







消息队列发送消息和消费消息的过程,共分为三段,生产过程、服务端持久化过程、消费过程,如下图所示。
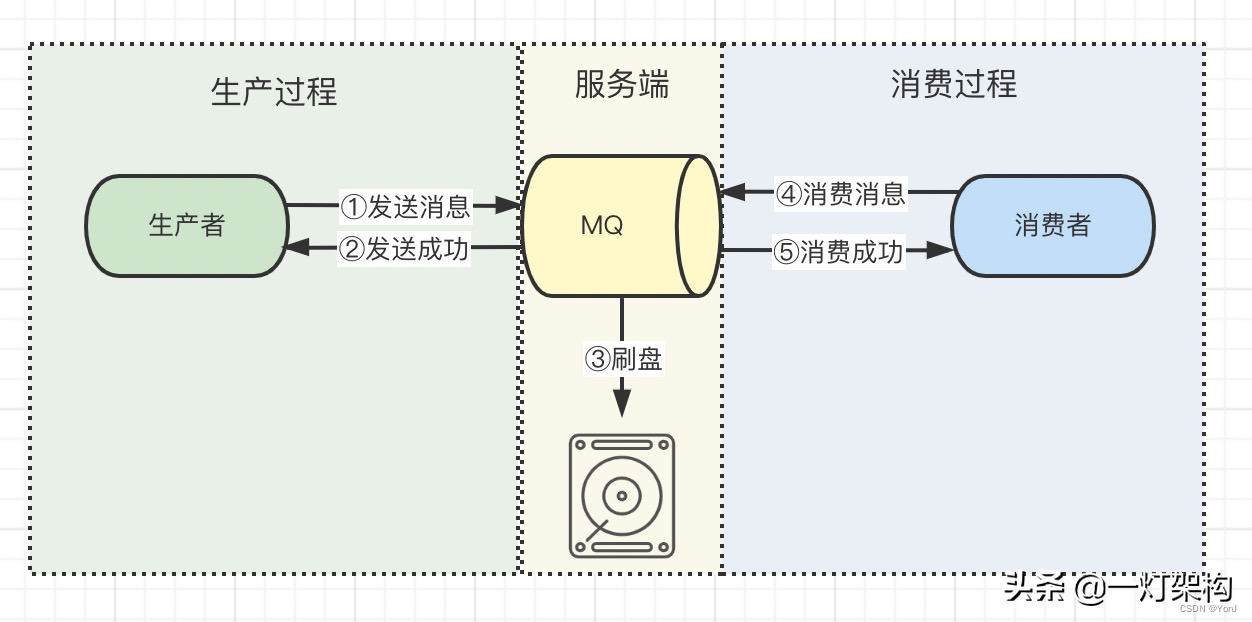
这三个过程都有可能弄丢消息。
面试官: 嗯,消息丢失的具体原因是什么?怎么防止丢失消息呢?
我: 我详细说一下这种情况:
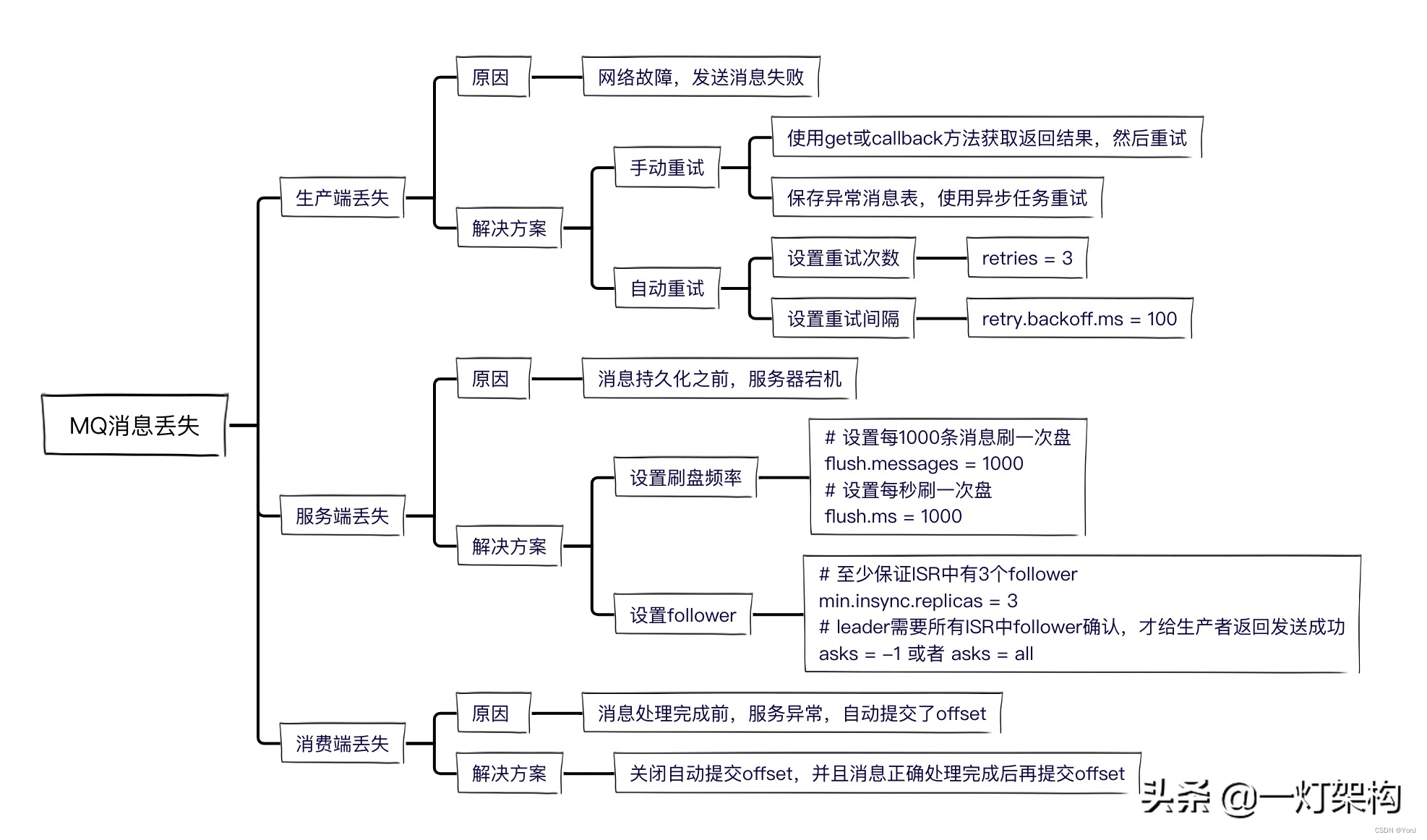
一、生产过程丢失消息
丢失原因:一般可能是网络故障,导致消息没有发送出去。
解决方案:重发就行了。
由于kafka为了提高性能,采用了异步发送消息。我们只有获取到发送结果,才能确保消息发送成功。 有两个方案可以获取发送结果。
一种是kafka把发送结果封装在Future对象中,我可以使用Future的get方法同步阻塞获取结果。
Future<RecordMetadata> future = producer.send(new ProducerRecord<>(topic, message));
try {
RecordMetadata recordMetadata = future.get();
if (recordMetadata != null) {
System.out.println("发送成功");
}
} catch (Exception e) {
e.printStackTrace();
}另一种是使用kafka的callback函数获取返回结果。
producer.send(new ProducerRecord<>(topic, message), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("发送成功");
} else {
System.out.println("发送失败");
}
}
});如果发送失败了,有两种重试方案:
- 手动重试 在catch逻辑或else逻辑中,再调用一次send方法。如果还不成功怎么办? 在数据库中建一张异常消息表,把失败消息存入表中,然后搞个异步任务重试,便于控制重试次数和间隔时间。
- 自动重试 kafka支持自动重试,设置参数如下,当集群Leader选举中或者Follower数量不足等原因返回失败时,就可以自动重试。
- # 设置重试次数为3
retries = 3# 设置重试间隔为100msretry.backoff.ms = 100 - 一般我们不会用kafka自动重试,因为超过重试次数,还是会返回失败,还需要我们手动重试。
二、服务端持久化过程丢失消息
为了保证性能,kafka采用的是异步刷盘,当我们发送消息成功后,Broker节点在刷盘之前宕机了,就会导致消息丢失。
当然我们也可以设置刷盘频率:
# 设置每1000条消息刷一次盘
flush.messages = 1000
# 设置每秒刷一次盘
flush.ms = 1000先普及一下kafka集群的架构模型:
kafka集群由多个broker组成,一个broker就是一个节点(机器)。 一个topic有多个partition(分区),每个partition分布在不同的broker上面,可以充分利用分布式机器性能,扩容时只需要加机器、加partition就行了。
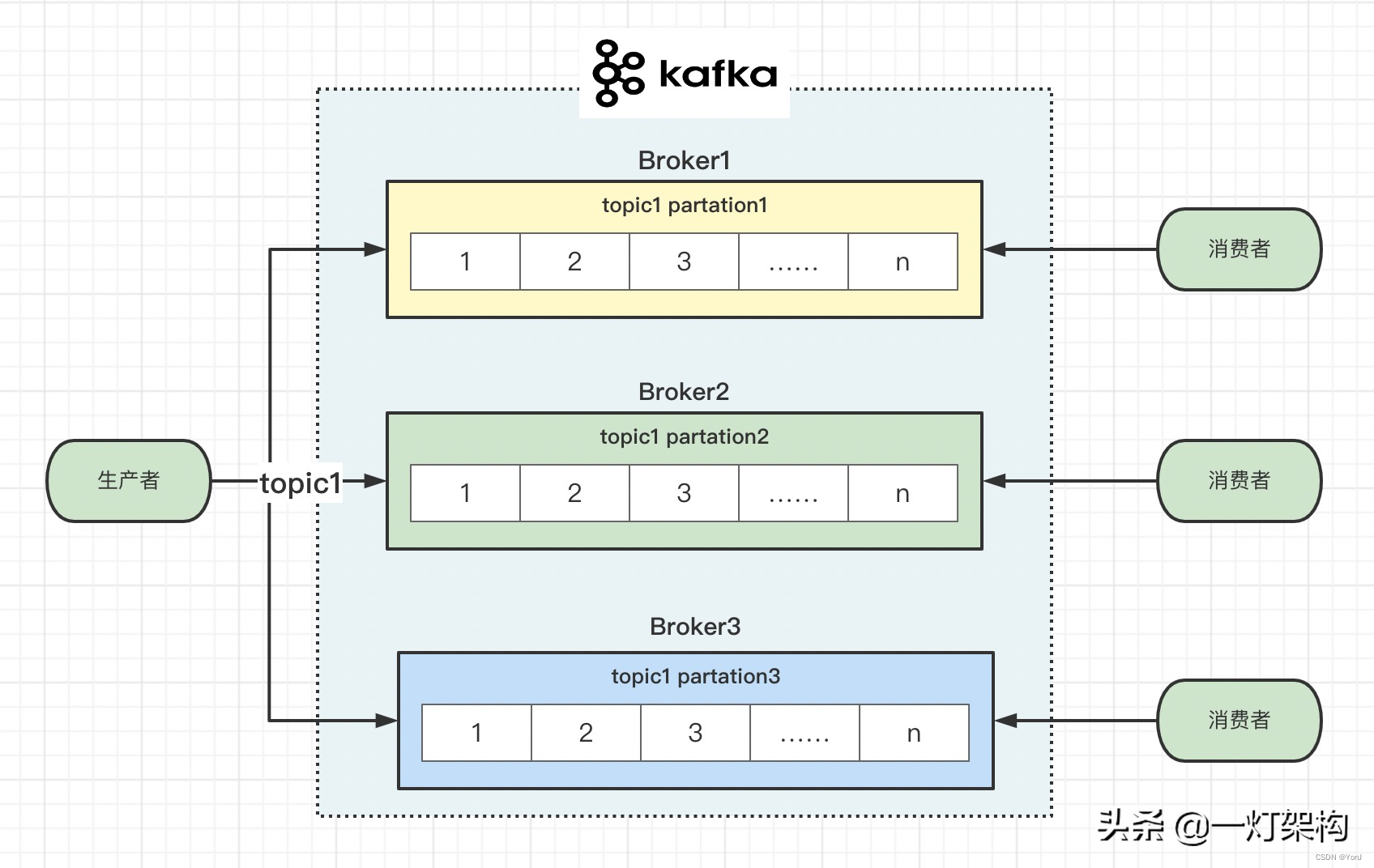
一个partition又有多个replica(副本),有一个leader replica(主副本)和多个follower replica(从副本),这样设计是为了保证数据的安全性。
发送消息和消费消息都在leader上面,follower负责定时从leader上面拉取消息,只有follower从leader上面把这条消息拉取回来,才算生产者发送消息成功。
kafka为了加快持久化消息的性能,把性能较好的follower组成一个ISR列表(in-sync replica),把性能较差的follower组成一个OSR列表(out-of-sync replica),ISR+OSR=AR(assigned repllicas)。 如果某个follower一段时间没有向leader拉取消息,落后leader太多,就把它移出ISR,放到OSR之中。 如果某个follower追上了leader,又会把它重新放到ISR之中。 如果leader挂掉,就会从ISR之中选一个follower做leader。
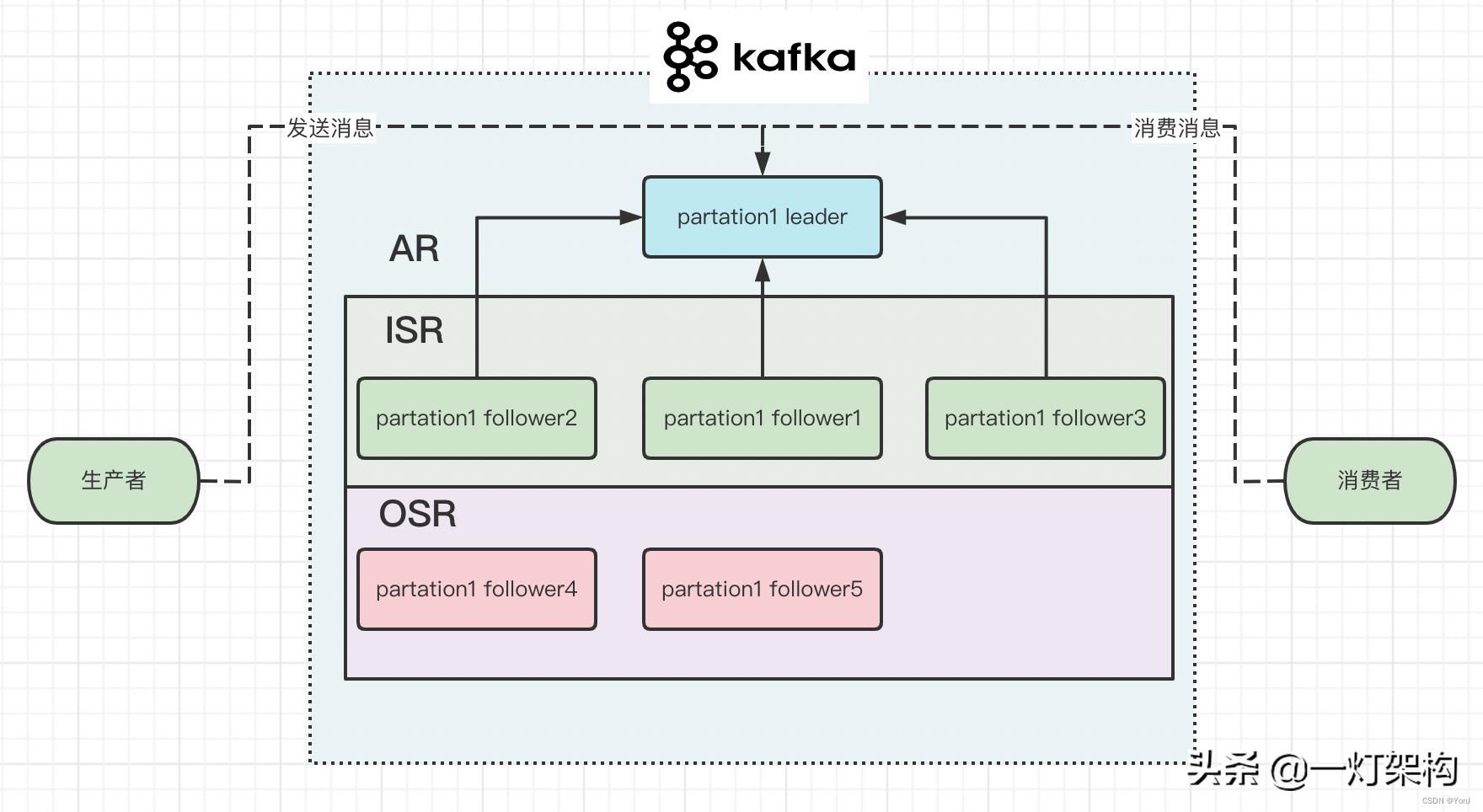
为了提升持久化消息性能,我们可以进行一些设置:
# 如果follower超过一秒没有向leader拉取消息,就把它移出ISR列表
rerplica.lag.time.max.ms = 1000
# 如果follower落后leader一千条消息,就把它移出ISR列表
rerplica.lag.max.messages = 1000
# 至少保证ISR中有3个follower
min.insync.replicas = 3
# 异步消息,不需要leader确认,立即给生产者返回发送成功,丢失消息概率较大
asks = 0
# leader把消息写入本地日志中,不会等所有follower确认,就给生产者返回发送成功,小概率丢失消息
asks = 1
# leader需要所有ISR中follower确认,才给生产者返回发送成功,不会丢失消息
asks = -1 或者 asks = all三、消费过程丢失消息
kafka中有个offset的概念,consumer从partition中拉取消息,consumer本地处理完成后需要commit一下offset,表示消费完成,下次就不会再拉取到这条消息。
所以我们需要关闭自动commit offset的配置,防止consumer拉到消息后,服务宕机,导致消息丢失。
enable.auto.commit = false面试官: 还得是你,就你总结的全,我都想不那么全,明天来上班吧,薪资double。
本文知识点总结:














 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









