







此文章写出来不是给别人参考的,仅仅是自己的一个学习笔记。
1.索引的本质
之前不懂索引,老师都给说,索引就是你查字典里面的根据拼音搜索。。。类似于这样的解释。后来某一天看到一句话:索引的本质是排好序的数据结构。 我们可以借助树来实现索引,同样的也可以借助hash表来实现索引。但是索引本质上就是排好序的数据结构。例如下图,如果直接查找这张表中Col2 = 23的字段:select * from table1 where Col2 = 23 那么需要遍历表,一行一行的查找。运气不好,需要查找7次才能得到我们的结果。但是如果建立了一个二叉树索引,那么我们只要查询3次就会得到结果。这就是索引为什么那么快的原因。

2.二叉树,红黑树,B树,B+树。
mysql的索引采用的是B+树。树结构,我只是知道一点皮毛,关于树的很多公式,我就是白痴。树有很多结构,推荐一个网站,可以比较直观的看到数据结构,方便学习:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
2.1二叉树
二叉树如下图所示,他又很多的特性,不啦不啦的一大堆,也记不住,但是有一个是显而易见的,就是从左往右依次增大,右侧的数据比左侧大。这个比链表搜索起来要快很多。

但是二叉树也是有缺点的,例如下图的元素都是递增的,很发生很严重的偏移,增加树的深度,二叉树退化成了一张链表。

2.2 红黑树
红黑树是二叉平衡树的一种,如下图。当树发生严重偏移的时候,他会自己平衡。可以对比二叉树存储1-7元素和红黑树存储1-7元素。树的深度减少很多,增加查询效率。

2.3 B树
红黑树当存储的数据太多的时候,还是避免不了树太深的缺点,因为一个节点只能二叉,而不是多叉。这个时候就可以用B树。
b树一个节点可以存储多个元素,而且一个节点可以多叉。这样就很好的解决了树的深度的问题。那么B树是不是就是无敌的。
也不是,因为我们现在有这样一个需求范围查找。select * from B树 where id >0003。这个时候还是要从根节点多次查找。就很没有效率。
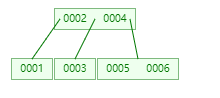
2.4 B+树
b+树在最低级的叶子节点有指针指向下一个叶子节点。这样底层有点链表的那种感觉。这样范围查找起来,就能直接从0003找到0004,快速的进行范围查找。
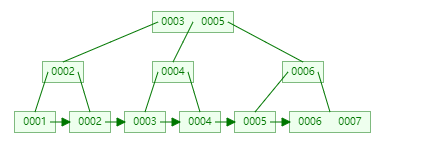
Mysql的底层索引就是这种B+树结构:只有最底层的叶子节点才存储data。这个data就是一个磁盘地址。一个节点的大小,mysql默认是16384bit=16KB。通过show global status like "Innodb_page_size"可以查看。一个bigint类型的索引大概是14B,那么一个节点大概就可以放16384/14个索引。如果树的深度是3的话。那么索引大概可以支撑2000w的数据查询。


3.mysql的存储引擎
mysql的存储引擎是表级别的,不是库级别的。同一个数据库下面,表A可以用myisam,表B可以用Innodb,并不冲突。用navicat建表的时候,就有选项来指定存储引擎。

3.1 MyISAM存储引擎
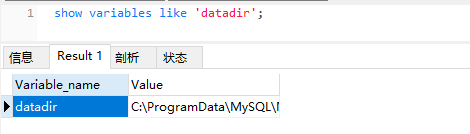
MyISAM的存储引擎是数据和索引分离的。我们可以打开数据库的存储数据的文件夹datadir来查看一下(show variables like 'datadir')。
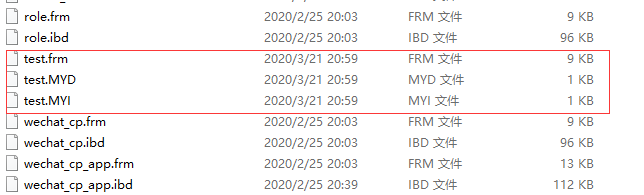
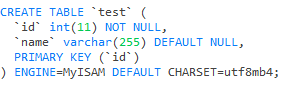
我新建了一张表test,选择了MyISAM存储引擎。这个时候在datadir就有了三个test相关的文件。test.frm 这个是存储表结构的。test.MYD这个以MYD结尾的文件,其实就是MyISAM Data存储的是表里面实际的一行一行的数据。test.MYI以MYI结尾的文件其实就是MyISAM Index存的就是索引文件。没错,MyISAM将索引和数据是分开存储的,非聚集的。可以参照下图:

3.2 Innodb存储引擎
我们来看一下Innodb表的数据文件是什么样子的。


innodb也有一个.frm文件,.frm就是.frame框架的意思,存储的是表的结构。另外一个.ibd文件是索引和数据的混合文件。innodb是将索引和数据存储在一起的,是聚集的。可以参考下图:

innodb索引面试问题1:我们没有给表指定索引,是不是就没有索引了。
答:根据这个索引B+树结构。innodb是将数据和索引存储在一起的。所以即使我们没有给他指定索引,但是指定了唯一键的话,那么唯一键就是索引了。如果连唯一键都没有,那么innodb就会自己生成ROW_ID用来维护树的索引结构。
innodb索引面试问题2:innodb为什么推荐使用整形自增的主键。
答:整型自增比较uuid来说,比大小上速度会很快。例如22>20一下子就比较了出来。但是hello>issue就需要将字符转换成ASCII码来比较,比较慢。另外一个uuid占用空间比较大,而整型占用空间比较少。
3.2.1 联合索引
联合索引的存储结构如下图。每个节点将几个字段加起来当作一个索引,比较的时候从上往下查找,如果第一个不符合了,就直接PASS掉了。这也就是为什么索引有一个最左匹配原则。总之聚合索引就朝着这张图上靠。

3.2.2 一张表多个索引
按照以上的数据结构,就会有一个问题:索引和数据存储在一起,那么当有多个数据的时候怎么办,数据不久存在多份,不久冗余了嘛?其实不是的,当多个索引的时候,多个索引是这样子存在的:
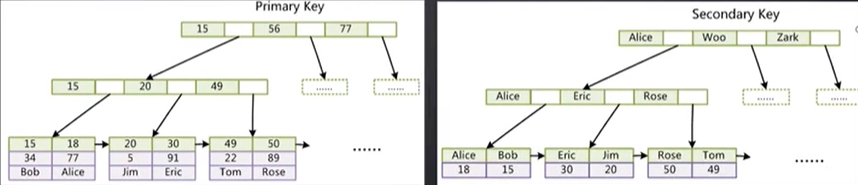
非主键索引最底层的节点存储的不是具体数据,而是主键的ID。这样查询到主键ID之后,再到主键索引这边进行二次查找,也很快。当然肯定是主键是最快的。















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









