







HBase相关基础知识

1. HBase简介
HBase是一个分布式的、面向列的开源数据库,与关系型数据库不同的是,HBase是一个适合于非结构化数据存储的数据库,并且它是基于列的而不是基于行的模式。利用HBase技术可在廉价PC服务器上搭建起大规模结构化存储集群。
2. HBase的数据模型
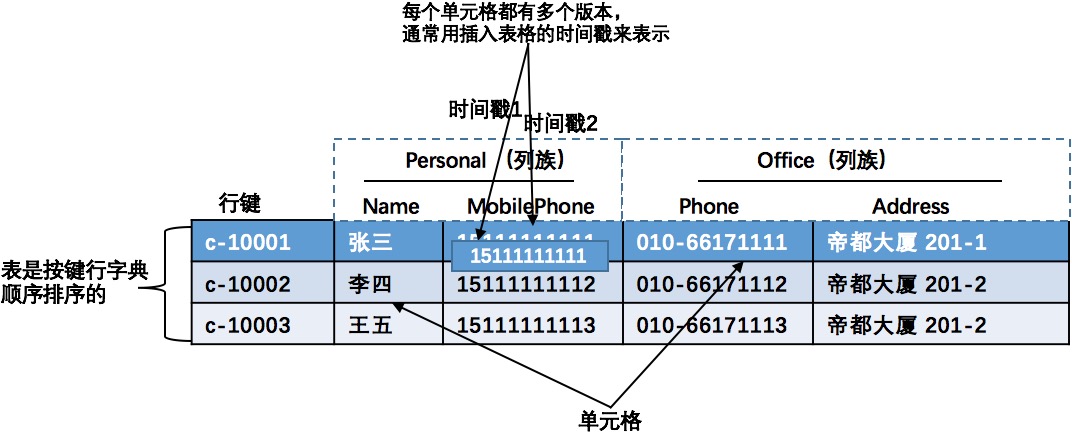
HBase数据存储结构中主要包括:表、行、列族、列限定符、单元格和时间戳,如下图所示:
-
表(table): 表的作用将存储在HBase的数据组织起来。
-
行(row): 行由一个RowKey和多个列族组成,一个行有一个RowKey,用来唯一标示。行键没有数据类型,在HBase存储系统中行键总是被看作一个byte数组。
-
列族(Column Family): 在行中的数据都是根据列族分组,由于列族会影响存储在HBase中的数据的物理布置,所以列族会在使用前定义(在定义表的时候就定义列族),并且不易被修改。
在HBase的存储系统中数据存储在相同的表中的所有行的数据都会有相同的列族(这和关系型数据库的表一样,每一行数据都有相同的列)。 -
列(Column): 存储在在列族中的数据通过列限定符或列来寻址的,列不需要提前定义(不需要在定义表和列族的时候就定义列),列与列之间也不需要保持一致。列和行键一样没有数据类型,并且在HBase存储系统中列也总是被看作一个byte数组。
-
单元格(cell): 根据行键、列族和列可以映射到一个对应的单元格,单元格是HBase存储数据的具体地址。在单元格中存储具体数据都是以Byte数组的形式存储的,也没有具体的数据类型。
-
时间戳(Timestamp): 时间戳是给定值的一个版本号标识,每一个值都会对应一个时间戳,时间戳是和每一个值同时写入HBase存储系统中的。在默认情况下,时间戳表示数据服务在写入数据时的时间,但可以在将数据放入单元格时指定不同的时间戳值。
3. HBase特点
- 数据规模大,单表可容纳数十亿行,上百万列。
- 无模式,不像关系型数据库有严格的Scheme,每行可以有任意多的列,列可以动态增加,不同行可以有不同的列,列的类型没有限制。
- 稀疏,值为空的列不占存储空间,表可以非常稀疏,但实际存储时,能进行压缩。
- 面向列族,面向列族的存储和权限控制,支持列族独立查询。
- 数据多版本,利用时间戳来标识版本
- 数据无类型,所有数据以字节数据形式存储
4. HBase与Hive区别
Hive本质上还是让人用熟悉的SQL语言进行离线数据分析用的语言外壳,它只是在hadoop外面套了一层关系型数据库的外壳而已。
而Hbase是NOSQL的,支持实时操作(增删改查)的分布式数据库,虽然底层还是hdfs,但它有自己的key-value/列存储模式。
| 特点 | Hive | HBase |
|---|---|---|
| 是否支持SQL | 可以理解为一种SQL执行引擎,对SQL的支持最终转换为map/reduce任务 | 不支持 |
| 数据操作 | 不支持更新、删除操作,但可以追加或覆盖 | 支持增删改查操作 |
| 查询速度 | 查询速度较慢,用时一般为数分钟到数小时 | 由于是key-value模式,根据key的查询速度较快。但根据非key的条件字段的批量查询或全表扫描较慢 |
| 数据存储 | 本身不存储数据,只存储关于数据的元数据,偏重于逻辑结构,是一种逻辑结构上类似于关系型数据库的数据仓库 | 本身存储数据,有复杂的物理存储结构,是一种真正的数据库(NOSQL) |
| 适用场景 | 适合于静态大数据量的查询、分析、汇总,不适合联机实时数据处理 | 适合联机实时数据处理 |
| 操作原理 | 操作一般以全表数据为基础,但也有分区/桶等概念 | 操作以列为基础 |
5. HBase简单代码示例
object HBaseTest01 {
// 设置用户
System.setProperty("HADOOP_USER_NAME", "app_frtfd_admin")
// 设置SparkConf对象
var sparkConf: SparkConf = new SparkConf()
sparkConf.setAppName("HiveTest01")
sparkConf.setMaster("local")
// 创建SparkContext对象
val sparkContext: SparkContext = new SparkContext(sparkConf)
// HBaseConfiguration
private val hbaseConf = HBaseConfiguration.create()
// hbase连接
private val conn = ConnectionFactory.createConnection(hbaseConf)
// hbaseAdmin
private val hbaseAdmin = conn.getAdmin
// HBaseContext
private val hbaseContext = new HBaseContext(sparkContext, hbaseConf)
def main(args: Array[String]): Unit={
// 表名
val tableName: String = "fct_frtfd:fct_ind_doc"
val table: Table = conn.getTable(TableName.valueOf(tableName))
var scanner: ResultScanner = null
var result: Result = null
val resultList = new util.ArrayList[RowData]
try {
val s = new Scan()
scanner = table.getScanner(s)
result = scanner.next()
while (result != null) {
for (rowKv <- result.rawCells()) {
val rowData = new RowData
val family = new String(rowKv.getFamilyArray, rowKv.getFamilyOffset, rowKv.getFamilyLength, "UTF-8")
val qualifier = new String(rowKv.getQualifierArray, rowKv.getQualifierOffset, rowKv.getQualifierLength, "UTF-8")
val timeStamp = rowKv.getTimestamp.toString
val rowKey = new String(rowKv.getRowArray, rowKv.getRowOffset, rowKv.getRowLength, "UTF-8")
val value = new String(rowKv.getValueArray, rowKv.getValueOffset, rowKv.getValueLength, "UTF-8")
rowData.setFamily(family)
rowData.setQualifier(qualifier)
rowData.setTimeStamp(timeStamp)
rowData.setRowKey(rowKey)
rowData.setValue(value)
resultList.add(rowData)
}
result = scanner.next()
}
} catch {
case e: IOException =>
}
println(resultList.toString)
}
}
参考链接
https://www.jianshu.com/p/5ce9b72e3341
https://blog.csdn.net/whdxjbw/article/details/81101200















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









