







3.3 连接查询
同样地,对于连接查询,在有没有分区的条件下,将有性能3倍左右的差距。对于更大的数据量,可能会有更大的性能差距。SQL如下:
select count(*) from salaries s left join employees e on s.emp_no=e.emp_no where s.from_date between '1999-01-01' and '1999-12-31' ;
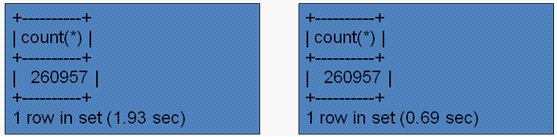
无采用分区 采用分区
3.4 删除查询
为了删除1998年的销售数据,那么在有分区情况下可以不利用delete查询快速地完成垃圾数据的清理。
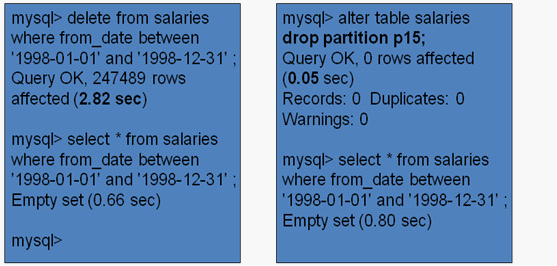
可知,对于有分区的情况下,只需要将某个分区删除掉即可,时间仅为0.05s,相对应原来的2.82s,这个提升是非常高的。 当然,利用分区功能的数据删除之后,数据文件如下:
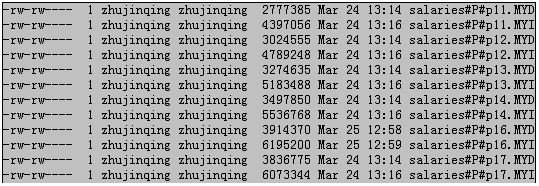
那么接下来如果接着插入1998年的数据,数据是否丢失了呢?还是会写不进去?答案也都是否定,它会将数据写入p16分区中。有兴趣的读者可以自己收到试试。
4. 总结和不足
所以,分区的好处有很多:
1. 与单个磁盘或文件系统分区相比,可以存储更多的数据
2. 对于那些已经失去保存意义的数据,通常可以通过删除与那些数据有关的分区,很容易地删除那些数据。
3. 一些查询可以得到极大的优化,如where语句数据可以只保存在一个或多个分区内
4. 涉及到例如SUM() 和 COUNT()这样聚合函数的查询,可以很容易地进行并行处理
5. 通过跨多个磁盘来分散数据查询,来获得更大的查询吞吐量
在设计分区过程中,需要考虑的因素有很多,如:
– 分区的列
– 分区使用的函数,特别为非Integer类型的列
– 服务器性能
– 内存大小
根据分区技术,有一些技巧:
– 若索引的大小 > RAM,考虑选用分区,不采用索引
– 尽量不采用Primary Key做分区的key
– 当CPU性能高的时候,考虑使用Archive存储引擎
– 对于大量的历史数据,考虑使用Archive+PARTITION
–总之,
MySQL分区技术是一种逻辑的水平分表技术;
它只访问需要访问的分区,从而提高性能;
支持range, hash, key, list和复合分区方法;
支持MySQL服务器所支持的任何存储引擎;
除了Key分区方法,Partition的key 必须是整数(或者能转化成整数)。















11-12
 1101
1101
1101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









