






第一单元总结
第一单元总体来说没有想象中那样上强度,除去第一次作业在设计架构、平地起高楼有些难搞,之后两次作业还是比较顺利的。
得益于一个还算不错的架构设计,在迭代过程中我也没有遇到什么迫切需要重构的地方。计算过程中能够自动实现表达式的合并化简。唯一出现的bug也是因为为了卷性能分而忘记加括号(早知道还是不卷)。
在第一单元作业中,我对词法分析、递归下降有了一定的认识。尤其是递归下降,给了我和以往编程中完全不一样的体验,实在是太好用了。
第一单元的任务为完成一个表达式化简。相较于其他同学的解析表达式为语法树-进行计算的方式,我采用了纯粹的递归下降,直接运算办法。通过递归下降的办法,可以不用管后缀中缀的树形式,而是直接想运算单元带入计算。计算,就是解析的一个部分。
架构设计
OO之名早已远扬,在上课前我就对一些往年博客进行了遍历,大致了解了第一单元表达式计算的要求和基本架构,制定了一个具有足够扩展性的架构。在实际的作业中,我并没对这套架构做出太大的调整,在一些时候还享受到了提前预留接口的惊喜。
我在第三次作业时对代码进行了一次重构,可以下文的第三次作业分析。
我的架构其实用一个数学公式即可以概括:
Unit
=
a
x
b
1
y
b
2
z
b
3
exp
(
Expr
)
\text{Unit} = ax^{b_1}y^{b_2}z^{b_3} \text{exp}(\text{Expr})
Unit=axb1yb2zb3exp(Expr)
相应的类图为(仅有Definer是在第二次作业新添加的,其余无修改):
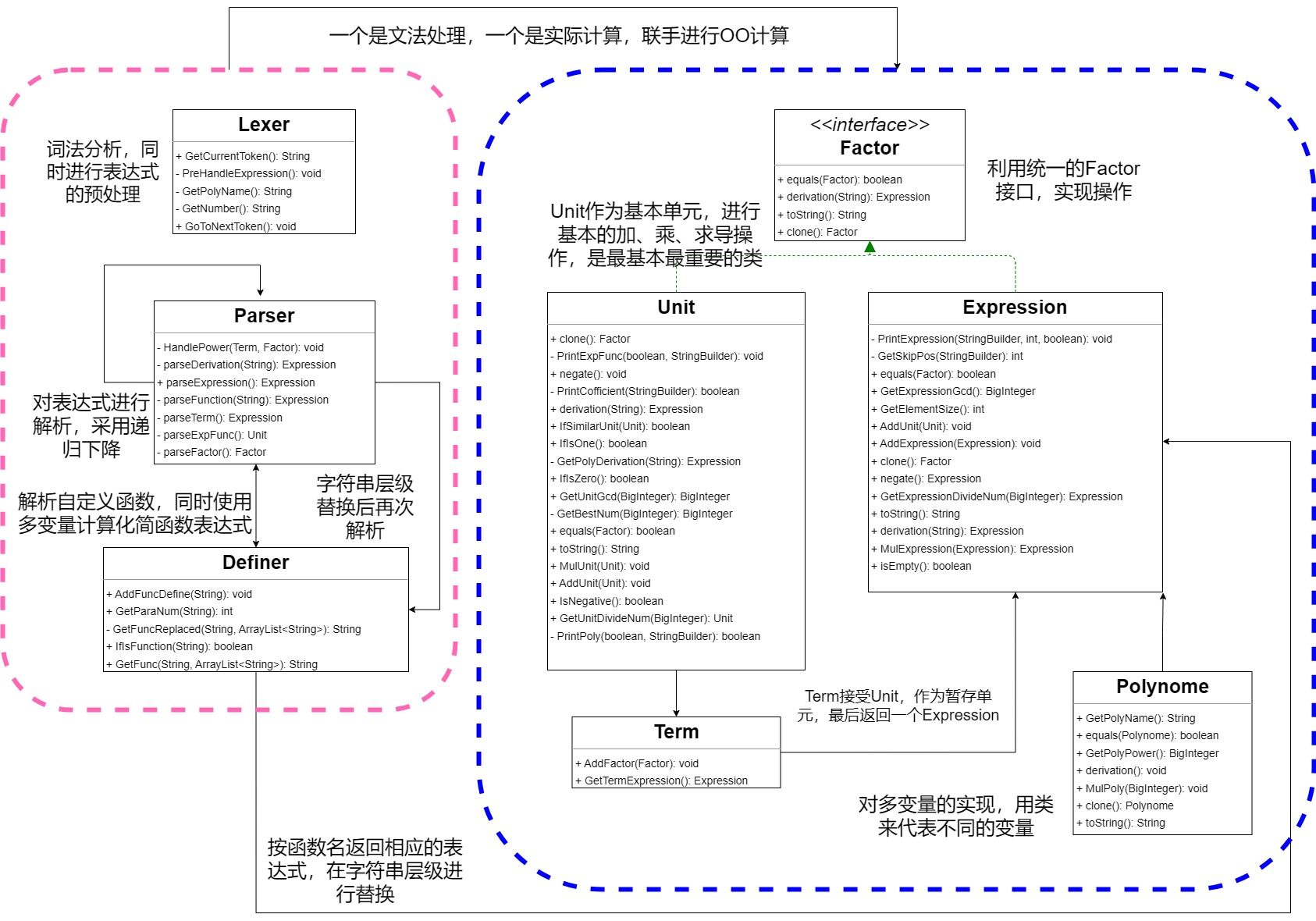
第一次作业
第一次作业只要求实现简单的加减乘操作,且括号深度也较浅。当时就对后续两次作业中可能的增量开发方向进行了估计,在第一次作业的基础上实现了多变量计算和多层括号的问题。
我所采用的架构是在训练中给出的Expression-Term-Factor的分类方式。
程序上的表示
第一单元的要求是完成一个表达式程序的计算,其核心在于如何采用合适的架构将变量、函数在程序中进行表示。并且,由于可以预见到后两次作业会加入多变量计算、对于函数(包括三角函数、自定义函数)的支持,我觉得一下几个问题是应该思考的:
- 怎么统一数和变量的计算
- 怎么预留出扩展性,让函数能够较为方便地接入
- 在递归下降角度,怎么从字符串中解析出对应的因子
自然的,会想到使用多项式进行表示,即采用 ∑ C x a 1 y a 2 ∗ f ( x , y , z , . . . ) \sum C x^{a_1} y^{a_2}*f(x,y,z,...) ∑Cxa1ya2∗f(x,y,z,...)的表示方式来对表达式进行建模。即:
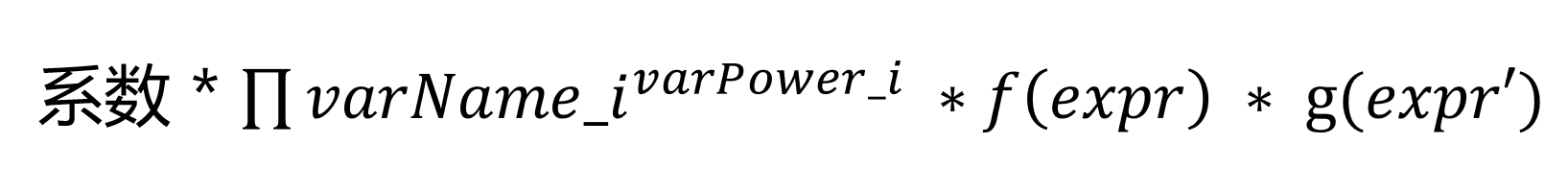
这样的表示有几个好处:
- 将数和变量的计算统一了,比如1可以表示为
1
=
1
∗
x
0
1=1*x^0
1=1∗x0,
x
2
x^2
x2可以表示为
1
∗
x
2
1*x^2
1∗x2,数可以看作一种特殊的系数单项式。并且由于数的唯一位置是系数,不会出现
x*2y*3z^2这种数字前一个后一个的混乱局面; - 预留出了扩展的接口,变量再多都不怕,可以向
TreeMap中肆无忌惮地添加,叫abcd都可。并且以变量名为键后,不会由x*y*x^2的情况; - 对于可以相加的单项式,如
x+2x,由以变量名做红黑树的键的特性,可以写一个比较方面的有序比较的函数来进行比较,且这个比较和变量的位置无关,即 x ∗ y = = y ∗ x x*y==y*x x∗y==y∗x。这样就能判断除系数外的部分是否相等,将表达式较为方便地化简,卷一卷性能分;
计算于Term的矛盾
- 在进行解析时,每解析到一个数字/变量(后文用单元Unit统称),就将其加入到当前的Term中,调用
AddFactor,若有Unit则将其合并; - 解析到加减符号
+-,则将Term加入Expr中,调用AddTerm,判断是否是除系数外都相同的单项式,进行化简。 - 在这些加入过程中,编写相应的接口实现自动化简,这样能够保证计算过程中表达式的简洁性。
但是,这个过程并没有解决括号展开的过程,还需要对表达式进行化简。
为什么不是对项进行化简:
为了对括号进行展开,需要将Term term1 = x*(x+1)这样的形式进行展开。但是显然的,展开的结果是一个多项式,即一个表达式,应该用一个Expr来表示。
对此,我的策略是统一为Expr的计算,在合适的位置对表达式进行自动的化简,将Term上升为Expr。以此来保证表达式在递归计算过程中的简洁性,保证计算的速度。
如果在表达式计算中,需要在解析完成后手动调用计算,我觉得这是不方便的。这样,一方面会让最后的计算函数面对一个巨大的表达式(后缀/中缀),计算不方面;另一方面,这样将Expr、Term等对象仅作为了数据存储单元,没有很好地用到相应的行为逻辑,实际上也应该是有的。
面向什么样的接口?我采用了添加时自动化简、在解析时在处理表达式时返回化简后的结果,但是我依然感觉这样不太优雅,对Unit的实现没有很好地利用,Factor由Unit和Expr继承仅起到了表示表达式的数据存储功能,自我感觉没有很好地”面向对象“。
在之后的第三次作业中,我进行了一次重构,消除了这个问题。
结构分析
第一次作业共有8个类。

相关方法的复杂度如下:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| factor.Expression.toString() | 18.0 | 6.0 | 12.0 | 13.0 |
| Lexer.PreHandleExpression() | 4.0 | 1.0 | 6.0 | 7.0 |
| factor.Unit.toString() | 19.0 | 2.0 | 6.0 | 9.0 |
| factor.Expression.AddTerm(Term, boolean) | 5.0 | 3.0 | 5.0 | 5.0 |
| factor.Term.AddFactor(Factor) | 9.0 | 4.0 | 5.0 | 5.0 |
| factor.Term.TermSimplify() | 9.0 | 6.0 | 5.0 | 6.0 |
| Lexer.next() | 5.0 | 2.0 | 4.0 | 10.0 |
| Parser.HandlePower(Term, Factor) | 8.0 | 1.0 | 4.0 | 4.0 |
| factor.Unit.MulUnit(Unit) | 5.0 | 1.0 | 4.0 | 4.0 |
| Lexer.GetNumber() | 2.0 | 1.0 | 3.0 | 3.0 |
| Lexer.GetPolyName() | 2.0 | 1.0 | 3.0 | 3.0 |
| Total | 120.0 | 72.0 | 115.0 | 130.0 |
| Average | 2.5531914893617023 | 1.5319148936170213 | 2.4468085106382977 | 2.765957446808511 |
主要的复杂度来源来自toString方法,由于涉及到相应的输出优化,同时,在HW1我还没有对相应方法进行拆分,导致了相应逻辑较为复杂。
相关类的复杂度:
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| factor.Expression | 3.25 | 10.0 | 26.0 |
| factor.Polynome | 1.2857142857142858 | 3.0 | 9.0 |
| factor.Term | 2.4 | 6.0 | 24.0 |
| factor.Unit | 2.5 | 8.0 | 25.0 |
| Lexer | 2.3333333333333335 | 5.0 | 14.0 |
| MainClass | 1.0 | 1.0 | 1.0 |
| Parser | 2.4 | 4.0 | 12.0 |
| Total | 111.0 | ||
| Average | 2.3617021276595747 | 5.285714285714286 | 15.857142857142858 |
只有Expression类的复杂度是超标的,其原因在于第一次作业中Expression承担了部分Term的功能,较为复杂。
第二次作业
在第二次作业中,由于客观上的其他压力,尽管已经认识到了Term类设计的不合理,架构中一些设计的冗余,但是当时我并没有足够的时间进行架构调整,在第一次作业基础上增加了Definer类来对自定义函数进行处理。
对于Definer类,我采用了重新调用Paser的方法,利用可以进行多变量计算的特性,将函数表达式进行了计算化简。并对化简后的表达式进行了字符串层级的替换,建立了函数名-表达式的Map,得到了对函数的解析。
对于新增加的Exp指数函数,我的处理方式是对基本单元Unit进行修改,从原先的 a ∗ x b a*x^b a∗xb更改为了 a ∗ x b ∗ e x p ( E x p r ) a*x^b*exp(Expr) a∗xb∗exp(Expr)的形式,在Unit类中引入了一个Expression类作为指数函数的内容。
在客观上,这样处理增加了类的耦合性,使得Unit-Expression的调用关系进行了一种互相调用的关系,增加了运算的复杂度。这也导致了在第三次作业中过于频繁的自动化简造成了多Exp嵌套下的TLE。
结构分析
第二次作业共有9个类。

可以看到,本次作业中代码行数有了较大的膨胀,主要来源于支持指数后Unit和Expression类的膨胀。
相关方法的复杂度:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Unit.PrintExpFunc(boolean, StringBuilder) | 11.0 | 1.0 | 6.0 | 8.0 |
| Expression.equals(Factor) | 10.0 | 7.0 | 3.0 | 7.0 |
| Term.AddFactor(Factor) | 9.0 | 4.0 | 5.0 | 5.0 |
| Expression.PrintExpression(StringBuilder, int, boolean) | 8.0 | 3.0 | 6.0 | 7.0 |
| Parser.HandlePower(Term, Factor) | 8.0 | 1.0 | 4.0 | 4.0 |
| Expression.GetSkipPos(StringBuilder) | 7.0 | 4.0 | 5.0 | 5.0 |
| Parser.parseFactor() | 7.0 | 5.0 | 5.0 | 5.0 |
| Definer.GetFunc(String, ArrayList) | 6.0 | 1.0 | 3.0 | 4.0 |
| Definer.GetFuncReplaced(String, ArrayList) | 6.0 | 1.0 | 3.0 | 4.0 |
| Lexer.PreHandleExpression() | 6.0 | 1.0 | 7.0 | 9.0 |
| Term.TermSimplify() | 6.0 | 5.0 | 4.0 | 5.0 |
| Unit.IfSameUnit(Unit) | 6.0 | 4.0 | 4.0 | 6.0 |
| Unit.PrintPoly(boolean, StringBuilder) | 6.0 | 1.0 | 3.0 | 4.0 |
| Definer.AddFuncDefine(String) | 5.0 | 4.0 | 4.0 | 5.0 |
| Expression.AddTerm(Term, boolean) | 5.0 | 3.0 | 5.0 | 5.0 |
| Lexer.GoToNextToken() | 5.0 | 2.0 | 4.0 | 11.0 |
| Unit.GetBestNum(BigInteger) | 5.0 | 3.0 | 2.0 | 4.0 |
| Unit.MulUnit(Unit) | 5.0 | 2.0 | 4.0 | 4.0 |
| Unit.PrintCofficient(StringBuilder) | 5.0 | 1.0 | 3.0 | 4.0 |
| Unit.GetUnitGcd(BigInteger) | 4.0 | 2.0 | 3.0 | 3.0 |
| Unit.toString() | 4.0 | 2.0 | 3.0 | 4.0 |
| Expression.MulExpr(Expression) | 3.0 | 1.0 | 3.0 | 3.0 |
| Total | 172.0 | 114.0 | 166.0 | 196.0 |
| Average | 2.388888888888889 | 1.5833333333333333 | 2.3055555555555554 | 2.7222222222222223 |
相关类的复杂度:
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Definer | 2.5 | 4.0 | 15.0 |
| Expression | 2.7857142857142856 | 7.0 | 39.0 |
| Lexer | 2.6666666666666665 | 5.0 | 16.0 |
| MainClass | 2.0 | 2.0 | 2.0 |
| Parser | 2.4285714285714284 | 5.0 | 17.0 |
| Polynome | 1.2857142857142858 | 3.0 | 9.0 |
| Term | 2.076923076923077 | 5.0 | 27.0 |
| Unit | 2.4444444444444446 | 6.0 | 44.0 |
| Total | 169.0 | ||
| Average | 2.3472222222222223 | 4.625 | 21.125 |
在对toString方法进行拆分后,复杂度大大降低。但是,为了支持对exp()的合并,要求一个Expression的equals()方法。我并没有采用重写hashCode的方法,而是采用了遍历两个Expression的hashMap,在其中再调用子元素的equals()算法,导致了复杂度的提高。
第三次作业
在第三次作业中,我进行了一次重构,对Term类进行了全部重写,优化了部分Expression和Unit类中的接口设计,减法了计算中的化简操作,使代码的简洁性、易读性得到了较大的提升。同时我还统一了表达式解析中的计算操作,将化简合并过程和解析过程合并,自动达到了合并的效果。
求导
在刚开始写作本次作业时,我的架构和并没有产生太大的变化,依旧是采用了Expr-Term-Factor这样的基础架构,在原本单项式的基础上添加为了
Unit
=
a
x
b
exp
(
e
x
p
r
)
\text{Unit}=ax^b\text{exp}(expr)
Unit=axbexp(expr)。
分析一下求导的需求,如果你也采用了这种类多项式结构,那么对Expr的求导最后的抓手都是这样的一个个Unit,完成对Unit的求导即可。
从数学上表示,即为: dx ( Unit ) = a ( b x b − 1 + dx ( Expr ) ) exp ∗ ( Expr ) \text{dx}(\text{Unit})=a(bx^{b-1}+\text{dx}(\text{Expr}))\text{exp}*(\text{Expr}) dx(Unit)=a(bxb−1+dx(Expr))exp∗(Expr),落回到程序上,即分别解决 x b x^b xb多项式求导和指数exp的求导,再加起来。
完成了这样对基本因子Unit的求导,剩下的部分就可以开始愉快地进行迭代调用了,对exp括号中的表达式(我存的是表达式Expr)调用求导函数,解析到Term时向下继续调用Term的求导函数,进而最后落到对Unit的求导。这样的递归调用总有一个尽头,也就是最后的一个个Unit组成的多项式。
总结一下流程,也就是:
- 遇到dx,调用对Expr的求导函数,进行
parseExpression.derivation(),该函数返回一个Expr,即求导后的结果。 - 在Expr的求导函数中,由于Expr由一个个Term相加而成,对每个Term调用
term.derivation()函数,该函数返回的依然是一个Expr(单项式的求导由于exp的存在会使得结果可能是Expr)。 - 在Term的求导函数中,调用对Unit的求导函数,返回的是Expr,由于存在
exp(Expr)这种存在,在对exp求导时,会返回到1调用Expr的求导函数,直至递归结束。
对优化的修改
在前两次的作业中,我的程序都是解析-化简一体的,即在解析过程中自动对表达式进行化简,遇到特殊的,如Exp的拆分,则在toString方法中单独处理一下。这样的涉及带来了如下的问题:
- 为了取出Expression中的
0项,我愚蠢地使用了toString方法来进行判断,这样在Exp多层嵌套的情景下会导致递归深度极高,程序运行时间极长 - 因为思维上的偷懒,我在每一次Expression运算完毕后都会进行一次1中的清除,进一步加大了运算的消耗,造成了TLE
为此,在最后的程序中,我重新梳理了表达式化简的逻辑,在保持原先的自动化简不变的基础上,对于清楚的时机进行了调整,只在AddExpression这一环节进行判断,并且不进行额外的循环。
进一步的,我也书写了相关的方法,对一些特殊情景,如判断是否为0,1乘其他的情况进行了判断。尽管在某种程度上造成了代码复杂度的上升,却也使得代码的运行时间大大降低,总体来看是值得的。
关于重构
在写代码时,我一直在思考Term这一个结构的作用是什么。Factor可以视作表达式的基本因子,作为接口由Expression和Unit分别实现,在表达式的形式上也满足如 Expr = ∑ Unit ∗ Expr \text{Expr}=\sum\text{Unit}*\text{Expr} Expr=∑Unit∗Expr的形式。
那么Term呢?
Term是由表达式中加减符号分隔的一个个元素,但是这种分割注定是暂时的:最后的化简需要将括号全部都打开,能合并的都合并。这时候加减符号分割的就只是一个个基本元素Unit了。再用Term去体现代码的结构,那么就是 Expr = ∑ Term , Term = Unit \text{Expr}=\sum\text{Term},\text{Term}=\text{Unit} Expr=∑Term,Term=Unit,即化简后每个Term中只有唯一的一个Unit,没有先前的Expr,唯一的Factor就是Unit。
这样的操作使得我的代码在这样的情景下十分丑陋:表达式化简结束后,在转换为字符串环节,此时Term中的factorList只有Unit而为Expr(化简都拆出去了),为了取出这唯一的Unit,甚至需要做指针的类型转换!
Unit thisUnit = (Unit) this.factorList.get(0);
Unit otherUnit = (Unit) otherTerm.factorList.get(0);
到做HW3时,我开始感觉Term这样一个类,保持factorList实际上是没有必要的,可以维持一个暂时的Expr,解析到别的Factor时直接乘进去,并不需要严格地按照Term分隔表达式。
至此可以得到结论:Term只是在解析表达式的中间过程中一个暂时的数据形式,在最后的阶段完全可以用 Expr = ∑ Unit \text{Expr}=\sum\text{Unit} Expr=∑Unit的形式来表现。
于是,在这个结论的基础上,我进行了如下的重构:
-
删除了Term的数据存储单元,即Term不再有数据(有也只是在解析表达式时暂时存一下),转而变为了解析时的一个行为对象、一个方法集合。
-
在调用
parseTerm函数时,不再返回原先的Term类,而是直接返回Expr,具体的流程为:parseTerm开始后,保留一个暂时的新的Expr,直接与后续解析到的Factor相乘,不再暂存存储相乘Factor的list -
至此,Term不再是一个存储数据的类,而变成了一个解析由
*相连的因子的方法集合
我认为,这样的好处有:
- 数据的结构更为灵活。使得表达式 Polynome = ∑ Molynome \text{Polynome}=\sum\text{Molynome} Polynome=∑Molynome的形式得到了统一。并且唯二的数据单元就是Unit和Expr,都实现了Factor的接口,这样操作使得类的统一性更高。同质化的操作可以直接在接口中进行定义。
- 尽管直接进行了相乘,但是运行速度却没有影响,一方面最后的化简总归要这样展开,区别就是集中展开还是解析到就乘进去;另一方面由于及时化简,不会造成项挤压太多造成运算缓慢的问题。
可能的优化方向
当然,重构不是完美的。目前我的计算方法都继承在相应的类中,没有进行拆分。我也设想过,如果后续对Expression的运算操作继续增加,那么我的类会变得即为庞大。需要拆分出一个方法类。
目前,我的计算是将解析-化简一体,在表达式的乘、加过程中,自动搜索是否能进行系数相加,否则才作为新项加入,保证了应合尽合。
求导的算法也集成在了Factor类中,由Unit类和Expression类分别实现。未来如果有必要,也可以考虑对这些方法进行拆分。
结构分析
重构后代码的行数、复杂度都大大降低。第三次作业没有增加新的类。

相关方法的复杂度:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expression.equals(Factor) | 10.0 | 7.0 | 3.0 | 7.0 |
| Parser.parseFactor() | 9.0 | 6.0 | 7.0 | 7.0 |
| Expression.GetSkipPos(StringBuilder) | 10.0 | 5.0 | 5.0 | 5.0 |
| Definer.AddFuncDefine(String) | 5.0 | 4.0 | 4.0 | 5.0 |
| Unit.IfSimilarUnit(Unit) | 6.0 | 4.0 | 4.0 | 6.0 |
| Expression.AddUnit(Unit) | 8.0 | 3.0 | 6.0 | 6.0 |
| Expression.MulExpression(Expression) | 5.0 | 3.0 | 4.0 | 4.0 |
| Expression.PrintExpression(StringBuilder, int, boolean) | 8.0 | 3.0 | 6.0 | 7.0 |
| Polynome.toString() | 3.0 | 3.0 | 2.0 | 3.0 |
| Unit.GetBestNum(BigInteger) | 7.0 | 3.0 | 4.0 | 5.0 |
| Expression.GetExpressionGcd() | 2.0 | 2.0 | 2.0 | 3.0 |
| Total | 171.0 | 108.0 | 164.0 | 193.0 |
| Average | 2.442857142857143 | 1.542857142857143 | 2.342857142857143 | 2.757142857142857 |
相关类的复杂度:
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Definer | 2.5 | 4.0 | 15.0 |
| Expression | 2.6875 | 7.0 | 43.0 |
| Lexer | 2.6666666666666665 | 5.0 | 16.0 |
| MainClass | 2.0 | 2.0 | 2.0 |
| Parser | 2.5 | 6.0 | 20.0 |
| Polynome | 1.25 | 3.0 | 10.0 |
| Term | 1.3333333333333333 | 2.0 | 4.0 |
| Unit | 2.409090909090909 | 6.0 | 53.0 |
| Total | 163.0 | ||
| Average | 2.3285714285714287 | 4.375 | 20.375 |
可以看出重构之后复杂度大大降低。
树与递归下降
怎么计算表达式,在数据结构课上使用了后缀表达式的表达式树计算方法,这也成为了作业一开始时的思维定式:怎么通过java,将表达式解析为一棵树。
然后尴尬的问题出现了:我不会使用java建树。尽管java中国所有变量天然的是引用,但是如果按照C语言那样去设计,采用一个形如Node left,right;的实现方式,恐怖实在是过于丑陋了。
在给出了训练代码和往年博客中,也有采用Node作为计算节点的方式,一个节点同时存储了数据和计算类型,这也是一种对于树的抽象,采用了节点元素对表达式进行建模。
但是,为什么一定要用树呢?
在数据结构的学习中,采用后缀表达式来建树主要是为了解决括号嵌套的问题,利用后缀这一树的遍历形式解决了无法预知括号中内容的问题,从算符的角度建立了树的抽象。
但是,基本上人人采用的递归下降却并不是树的表现形式。递归下降使用在函数调用过程中OS建立的函数栈代替了手动建立的节点栈,通过递归下降这一做法,完全可以在解析到括号时直接调用parseExpression(),等到程序递归计算后得到结果,而不用去管具体的内容是什么。
这样操作,有一种挥手自兹去的美感:不用关注具体的实现是什么样的,OS会自动帮助你完成,只需要完成相关的函数逻辑设计。
因此,这样设计可以不用显式地实现节点这一树的基础,而是可以将程序的基础变化为表达式中的最小单元Unit,将建树的操作交给OS,只需要完成架构设计,便可以让递归这一操作完成任务。
因而在我的架构设计中,完全没有节点等元素,始终贯彻着Expression-Term-Unit的三层分隔(这样的分隔是从文法角度出发的),将加、减、乘、求导这几个操作变得符合人的计算逻辑,让递归完成了建树的操作。
如无必要,勿增实体
在第三次作业完成后,我完成了一次重构,大幅度精简了代码,并优化了部分类的设计。
现在,我的代码有8个类,总840行,实际代码689行的数据量 ,根据互测和其他同学代码的对比,都是最简洁的之一。这样的简洁并没有以丧失灵活性作为代价,始终保证了代码的灵活和方便。
类的数量
记得在Pre课程时,我就问助教,担心类的数量太多怎么办。在面向对象设计中,继承和多态给予了操作的灵活性,却也让我开始担心操作中接口使用不当带来的错误。于是在类的增加上,我一直处于一个保守的态度:如无必要,勿增实体。
荣老师多次在课堂上强调了应该维持一个单独的输入输出类,本单元的作业输入输出还不复杂,我也没有进行这样的操作。如果有进一步的迭代,输入逻辑变得较为复杂,那么我可能也会考虑拆分一个输入输出类IOhandle,并将表达式的预处理从Lexer类中转移到这个输入输出类中。
其次,为了维持类的统一性,我并由和大多数同学一样建立了Num类、Variable类,而是考虑将其合并为了一个基本单元Unit(数学形式在上文),这样的考虑是处于合并化简中的统一性,如果输出x*2*x*2形式的表达式,多个类会带来处理上类的类型判断的复杂性,而一个确定的基本单元能保证计算的统一性。
Unit
1
∗
Unit
2
=
a
1
x
b
1
y
b
2
exp
(
Expr
1
)
∗
a
2
x
c
1
y
c
2
exp
(
Expr
2
)
=
a
1
∗
a
2
∗
x
b
1
+
c
1
y
b
2
+
c
2
exp
(
Expr
1
+
Expr
2
)
\text{Unit}_1*\text{Unit}_2 = \\ a_1x^{b_1}y^{b2}\text{exp}({\text{Expr}_1}) * a_2x^{c_1}y^{c2}\text{exp}({\text{Expr}_2}) \\ = a_1*a_2*x^{b_1+c_1}y^{b2+c_2}\text{exp}({\text{Expr}_1} + \text{Expr}_2)
Unit1∗Unit2=a1xb1yb2exp(Expr1)∗a2xc1yc2exp(Expr2)=a1∗a2∗xb1+c1yb2+c2exp(Expr1+Expr2)
这样的操作将几个基本元素都统一了,降低了表达式合并化简中的难度。
预处理
我的代码较为减法,还有一个方面是我用较为全面的预处理代替了很多事情。
比如我的代码实际上并不支持负数,只支持减法;不支持直接解析括号,而是在前面添加1*来作为折中方案。
我在Lexer中有一个巨大的预处理方法,如果后续还要迭代的话,我可能会将其拆分到输入输出处理中一起处理。
private void PreHandleExpression() {
exprIn = exprIn.replaceAll("\\s+", "");
while (exprIn.contains("--") || exprIn.contains("++") ||
exprIn.contains("+-") || exprIn.contains("-+")) {
exprIn = exprIn.replace("--", "+");
exprIn = exprIn.replace("++", "+");
exprIn = exprIn.replace("+-", "-");
exprIn = exprIn.replace("-+", "-");
}
exprIn = exprIn.replace("^+", "^");
exprIn = exprIn.replace("(-", "(0-");
exprIn = exprIn.replace("(+", "(0+");
exprIn = exprIn.replace("-", "-1*");
exprIn = exprIn.replace("*+", "*");
exprIn = exprIn.replace("*-1", "*(0-1)");
exprIn = exprIn.replace(",-1", ",(0-1)");
exprIn = exprIn.replace("+(", "+1*(");
exprIn = exprIn.replace("-(", "-1*(");
exprIn = exprIn.replace("f(", "1*f(");
exprIn = exprIn.replace("g(", "1*g(");
exprIn = exprIn.replace("h(", "1*h(");
exprIn = exprIn.replace("dx(", "1*dx(");
exprIn = exprIn.replace("dy(", "1*dy(");
exprIn = exprIn.replace("dz(", "1*dz(");
exprIn = exprIn.replace("dD(", "1*dD(");
exprIn = exprIn.replace("exp(", "1*exp(");
exprIn = exprIn.replace(",+", ",");
exprIn = exprIn.replace(",(", ",1*(");
while (exprIn.contains("((")) {
exprIn = exprIn.replace("((", "(1*(");
}
if (exprIn.charAt(0) == '-' || exprIn.charAt(0) == '+') {
exprIn = "0" + exprIn;
}
if (exprIn.charAt(0) == '(') {
exprIn = "1*" + exprIn;
}
}
测试与被测试
Bug本身
在上学期的OOpre以及计组课程的学习中,由于代码量并没有那么大,并且都遵循了迭代开发——如果相信之前的代码正确,那么只需要对本次代码负责的原则,我查找bug的方式绝大时候都是阅读代码,在脑中模拟一遍函数结果,如果保证了每一个单元的正确,调用逻辑也是正确的,还有什么理由出bug呢?
也许在上学期这样的代码检查手段还是有效的,但是在本单元的作业中,我就充分意识到了阅读代码找bug的局限性:人脑是无法模拟函数调用时的耗时、以及如果认识本身就是错误的,那么贴合认识的代码也会是错误的。
两次未曾预想的出现bug:不合理的优化函数设计导致TLE、输出时少了一个括号,都是原先的阅读代码方式无法查找到的bug。
同时,不仔细读形式化、不关注代价函数,认为自己的代码有着较强的适应性,都导致了我没能在输出时加上正确数量的括号,没有测试多嵌套的exp。
虽然我被hack了,但是我承认exp嵌套求导这种测试数据是对代码调用逻辑、架构的一次全面检测,可以多一些这样的压力测试数据。
后人哀之而不鉴之,亦使后人复哀后人也!
如何优化测试
在使用室友的评测机之前,我所用的方法都是自己构造几个数据,测试功能。核心的测试逻辑就是保证每个功能单元的正确性和功能之间调用逻辑的正确性。这样的测试确实保证了程序的功能没有出错,但是却测试不出时长、表达式长度等问题。
在互测中,我也是大概的逻辑。其实评测机测别人Bug是很无力的,随着开源评测机/公开评测机的出现,常见的数据其实都已经在本地被测试过很多次,真正能够出bug的部分往往还是针对性hack的。比如第二次作业是以为同学的bug只会在-x-1-exp(x)时出现,其他情景怎么都不会出现;还有比如说exp(-x)这种少加括号的场景。
但是互测把他人代码通读一遍也不现实(何况还有防御性编程),我在认为大家的思路其实大差不差(研讨课的调研结果)的认识下,开始构造一些自认为体现程序正确性的数据,比如exp(-x),f(x)=x,g(y)=f(y)这种数据。但是如果不能hack成功,那么房间里有人hack成功了再出手,这时候可以更有针对性,毕竟知道有无bug比试出bug更难。
在之后的测试中,我也会进一步优化自身的测试,考虑如运行时间等限制。
心得与体会
第一个月很快就要过去了,第一单元的OO并没有想象中那么恐怖,还是比较亲切和善的。我还是怀念OOpre从头到尾没有一次bug的优雅,回来吧最初的美好😭
接下来一个月是多线程单元,对拍可能无法解决正确性的问题,同时阅读代码也无法正确预估调度算法的优劣,更需要有合适的测试策略,来对代码进行更为详尽的测试。
总的来说,表达式还是很好玩的,但是我觉得exp拆分这样的优化是没有什么必要的,大部分同学都没有足够的算法能力来解决这一难以得到最优解的问题,反而成为了少数OI佬干爆绝大多数人性能分的秀场。希望之后的课程中对性能的追求可以限定在一个较为合理的范围内。
本单元的性能分聚焦的应该是能否找到最佳的合并方式, sin 2 ( x ) + cos 2 ( x ) = 1 \sin^2(x)+\cos^2(x)=1 sin2(x)+cos2(x)=1就可以看作是一种好合并,这样的合并是有数学可依,且有理论最优解的。但是表达式展开并不是,是一个在理论上无最优解,需要依靠启发式算法去碰结果的反向过程。
我觉得性能应该考虑分段给分,而不是连续的函数给分。在当前的测试尺度下,中测10个测试点,强测20个测试点,完全是可以让助教提前得到最简表达式的长度的,可以设置在每个阶段的表达式长度给多少分,直接按照长度比例给分没什么必要。我就认为,把-1+x优化为x-1完全没必要,但为了自己的性能分我还是优化了这一点。















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









