






进程是对运行时程序的封装,是系统进行资源调度和分配的的基本单位,实现了操作系统的并发; 线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发;线程是操作系统可识别的最小执行和调度单位。 每个线程都独自占用一个虚拟处理器:独自的寄存器组,指令计数器和处理器状态。
I/O(英语:Input/Output),即输入/输出,通常指数据在内部存储器和外部存储器或其他周边设备之间的输入和输出。
NoSQL 数据库(意即"不仅仅是SQL")并非表格格式,其存储数据的方式与关系表不同。 NoSQL 数据库的类型因数据模型而异。 主要类型包括文档、键值、宽列和图形。 它们提供了灵活的模式,可以随大量数据和高用户负载而轻松扩展。
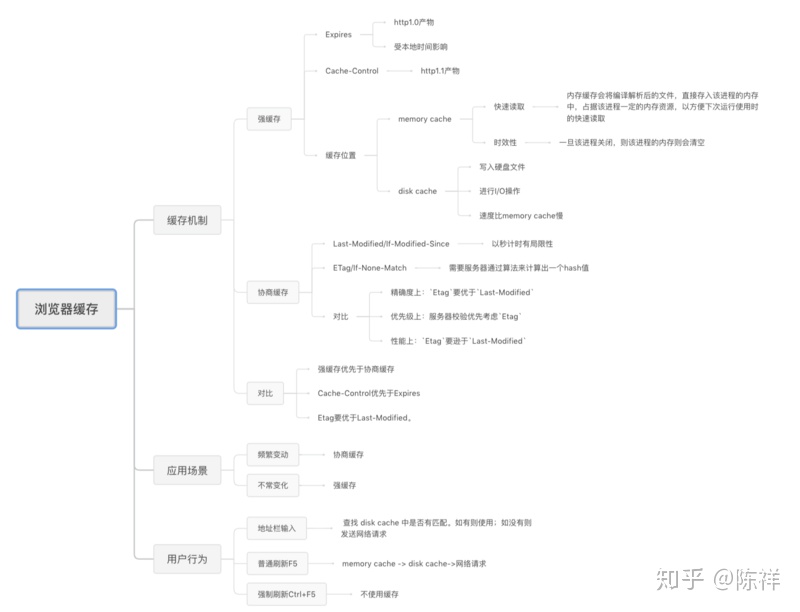
web缓存大致可以分为:数据库数据缓存、服务器端缓存(代理服务器缓存、CDN缓存)、浏览器端缓存、web应用层缓存。
其中,浏览器端缓存的机制种类:HTTP缓存机制、浏览器本地存储(cookie 、localStorage、sessionStorage、webSQL、indexDB、……)
1、缓存机制
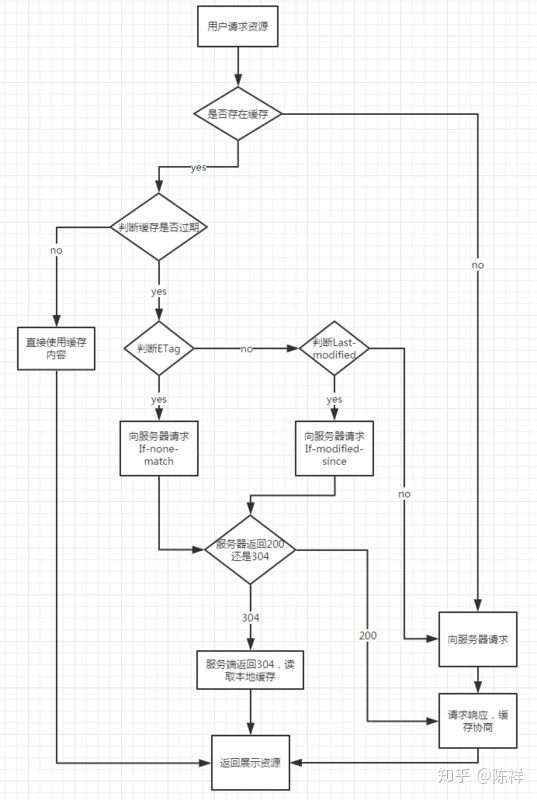
首先我们来总体感知一下它的匹配流程,如下: 1. 浏览器发送请求前,根据请求头的expires和cache-control判断是否命中(包括是否过期)强缓存策略,如果命中,直接从缓存获取资源,并不会发送请求。如果没有命中,则进入下一步。 2. 没有命中强缓存规则,浏览器会发送请求,根据请求头的last-modified和etag判断是否命中协商缓存,如果命中,直接从缓存获取资源。如果没有命中,则进入下一步。 3. 如果前两步都没有命中,则直接从服务端获取资源。
2、强缓存
强缓存:不会向服务器发送请求,直接从缓存中读取资源。
2.1 强缓存原理
强制缓存就是向浏览器缓存查找该请求结果,并根据该结果的缓存规则来决定是否使用该缓存结果的过程,强制缓存的情况主要有三种(暂不分析协商缓存过程),如下:
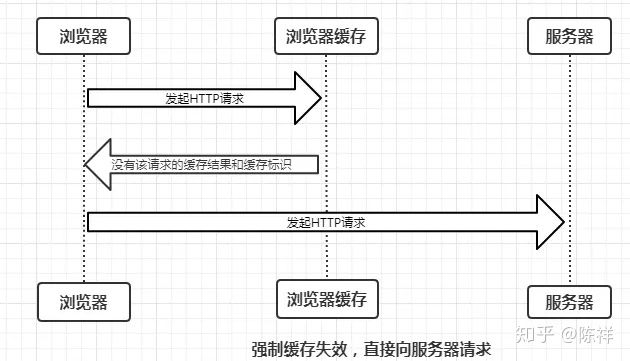
- 第一次请求,不存在缓存结果和缓存标识,直接向服务器发送请求
- 存在缓存标识和缓存结果,但是已经失效,强制缓存是啊比,则使用协商缓存(暂不分析)

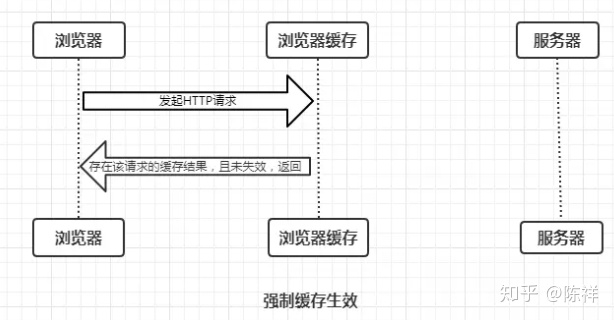
- 存在该缓存结果和缓存标识,且该结果尚未失效,强制缓存生效,直接返回该结果
那么强制缓存的缓存规则是什么? 当浏览器向服务器发起请求时,服务器会将缓存规则放入HTTP响应报文的HTTP头中和请求结果一起返回给浏览器,控制强制缓存的字段分别是Expires和Cache-Control,其中Cache-Control优先级比Expires高。
2.1.1、 Expires
缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点。也就是说,Expires=max-age + 请求时间,需要和Last-modified结合使用。Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
Expires 是 HTTP/1 的产物,受限于本地时间,如果修改了本地时间,可能会造成缓存失效。
2.1.2、 Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存,主要取值为: - public:所有内容都将被缓存(客户端和代理服务器都可缓存) - private:所有内容只有客户端可以缓存,Cache-Control的默认取值 - no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定 - no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存 - max-age=xxx (xxx is numeric):缓存内容将在xxx秒后失效
需要注意的是,no-cache这个名字有一点误导。设置了no-cache之后,并不是说浏览器就不再缓存数据,只是浏览器在使用缓存数据时,需要先确认一下数据是否还跟服务器保持一致,也就是协商缓存。而no-store才表示不会被缓存,即不使用强制缓存,也不使用协商缓存
2.1.3、设置
强缓存需要服务端设置expires和cache-control。 nginx代码参考,设置了一年的缓存时间:
location ~ .*\.(ico|svg|ttf|eot|woff)(.*) {
proxy_cache pnc;
proxy_cache_valid 200 304 1y;
proxy_cache_valid any 1m;
proxy_cache_lock on;
proxy_cache_lock_timeout 5s;
proxy_cache_use_stale updating error timeout invalid_header http_500 http_502;
expires 1y;
}浏览器的缓存存放在哪里,如何在浏览器中判断强制缓存是否生效?这就是下面我们要讲到的from disk cache和from memory cache。
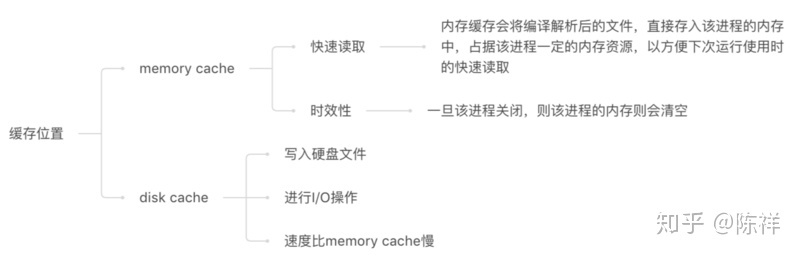
2.2、from disk cache和from memory cache
细心地同学在开发的时候应该注意到了Chrome的网络请求的Size会出现三种情况from disk cache(磁盘缓存)、from memory cache(内存缓存)、以及资源大小数值。

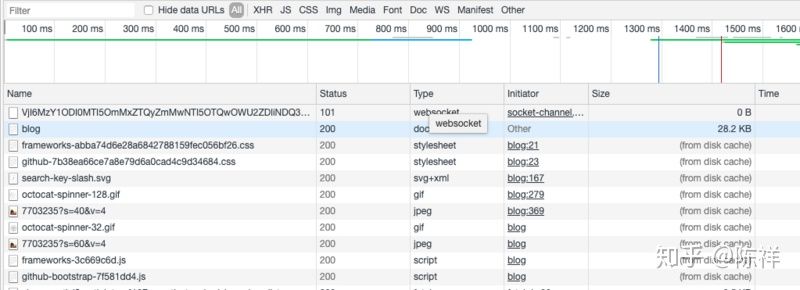
浏览器读取缓存的顺序为memory –> disk。 以访问https://github.com/xiangxingchen/blog为例 我们第一次访问时https://github.com/xiangxingchen/blog
关闭标签页,再此打开https://github.com/xiangxingchen/blog时
F5刷新时
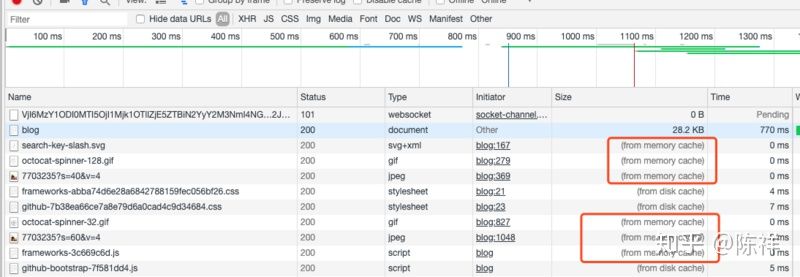
简单的对比一下
3、协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况:
- 协商缓存生效,返回304和Not Modified
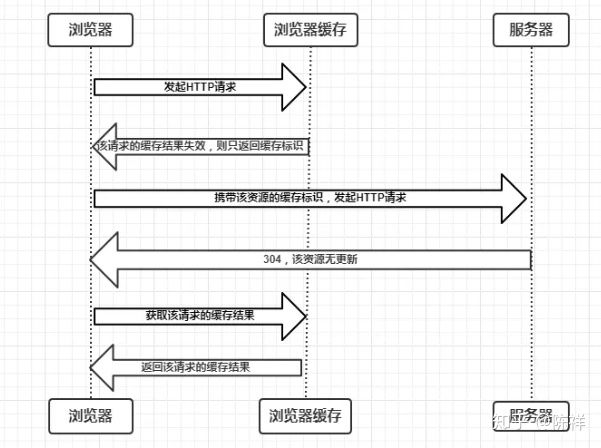
- 协商缓存失效,返回200和请求结果
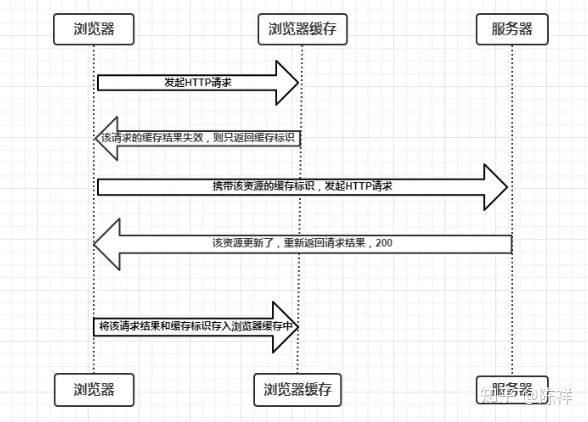
3.1、Last-Modified和If-Modified-Since
- 浏览器首先发送一个请求,让服务端在
response header中返回请求的资源上次更新时间,就是last-modified,浏览器会缓存下这个时间。 - 然后浏览器再下次请求中,
request header中带上if-modified-since:[保存的last-modified的值]。根据浏览器发送的修改时间和服务端的修改时间进行比对,一致的话代表资源没有改变,服务端返回正文为空的响应,让浏览器中缓存中读取资源,这就大大减小了请求的消耗。
由于last-modified依赖的是保存的绝对时间,还是会出现误差的情况:
- 保存的时间是以秒为单位的,1秒内多次修改是无法捕捉到的;
- 各机器读取到的时间不一致,就有出现误差的可能性。为了改善这个问题,提出了使用etag。
3.2、ETag和If-None-Match
etag是http协议提供的若干机制中的一种Web缓存验证机制,并且允许客户端进行缓存协商。生成etag常用的方法包括对资源内容使用抗碰撞散列函数,使用最近修改的时间戳的哈希值,甚至只是一个版本号。 和last-modified一样. - 浏览器会先发送一个请求得到etag的值,然后再下一次请求在request header中带上if-none-match:[保存的etag的值]。 - 通过发送的etag的值和服务端重新生成的etag的值进行比对,如果一致代表资源没有改变,服务端返回正文为空的响应,告诉浏览器从缓存中读取资源。
etag能够解决last-modified的一些缺点,但是etag每次服务端生成都需要进行读写操作,而last-modified只需要读取操作,从这方面来看,etag的消耗是更大的。
二者对比 - 精确度上:Etag要优于Last-Modified。 - 优先级上:服务器校验优先考虑Etag。 - 性能上:Etag要逊于Last-Modified
4、用户行为对浏览器缓存的影响
- 打开网页,地址栏输入地址: 查找
disk cache中是否有匹配。如有则使用;如没有则发送网络请求。 - 普通刷新 (F5):因为 TAB 并没有关闭,因此
memory cache是可用的,会被优先使用(如果匹配的话)。其次才是disk cache。 - 强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有
Cache-control:no-cache(为了兼容,还带了Pragma:no-cache),服务器直接返回 200 和最新内容。
5、总结
Cookie
Cookie 是小甜饼的意思。顾名思义,cookie 确实非常小,它的大小限制为4KB左右,是网景公司的前雇员 Lou Montulli 在1993年3月的发明。它的主要用途有保存登录信息,比如你登录某个网站市场可以看到“记住密码”,这通常就是通过在 Cookie 中存入一段辨别用户身份的数据来实现的。
sessionStorage
html5中的Web Storage包括了两种存储方式:sessionStorage和localStorage。
sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁。因此sessionStorage不是一种持久化的本地存储,仅仅是会话级别的存储。
localStorage
而localStorage用于持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的。
三者的异同
| 特性 | Cookie | localStorage | sessionStorage |
|---|---|---|---|
| 数据的生命期 | 可设置失效时间,默认是关闭浏览器后失效 | 除非被清除,否则永久保存 | 仅在当前会话下有效,关闭页面或浏览器后被清除 |
| 存放数据大小 | 4K左右 | 一般为5MB | 一般为5MB |
| 与服务器端通信 | 每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题 | 仅在客户端(即浏览器)中保存,不参与和服务器的通信 | 仅在客户端(即浏览器)中保存,不参与和服务器的通信 |
| 易用性 | 需要程序员自己封装,源生的Cookie接口不友好 | 源生接口可以接受,亦可再次封装来对Object和Array有更好的支持 | 源生接口可以接受,亦可再次封装来对Object和Array有更好的支持 |
localStorage使用代码如下:
//设置缓存,获取设置的缓存,键值对形式, name value
localStorage.getItem("key"); //获取键的值
localStorage.setItem("key", 1); //设置键的值
数据存储异常处理
try{
localStorage.setItem(key,value);
}catch(oException){
if(oException.name == 'QuotaExceededError'){
console.log('超出本地存储限额!');
//如果历史信息不重要了,可清空后再设置
localStorage.clear();
localStorage.setItem(key,value);
}
}
localStorage+cookie方案
/**
* 浏览器端缓存使用1.默认使用localStorage 2.不支持localStorage时,使用cookie
* @type {{isLocalStorage: _history.isLocalStorage, set: _history.set, read: _history.read, del: _history.del}}
* @private
*/
_history={
isLocalStorage:function(){
return window.localStorage?true:false;
},
set:function(key,value){ //设置缓存
if(this.isLocalStorage){
window.localStorage.setItem(key,value);
}else{
var expireDays = 365; //失效时间
var exDate=new Date();
exDate.setTime(exDate.getTime()+expireDays*24*60*60*1000);
document.cookie=key + "=" + escape(value)+";expires=" + exDate.toGMTString();
}
},
read : function(key){ //读取缓存
if(this.isLocalStorage){
return window.localStorage.getItem(key);
}else{
var arr,reg=new RegExp("(^| )"+key+"=([^;]*)(;|$)");
if(arr=document.cookie.match(reg)){
return unescape(arr[2]);
}else{
return null;
}
}
},
del : function(key){ //删除缓存
if(this.isLocalStorage){
localStorage.removeItem(key);
}else{
var exDate = new Date();
exDate.setTime(exDate.getTime() - 1);
var read_val=this.read(key);
if(read_val!=null) document.cookie= key + "="+read_val+";expires="+exDate.toGMTString();
}
}
};一、WebSQL
WebSQL是前端的一个独立模块,是web存储方式的一种,我们调试的时候会经常看到,只是一般很少使用。
兼容性:当前只有谷歌支持,ie和火狐均不支持。
我们对数据库的一般概念是后端才会跟数据库打交道,进行一些业务性的增删改查。而这里的数据库也不同于真正意义上的数据库。
主要方法:
- openDatabase:这个方法使用现有的数据库或者新建的数据库创建一个数据库对象。
- transaction:这个方法让我们能够控制一个事务,以及基于这种情况执行提交或者回滚。
- executeSql:这个方法用于执行实际的 SQL 查询。
-
openDatabase() 方法对应的五个参数说明:
- 数据库名称
- 版本号
- 描述文本
- 数据库大小
- 创建回调
transaction执行数据库操作,操作内容就是正常的数据库的增删改查。
executeSql是执行具体的sql,参数是1.sql语句(大写?),2.语句中的变量,3.执行后的回调,4.
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
db.transaction(function (tx) {
tx.executeSql('CREATE TABLE IF NOT EXISTS LOGS (id unique, log)');
tx.executeSql('INSERT INTO LOGS (id, log) VALUES (1, "菜鸟教程")');
tx.executeSql('INSERT INTO LOGS (id,log) VALUES (?, ?)', [e_id, e_log]); //使用外部变量,执行时会将变量数组中的值依次替换前边的问号位置
tx.executeSql('SELECT * FROM LOGS', [], function (tx, results) {
var len = results.rows.length, i; msg = "<p>查询记录条数: " + len + "</p>"; document.querySelector('#status').innerHTML += msg; for (i = 0; i < len; i++){ msg = "<p><b>" + results.rows.item(i).log + "</b></p>"; document.querySelector('#status').innerHTML += msg; }
}, null); //查询和回调
tx.executeSql('DELETE FROM LOGS WHERE id=1'); //删除
tx.executeSql('DELETE FROM LOGS WHERE id=?', [id]);
tx.executeSql('UPDATE LOGS SET log=\'www.w3cschool.cc\' WHERE id=2'); //更新
tx.executeSql('UPDATE LOGS SET log=\'www.w3cschool.cc\' WHERE id=?', [id]);
});基本操作与实际数据库操作基本一致。
最终的数据去向,我理解为只是做临时存储和大型网站的业务运行存储缓存的作用,页面刷新后该库就不存在了。而其本身与关系数据库的概念比较相似。
二、IndexedDB
诞生背景:
随着浏览器的功能不断增强,越来越多的网站开始考虑,将大量数据储存在客户端,这样可以减少从服务器获取数据,直接从本地获取数据。现有的浏览器数据储存方案,都不适合储存大量数据:Cookie 的大小不超过4KB,且每次请求都会发送回服务器;LocalStorage 在 2.5MB 到 10MB 之间(各家浏览器不同),而且不提供搜索功能,不能建立自定义的索引。所以,需要一种新的解决方案,这就是 IndexedDB 诞生的背景。
IndexedDB是浏览器提供的本地数据库, 允许储存大量数据,提供查找接口,还能建立索引。这些都是 LocalStorage 所不具备的。就数据库类型而言,IndexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库。诞生背景:
随着浏览器的功能不断增强,越来越多的网站开始考虑,将大量数据储存在客户端,这样可以减少从服务器获取数据,直接从本地获取数据。现有的浏览器数据储存方案,都不适合储存大量数据:Cookie 的大小不超过4KB,且每次请求都会发送回服务器;LocalStorage 在 2.5MB 到 10MB 之间(各家浏览器不同),而且不提供搜索功能,不能建立自定义的索引。所以,需要一种新的解决方案,这就是 IndexedDB 诞生的背景。
IndexedDB是浏览器提供的本地数据库, 允许储存大量数据,提供查找接口,还能建立索引。这些都是 LocalStorage 所不具备的。就数据库类型而言,IndexedDB 不属于关系型数据库(不支持 SQL 查询语句),更接近 NoSQL 数据库。
上面介绍的WebSQL也是一种在浏览器里存储数据的技术,跟IndexedDB不同的是,IndexedDB更像是一个NoSQL数据库,而WebSQL更像是关系型数据库,使用SQL查询数据。
代码判断当前浏览器是否支持indexed db
var db = {
version: 1, // important: only use whole numbers!
isSupport: function () {// support indexeddb or not
if (!window.indexedDB)
return false;
return true;
},
......
}IndexedDB 具有以下特点:
(1)键值对储存。 IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
(2)异步。 IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
(3)支持事务。 IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
(4)同源限制 IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
(5)储存空间大 IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
(6)支持二进制储存。 IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
IndexedDB的一些基本概念:
- 数据库:IDBDatabase 对象
- 对象仓库:IDBObjectStore 对象
- 索引: IDBIndex 对象
- 事务: IDBTransaction 对象
- 操作请求:IDBRequest 对象
- 指针: IDBCursor 对象
- 主键集合:IDBKeyRange 对象
(1)数据库。
数据库是一系列相关数据的容器。每个域名(严格的说,是协议 + 域名 + 端口)都可以新建任意多个数据库。
IndexedDB 数据库有版本的概念。同一个时刻,只能有一个版本的数据库存在。如果要修改数据库结构(新增或删除表、索引或者主键),只能通过升级数据库版本完成。
(2)对象仓库
每个数据库包含若干个对象仓库(object store)。它类似于关系型数据库的表格。
(3)数据记录
对象仓库保存的是数据记录。每条记录类似于关系型数据库的行,但是只有主键和数据体两部分。主键可以是数据记录里面的一个属性,也可以指定为一个递增的整数编号。
(4)索引
(5)事务
数据记录的读写和删改,都要通过事务完成。事务对象提供error、abort和complete三个事件,用来监听操作结果。
基本操作:
(1)打开数据库
使用 IndexedDB 的第一步是打开数据库,使用indexedDB.open()方法。
var request = window.indexedDB.open(databaseName, version);
这个方法接受两个参数,第一个参数是字符串,表示数据库的名字。如果指定的数据库不存在,就会新建数据库。第二个参数是整数,表示数据库的版本。如果省略,打开已有数据库时,默认为当前版本;新建数据库时,默认为1。
indexedDB.open()方法返回一个 IDBRequest 对象。这个对象通过三种事件error、success、upgradeneeded,处理打开数据库的`操作结果。
(2)新建数据库
eg:
var db;
var objectStore;
var request = window.indexedDB.open(databaseName, version);
request.onerror = function (event) {}
request.onsuccess = function (event) {
db = request.result//可以拿到数据库对象
}
//如果指定的版本号,大于数据库的实际版本号,就会发生数据库升级事件upgradeneeded
request.onupgradeneeded = function (event) {
db = event.target.result;
if (!db.objectStoreNames.contains('person')) {//判断是否存在
objectStore = db.createObjectStore('person', { keyPath: 'id' });
//自动生成主键db.createObjectStore(
// 'person',
// { autoIncrement: true }
//);
}
//新建索引,参数索引名称、索引所在的属性、配置对象
objectStore.createIndex('email', 'email', { unique: true });
}(3)新增数据
在以上操作的基础上,需要新建一个事务。新建时必须指定表格名称和操作模式("只读"或"读写")。新建事务以后,通过IDBTransaction.objectStore(name)方法,拿到 IDBObjectStore 对象,再通过表格对象的add()方法,向表格写入一条记录。
写入操作是一个异步操作,通过监听连接对象的success事件和error事件,了解是否写入成功。
eg:
function add() {
var request = db.transaction(['person'], 'readwrite')
.objectStore('person')
.add({ id: 1, name: '张三', age: 24, email: 'zhangsan@example.com' });
request.onsuccess = function (event) {
console.log('数据写入成功');
};
request.onerror = function (event) {
console.log('数据写入失败');
}
}
add();(4)读取数据
objectStore.get()方法用于读取数据,参数是主键的值。
eg:
function read() {
var transaction = db.transaction(['person']);
var objectStore = transaction.objectStore('person');
var request = objectStore.get(1);
request.onerror = function(event) {
console.log('事务失败');
};
request.onsuccess = function( event) {
if (request.result) {
console.log('Name: ' + request.result.name);
console.log('Age: ' + request.result.age);
console.log('Email: ' + request.result.email);
} else {
console.log('未获得数据记录');
}
};
}
read();(5)遍历数据
遍历数据表格的所有记录,要使用指针对象 IDBCursor。openCursor()方法是一个异步操作,所以要监听success事件。
function readAll() {
var objectStore = db.transaction('person').objectStore('person');
objectStore.openCursor().onsuccess = function (event) {
var cursor = event.target.result;
if (cursor) {
console.log('Id: ' + cursor.key);
console.log('Name: ' + cursor.value.name);
console.log('Age: ' + cursor.value.age);
console.log('Email: ' + cursor.value.email);
cursor.continue();
} else {
console.log('没有更多数据了!');
}
};
}
readAll();(6)数据更新
IDBObject.put()方法。
function update() {
var request = db.transaction(['person'], 'readwrite')
.objectStore('person')
.put({ id: 1, name: '李四', age: 35, email: 'lisi@example.com' });
request.onsuccess = function (event) {
console.log('数据更新成功');
};
request.onerror = function (event) {
console.log('数据更新失败');
}
}
update();(7)数据删除
IDBObjectStore.delete()方法用于删除记录。
function remove() {
var request = db.transaction(['person'], 'readwrite')
.objectStore('person')
.delete(1);
request.onsuccess = function (event) {
console.log('数据删除成功');
};
}
remove();(8)索引的使用
添加索引后可以使用索引查询数据
var transaction = db.transaction(['person'], 'readonly');
var store = transaction.objectStore('person');
var index = store.index('name');
var request = index.get('李四');
request.onsuccess = function (e) {
var result = e.target.result;
if (result) {
// ...
} else {
// ...
}
}三、IndexedDB vs Web SQL
WebSQL也是一种在浏览器里存储数据的技术,跟IndexedDB不同的是,IndexedDB更像是一个NoSQL数据库,而WebSQL更像是关系型数据库,使用SQL查询数据。W3C已经不再支持webSql这种技术。因为不再支持上面也大致分析了其用法,也就不再赘诉。















 810
810











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









