一起组成分片集群模式
Key被分散在了不同的Redis节点,将请求进行了进一步的分散。- 写请求会被分散到多个
Master节点(通过slot存数据,会计算出每个Master持有哪些slot的),读请求也会分散到多台Slave节点,将请求进行了初步的分散; Master节点挂了,Slave节点会升级为新的Master节点,继续提供服务。- 用于业务规模较大时
2. 隔离
不同的业务分配不同的Redis集群,不要将所有的业务都“混杂”在一个Redis集群。如本人在工作中,一般是每个微服务模块对应各自的Redis集群。
只要可以做到集群+隔离,在一定程度上就已经避免了HotKey,但是对于超高并发的系统来说,可能还有点不够,所以才会有下面的更进一步的措施。
三:如何应对HotKey(事中)
这个问题,可以拆分成三个子问题:如何发现HotKey、如何通知HotKey的产生、如何对HotKey进行处理。
1. 如何发现HotKey
如何发现HotKey的前提是知道每个Key的使用情况,并进行统计,所以这又拆成了两个更小的子问题:如何知道每个Key的使用情况,如何进行统计。
如何知道每个Key的使用情况
谁最清楚知道每个Key的使用情况,当然是客户端、代理层,所以我们可以在客户端或者代理层进行埋点。
1.1 客户端埋点: (不推荐,但是在运维资源缺少的场景下可以考虑。开发可以绕过运维搞定)
在客户端请求Redis的代码中进行埋点,使用metrics上报。
优点:
- 实现较为简单
- 轻量级
- 几乎没有性能损耗
缺点:
- 进行统一管理较为麻烦:如果想开启或者关闭埋点、上报,会比较麻烦
- 升级和迭代也较为麻烦:如果埋点、上报方式需要优化,就需要修改代码发布上线
- 客户端会有一定的压力:不管是实时上报使用情况,还是准实时上报使用情况,都会对客户端造成一定的压力
1.2 代理层埋点:(推荐,运维来做自然是最好的方案)
客户端不直接连接Redis集群,而是连接Redis代理,在代理层进行埋点。
优点:
- 客户端没有压力
- 对客户端完全透明
- 升级、迭代比较简单
- 进行统一管理比较简单
缺点:
- 实现复杂
- 会有一定的性能损耗:代理层需要转发请求到真正的
Redis集群 - 单点故障问题:需要做到高可用,更复杂
- 单点热点问题:代理层本身就是一个热点,需要分散热点,更复杂
2. 如何上报每个Key的使用情况
我们在客户端或者代理层进行了埋点,自然是由它们上报每个Key的使用情况,如何上报又是一个小话题。
2.1 实时/准实时
- 实时上报:每次请求,都进行上报
- 准实时上报:积累一定量或者一定时间的请求,再进行上报
2.2 是否预统计
如果采用准实时上报,在客户端或者代理层是否对使用情况进行预统计:
- 进行预统计:减少上报的数据量,减轻统计的压力,自身会有压力
- 不进行预统计:上报的数据量比较多,自身几乎没有压力
如何统计
不管如何进行上报,使用情况最终都会通过Kafka,发送到统计端,这个时候统计端就来活了。 一般来说,这个时候会借助于大数据,较为简单的方式:Flink开一个时间窗口,消费Kafka的数据,对时间窗口内的数据进行统计,如果在一个时间窗口内,某个Key的使用达了一定的阈值,就代表这是一个HotKey。
3. 如何通知HotKey的产生
经过上面的步骤,我们已经知道了某个HotKey产生了,这个时候就需要通知到客户端或者代理层,那如何通知HotKey的产生呢?
- MQ:用
MQ通知客户端或者代理层HotKey是什么 - RPC/Http:通过
RPC/Http通知客户端或者代理层HotKey是什么 - 配置中心/注册中心指令:既然遇到了
HotKey的问题,并且想解决,那基本上是技术实力非常强大的公司,应该有非常完善的服务治理体系,此时,可以通过配置中心/注册中心下发指令到客户端或者代理层,告知HotKey是什么
四:如何处理HotKey(事前)
客户端或者代理层已经知晓了HotKey产生了,就自动开启一定的策略,来避免HotKey带来的热点问题:
- 使用本地缓存,不至于让所有请求都打到
Redis集群 - 将
HotKey的数据复制多份,分散到不同的Redis节点上
在实际开发中,可能在很大程度上,都不会有埋点、上报、统计,通知、策略自动开启,这一套比较完善的Redis HotKey解决方案,我们能做到的就是预估某个Key可能会成为热点,就采用本地缓存+复制多份HotKey数据的方式来避免HotKey带来的热点问题。我们还经常会因为偷懒,所以设计了一个大而全的Key,所有的业务都从这个Key中读取数据,但是有些业务只需要其中的一小部分数据,有些业务只需要另外一小部分数据,如果不同的业务读取不同的Key,又可以将请求进行分散,这是非常简单,而且有效的方式(实际上这种情况既是Hot Key,也可能是Big Key)。
1. 本地缓存(不推荐)
在 client 端使用本地缓存,从而降低了redis集群对hot key的访问量,但是同时带来两个问题:
- 如果对可能成为
hot key的key都进行本地缓存,那么本地缓存是否会过大,从而影响应用程序本身所需的缓存开销。 - 如何保证本地缓存和
redis集群数据的有效期的一致性。
2. 利用分片算法的特性,对key进行打散处理(推荐)
我们知道 Hot Key 之所以是 Hot Key,是因为它只有一个Key,落地到一个实例上。所以我们可以给Hot Key加上前缀或者后缀,把一个 Hot Key的数量变成 redis 实例个数N的倍数M,从而由访问一个 redis key 变成访问 N * M 个redis key。而N*M 个 redis key 经过分片分布到不同的实例上,将访问量均摊到所有实例。
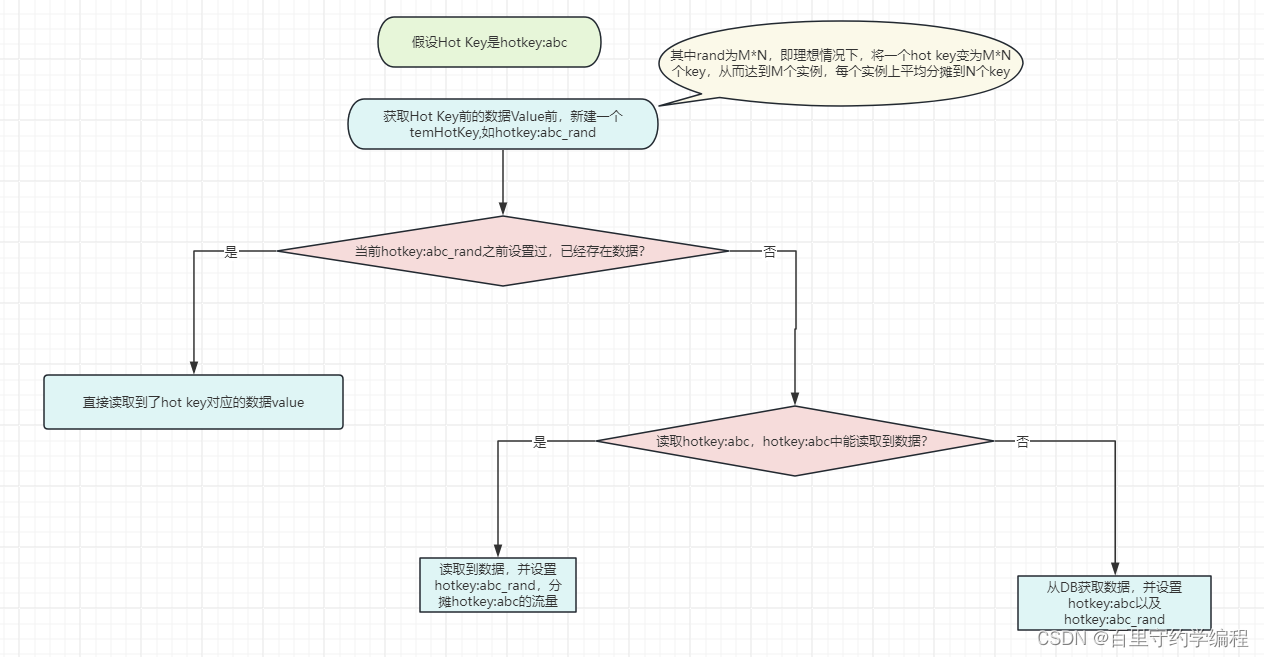
主要流程伪代码如下:
//redis 实例数
const M = 16
//redis 实例数倍数(按需设计,2^n倍,n一般为1到4的整数)
const N = 2
func main() {
//获取 redis 实例
c, err := redis.Dial("tcp", "127.0.0.1:6379")
if err != nil {
fmt.Println("Connect to redis error", err)
return
}
defer c.Close()
hotKey := "hotKey:abc"
//产生[1,N*M)之间的一个随机数
randNum := GenerateRangeNum(1, N*M)
//得到对 hot key 进行打散的 key
tmpHotKey := hotKey + "_" + strconv.Itoa(randNum)
//hot key 过期时间
expireTime := 50
//过期时间平缓化的一个时间随机值,产生一个[0,5)之间的随机数
randExpireTime := GenerateRangeNum(0, 5)
data, err := redis.String(c.Do("GET", tmpHotKey))
if err != nil {
data, err = redis.String(c.Do("GET", hotKey))
if err != nil {
data = GetDataFromDb()
c.Do("SET", "hotKey", data, expireTime)
c.Do("SET", tmpHotKey, data, expireTime + randExpireTime)
} else {
c.Do("SET", tmpHotKey, data, expireTime + randExpireTime)
}
}
}
在这个代码中,通过一个大于等于 1 小于 M * N 的随机数,得到一个 tmp key,程序会优先访问tmp key,在得不到数据的情况下,再访问原来的 hot key,并将 hot key的内容写回 tmp key。值得注意的是,tmp key的过期时间是 hot key 的过期时间加上一个较小的随机正整数,保证在 hot key 过期时,所有 tmp key 不会同时过期而造成缓存雪崩。这是一种通过坡度过期的方式来避免雪崩的思路,同时也可以利用原子锁来写入数据就更加的完美,减小db的压力。
另外还有一件事值得一提,默认情况下,我们在生成 tmp key的时候,会把随机数作为 hot key 的后缀,这样符合redis的命名空间(用:或_分隔单词),方便 key 的收归和管理。但是存在一种极端的情况,就是hot key的长度很长,这个时候随机数不能作为后缀添加,原因是Twemproxy的分片算法在计算过程中,越靠前的字符权重越大,靠后的字符权重则越小。也就是说对于key名,前面的字符差异越大,算出来的分片值差异也越大,更有可能分配到不同的实例(具体算法这里不展开讲)。所以,对于很长key名的 hot key,要对随机数的放入做谨慎处理,比如放在在最后一个命令空间的最前面(eg:由原来的 space1:space2:space3_rand 改成 space1:space2:rand_space3)。
五:总结
在业务开发阶段,就要对可能变成 Hot Key ,Big Key 的数据进行判断,提前处理,这需要的是对产品业务的理解,对运营节奏的把握,对数据设计的经验。不要到线上实际产生Hot Key 或 Big Key时才处理,那将是很棘手的一件事。















 2501
2501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









