









所有需要的文件都在这:hadoop 提取码:j6zx
1.下载eclipse(或者用我传的压缩包)
下载解压后将hadoop-eclipse-plugin-2.6.0.jar放在eclipse目录的plugins目录下
2.下载hadoop-2.6.0,并解压
3.将下载下来的bin目录的路径设置一个环境变量
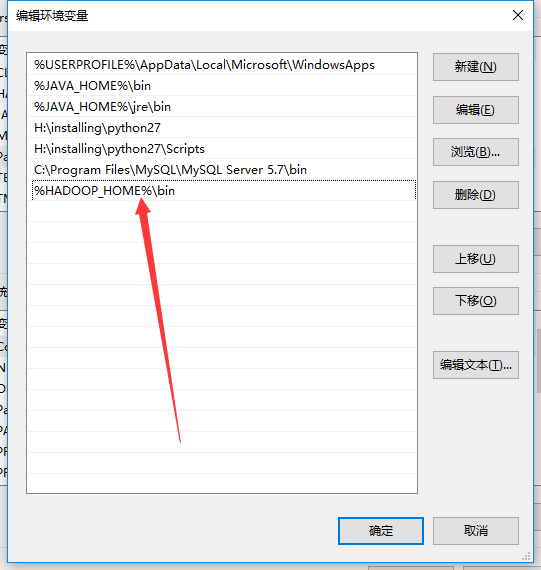
新建一个环境变量名为HADOOP_HOME,值为该bin目录的路径

并在path环境变量后面加上%HADOOP_HOME%\bin
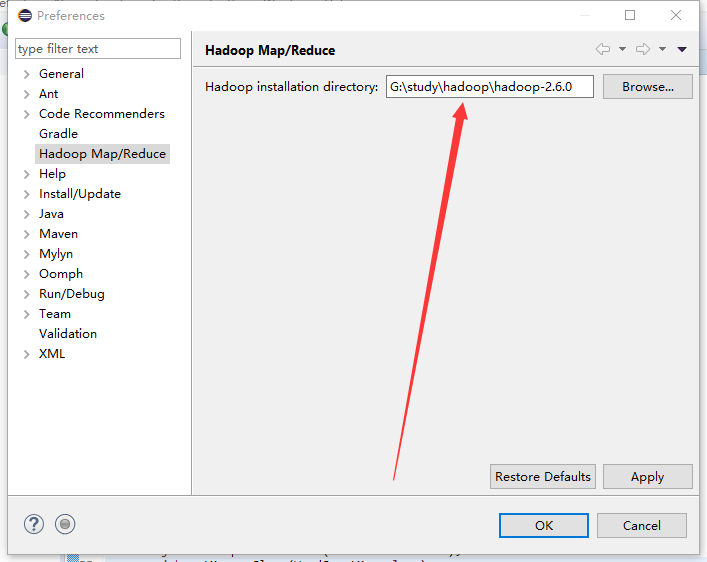
4.打开eclipse,windows->perference,选择Hadoop Map/Reduce,选择你解压hadoop-2.6.0的路径,保存。
5.window->show view->other->MapReduce Tools->点击Map/Reduce Location。
开始配置你的hadoop位置。在这儿右键->New Hadoop location 进入一下页面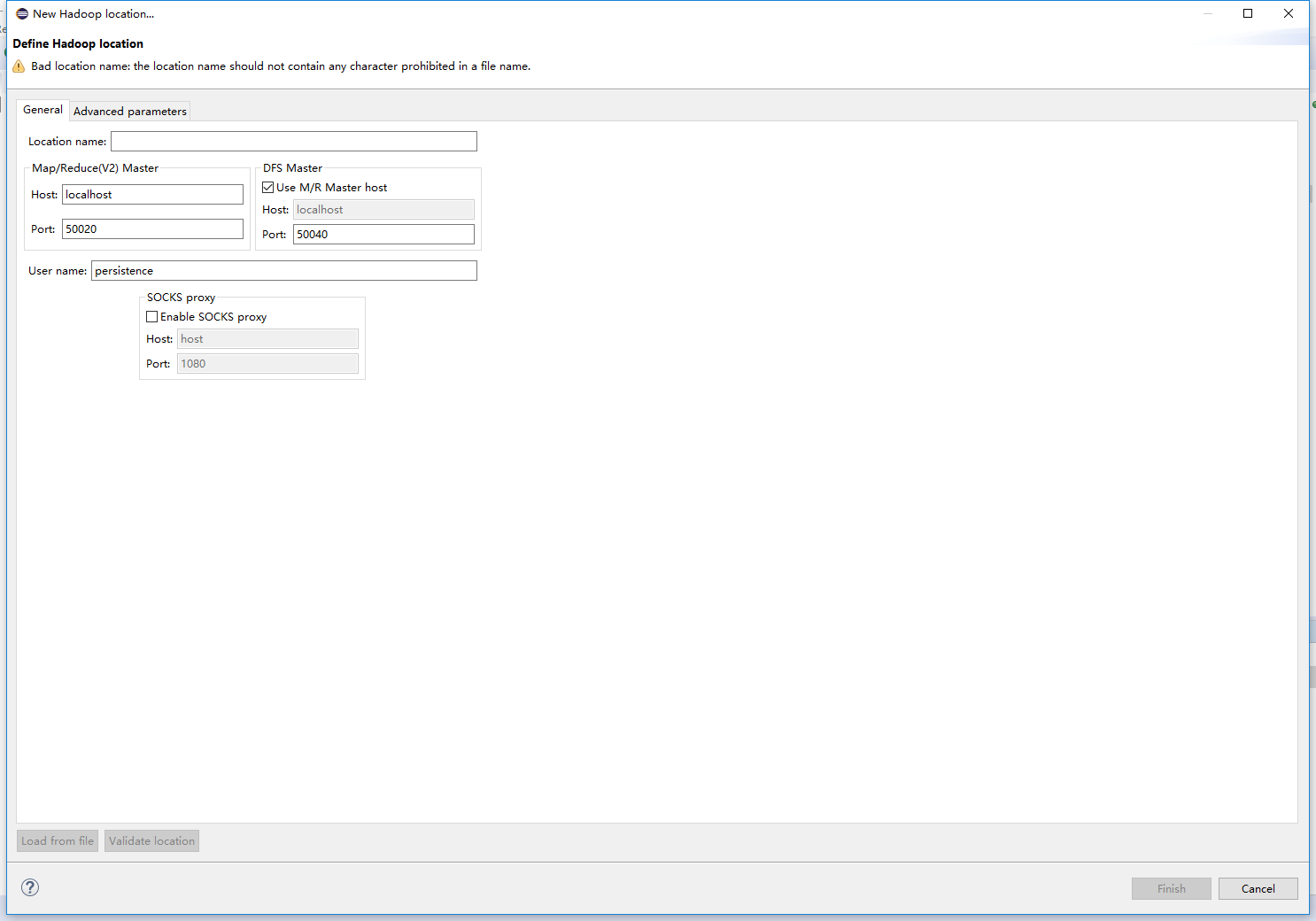
Location name随意填写,Host是你的集群中master的ip端口号是你在配置文件中配置的端口号。配置好后,你就可以看见你的hdfs
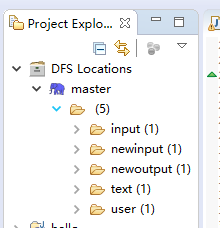
6.开始使用hadoop进行wordcount
新建project,建立Map/Reduce Project。建立好后,会默认导入很多jar包
在src目录下新建一个包,并在包中建立一个类,名字WordCount,代码如下
package WordCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("/newinput"));
FileOutputFormat.setOutputPath(job, new Path("/newoutput"));
job.waitForCompletion(true);
}
}这儿你需要把你的hadoop的配置文件里面的core-site.xml、hdfs-site.xml和log4j.properties复制过来放在你的 src目录下。然后就可以运行你的程序了。这儿需要注意的是,你需要在hdfs根目录下建立一个newinput文件夹,并把你需要进行单词统计的文件放在newinput这个目录下。
这样就可以成功运行WordCount程序了。
over,thanks。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









