







 本文详细介绍了Logstash中的GrokFilter如何使用正则表达式解析非结构化日志,以及GeoipFilter如何根据IP地址获取地理位置信息。还展示了如何配置Logstash处理Apache日志和Kafka输入,以及将数据发送至Elasticsearch。
本文详细介绍了Logstash中的GrokFilter如何使用正则表达式解析非结构化日志,以及GeoipFilter如何根据IP地址获取地理位置信息。还展示了如何配置Logstash处理Apache日志和Kafka输入,以及将数据发送至Elasticsearch。
1、Grok Filter
Filter 插件(过滤器插件)是 Logstash 功能强大的主要原因,它可以对 Logstash Event 进行丰富的处理,比如说解析数据、删除字段、类型转换等等,常见的有如下几个:
| grok 正则匹配解析 | mutate:对字段做处理,比如重命名、删除、替换等 |
| date 日期解析 | json:按照 json 解析字段内容到指定字段中 |
| dissect 分割符解析 | ruby: 利用 ruby 代码来动态修改 Logstash Event |
| geoip 增加地理位置数据 |
grok 是一个十分强大的 logstash filter 插件,他可以通过正则解析任意文本,将非结构化日志数据解析成结构化和方便查询的结构内容,将其定义成我们平时容易理解的一些字段名称。他是目前 logstash 中解析非结构化日志数据最好的方式。
# 使用 grok filter 需要在 logstash 的配置文件中加上这样的内容:
filter {
grok {
match => {
"message" => "grok_pattern"
}
}
}grok_pattern 部分需要使用者填充自己的解析方式。
grok_pattern 由零个或多个%{SYNTAX:SEMANTIC}组成,其中 SYNTAX 是表达式的名字,即文本匹配的模式的名称,是由 grok提供的,例如数字表达式的名字是 NUMBER, IP 地址表达式的名字是 IP。
SEMANTIC 表示解析出来的这个字符的名字,即为匹配的文本提供的标识符,由自己定义,例如 IP 字段的名字可以是 client。
# 创建一个测试配置文件
vim /usr/local/logstash-8.12.1/config/test.conf
------------------------------------------------------------
input {stdin{}}
filter {
grok {
match => {
"message" =>
"%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"
}
}
}
output {stdout{codec => rubydebug}}数字表达式的名字是 NUMBER,%{NUMBER:duration}可以匹配数值类型,但是 grok 匹配出的内容都是字符串类型,可以通过在最后指定为 int 或者 float 来强制转换类型。%{NUMBER:duration:float},data_type 目前只支持两个值:int 和 float。
# 重新启动服务
logstash -f /usr/local/logstash-8.12.1/config/test.conf
# 输入如下内容:
192.168.1.2 GET /index.html 15824 0.043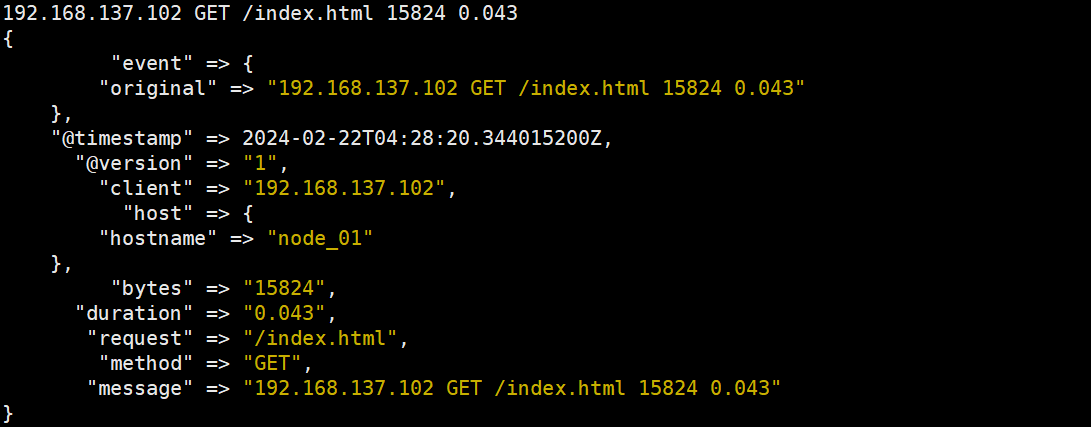
自定义 SYNTAX
默认 grok 调用 /usr/local/logstash-8.12.1/vendor/bundle/jruby/3.1.0/gems/logstash-patterns-core-4.3.4/patterns/目录下的正则
ls /usr/local/logstash-8.12.1/vendor/bundle/jruby/3.1.0/gems/logstash-patterns-core-4.3.4/patterns/ecs-v1/
① 直接在 grok 里面使用自定义表达式
语法格式:(?<filed_name>pattern)
- ?<filed_name>表示要取出里面的值
- pattern 就是正则表达式
vim /usr/local/logstash-8.12.1/config/test.conf
-------------------------------------------------------------
input {stdin{}}
filter {
grok {
match => {
"message" => "(?<date>\d+\.\d+)\s+(?<city>\w+)\s+(?<weather>\w+)"
}
}
}
output {stdout{codec => rubydebug}}
# 重新启动服务
jps -m
kill -9 ?
logstash -f /usr/local/logstash-8.12.1/config/test.conf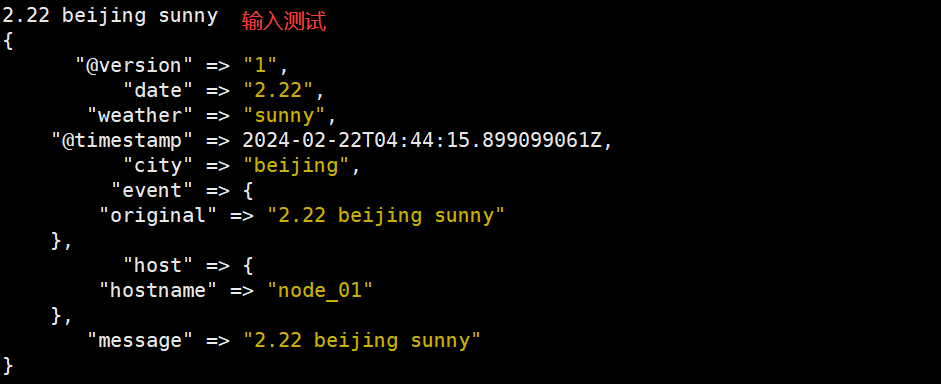
② 自定义正则表达式文件
cd /usr/local/logstash-8.12.1/vendor/bundle/jruby/3.1.0/gems/logstash-patterns-core-4.3.4/patterns/ecs-v1/
vim test
--------------------------------------------
USER_IPADDRESS ([0-9\.]+)\s+
DATETIME ([0-9\-]+\s[0-9\:]+)\s+
METHOD ([A-Z]+)\s+
URL ([\/A-Za-z0-9\.]+)\s+
STATUS ([0-9]+)\s+
REQUEST_SEND ([0-9]+)\s+
REQUEST_TIME ([0-9\.]+)
--------------------------------------------
# 修改logstash配置文件
vim /usr/local/logstash-8.12.1/config/test.conf
---------------------------------------------------------------------------------
input {stdin{}}
filter {
grok {
patterns_dir => ["./patterns"]
match => {
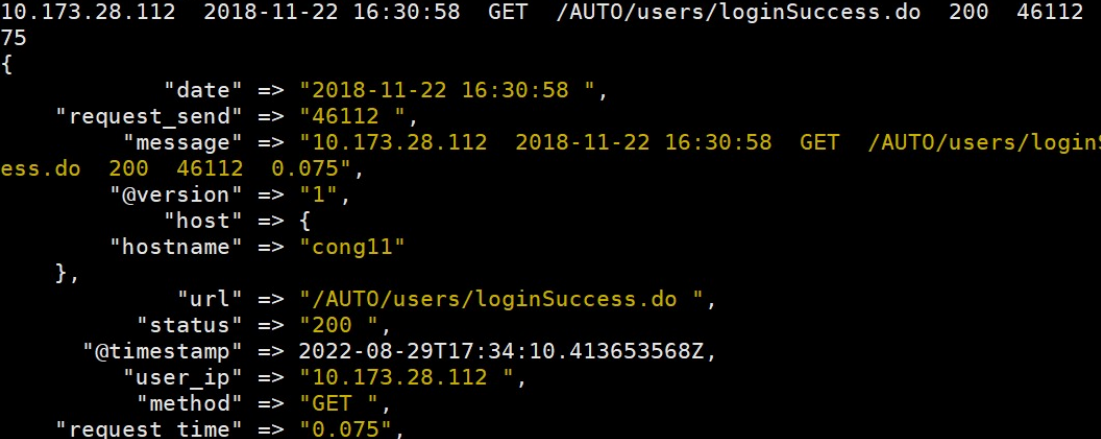
"message" => "%{USER_IPADDRESS:user_ip} %{DATETIME:date} %{METHOD:method} %{URL:url} %{STATUS:status} %{REQUEST_SEND:request_send} %{REQUEST_TIME:request_time}"
}
}
}
output {stdout{codec => rubydebug}}
---------------------------------------------------------------------------------注意:patterns_dir => "./patterns" #添加 test 正则文件路径,调用我们自己写 好的%{SYNTAX_NAME:SEMANTIC}
10.173.28.112 2018-11-22 16:30:58 GET /AUTO/users/loginSuccess.do 200 46112 0.075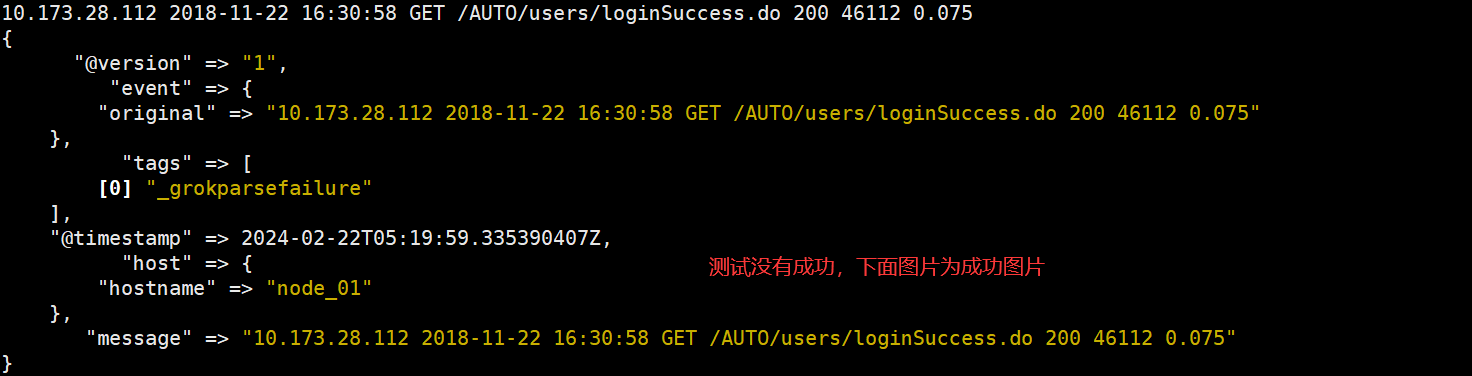
使用 Grok Filter 插件编辑解析 Web 日志
Grok 插件使用详解: https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
使用 grok filter 过滤 httpd 日志,由于 grok 过滤器插件在传入的日志数据中查找模式,因此配置插件需要你决定 如何识别用例感兴趣的模式。Web 服务器日志示例中的代表行如下所示
[root@cong12 ~] cat /var/log/httpd/access_log
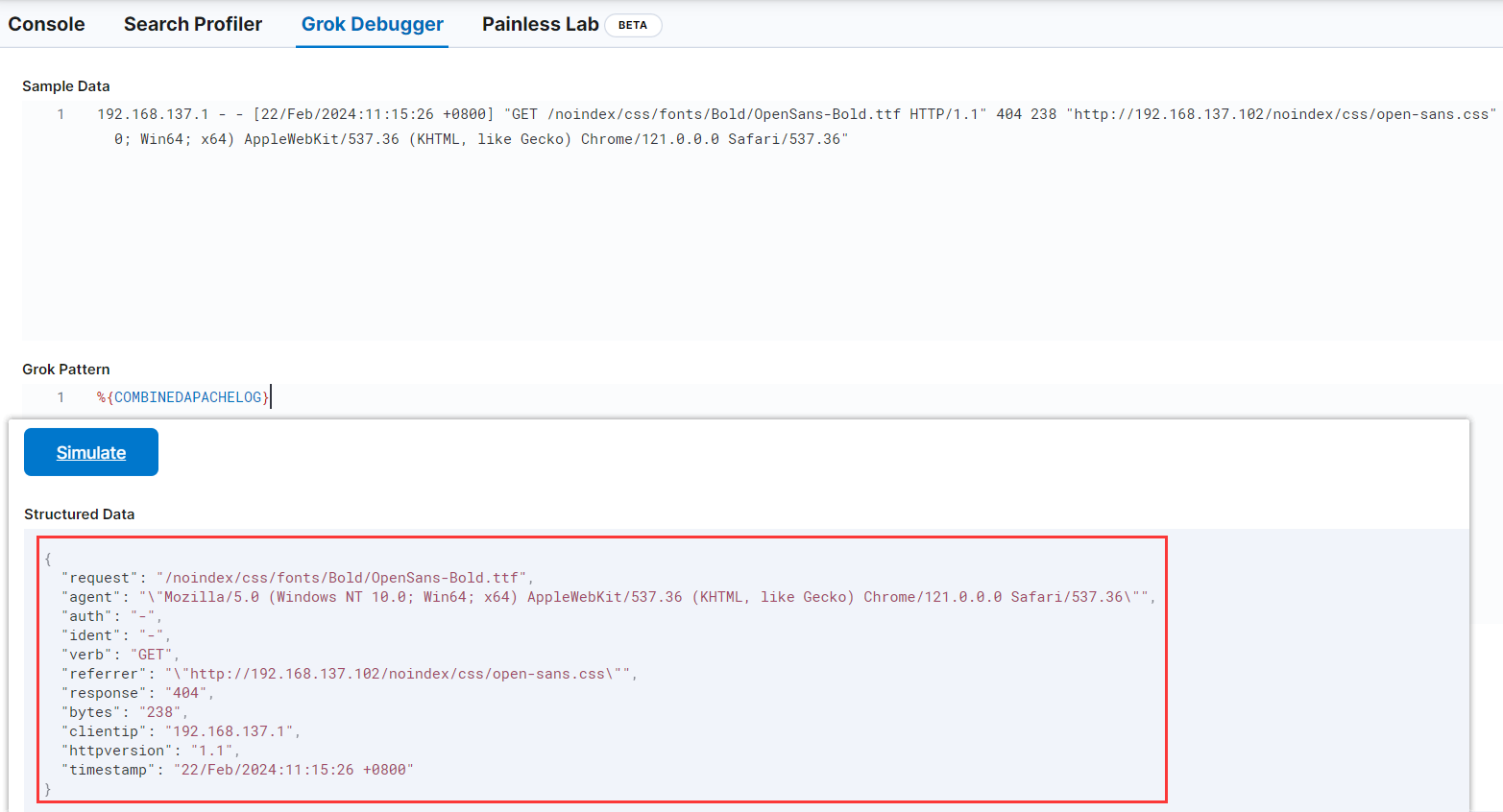
该行开头的 IP 地址很容易识别,括号中的时间戳也是如此。要解析数据,可以使用%{COMBINEDAPACHELOG}grok 模式,该模式使用以下模式构建 Apache 日志中的行:
vim /usr/local/logstash-8.12.1/config/http_logstash.conf
------------------------------------------------------------------------
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
kafka{
codec => "json"
bootstrap_servers => "192.168.137.103:9092"
# 设置client.id & group.id 做标识
client_id => "httpd_logs"
group_id => "httpd_logs"
consumer_threads => 5
# 从最新的偏移量开始消费
auto_offset_reset => "latest"
# 将当前的 topic,offset,group,partition 等信息 也带到messages中
decorate_events => true
topics => "httpd_logs"
}
}
# 数据处理,过滤,为空不过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
# 过滤后丢弃原有信息
remove_field => "message"
}
}
# 输出插件,将时间发送到特定目标
output {
# 标准输出,把收集的日志在当前终端显示,方便测试服务连通性
# 编码器为rubydebug
stdout{
codec => "rubydebug"
}
# 将事件发送到es,在es中存储日志
elasticsearch {
hosts => ["http://192.168.137.101:9200"]
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
# index 表示事件写入的索引。可以按照日志来创建索引,以便于删除旧数据和时间来搜索日志
index => "var-messages-%{+yyyy.MM.dd}"
#user => "elastic"
#password => "changeme"
}
elasticsearch{
hosts => ["192.168.137.101:9200"]
index => "httpd-logs-%{+YYYY.MM.dd}"
}
}
------------------------------------------------------------------------
jps -m
kill -9 4102
grok 正则测试工具
grok 是通过系统预定义的正则表达式或者通过自己定义正则表达式来匹配日志 中的各个值。 正则解析式比较容易出错,建议先调试,kibana 提供了 grok debbuger
Web页面 -> Management -> Dev Tools -> grok debbuger
2、Geoip Filter
geoip 是常见的免费的 IP 地址归类查询库,geoip 可以根据 IP 地址提供对应的地域信息,包括国别,省市,经纬度等等,此插件对于可视化地图和区域统计非常有用。
该 geoip 插件配置要求指定包含 IP 地址来查找源字段的名称。在此示例中,该 clientip 字段包含 IP 地址。
由于过滤器是按顺序进行评估,确保该 geoip 部分是在 grok 配置文件之后,无论是 grok 和 geoip 部分嵌套在内部 filter 部分。
# 修改配置文件
vim /usr/local/logstash-8.12.1/config/http_logstash.conf
---------------------------------------------------------------------------------
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
kafka{
codec => "json"
bootstrap_servers => "192.168.137.103:9092"
# 设置client.id & group.id 做标识
client_id => "httpd_logs"
group_id => "httpd_logs"
consumer_threads => 5
# 从最新的偏移量开始消费
auto_offset_reset => "latest"
# 将当前的 topic,offset,group,partition 等信息 也带到messages中
decorate_events => true
topics => "httpd_logs"
}
}
# 数据处理,过滤,为空不过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
# 过滤后丢弃原有信息
remove_field => "message"
}
geoip {
source => "[source][address]"
target => "useragent"
}
}
# 输出插件,将时间发送到特定目标
output {
# 标准输出,把收集的日志在当前终端显示,方便测试服务连通性
# 编码器为rubydebug
stdout{
codec => "rubydebug"
}
# 将事件发送到es,在es中存储日志
elasticsearch {
hosts => ["http://192.168.137.101:9200"]
#index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
# index 表示事件写入的索引。可以按照日志来创建索引,以便于删除旧数据和时间来搜索日志
index => "var-messages-%{+yyyy.MM.dd}"
#user => "elastic"
#password => "changeme"
}
elasticsearch{
hosts => ["192.168.137.101:9200"]
index => "httpd-logs-%{+YYYY.MM.dd}"
}
}
---------------------------------------------------------------------------------
# 插入测试数据
[root@cong12 ~] echo '''61.135.169.125 - - [11/Sep/2019:01:59:37 +0800] "GET /noindex/css/fonts/ExtraBoldItalic/OpenSans-ExtraBoldItalic.ttf HTTP/1.1" 404 260 "http://192.168.1.12/" "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"''' >> /var/log/httpd/access_log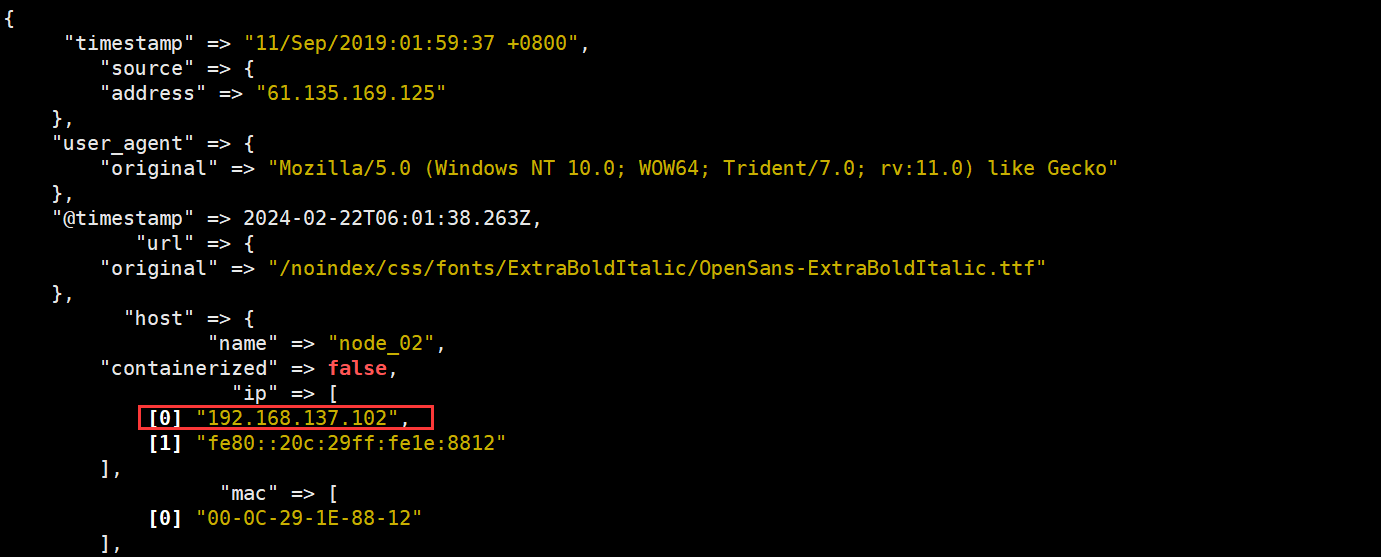















 2832
2832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









