







第一次接触爬虫,有写的不好的地方请见谅,欢迎大家指正~~
<在昨天完成后,今天我又对它进行了完善,见文https://blog.csdn.net/Yvonne_Lu7/article/details/81117071>
我得到的任务是爬取https://bbs.pku.edu.cn/v2/thread.php?bid=690&mode=topic网站的帖子题目以及心理咨询师的回复。
我首先先尝试爬取一篇帖子的标题以及其中心理咨询师的回复,将其封装为一个函数getLinks(pageUrl),这个函数的参数是这篇帖子的URL。通过对网站帖子HTML代码的研究,可以发现,帖子的标题很好找,标签为h3,而且本页也只有一个h3标签,图片如下:

而相对复杂一些的就是心理咨询师的回复,如何能在一群回复中准确找到心理咨询师的回复呢?通过观察心理咨询师回复与其他网友回复的代码区别,发现:
心理咨询师:
普通网友:
因此,只要爬取所有回复,在其中筛选出.text == '心理咨询师'的回复就可以了。
而这时,我又遇到了一个难点,因为上一步我实际爬取的是所有的回复者的身份,从中找到心理咨询师,而我应该如何根据确定的回复者的身份来判断是否爬取他的回复呢?通过研究代码发现,首先可以将确定为心理咨询师的回复的整篇回复爬取下来(即包括心理咨询师个人信息部分,回复部分,引用原文部分等,图如下)
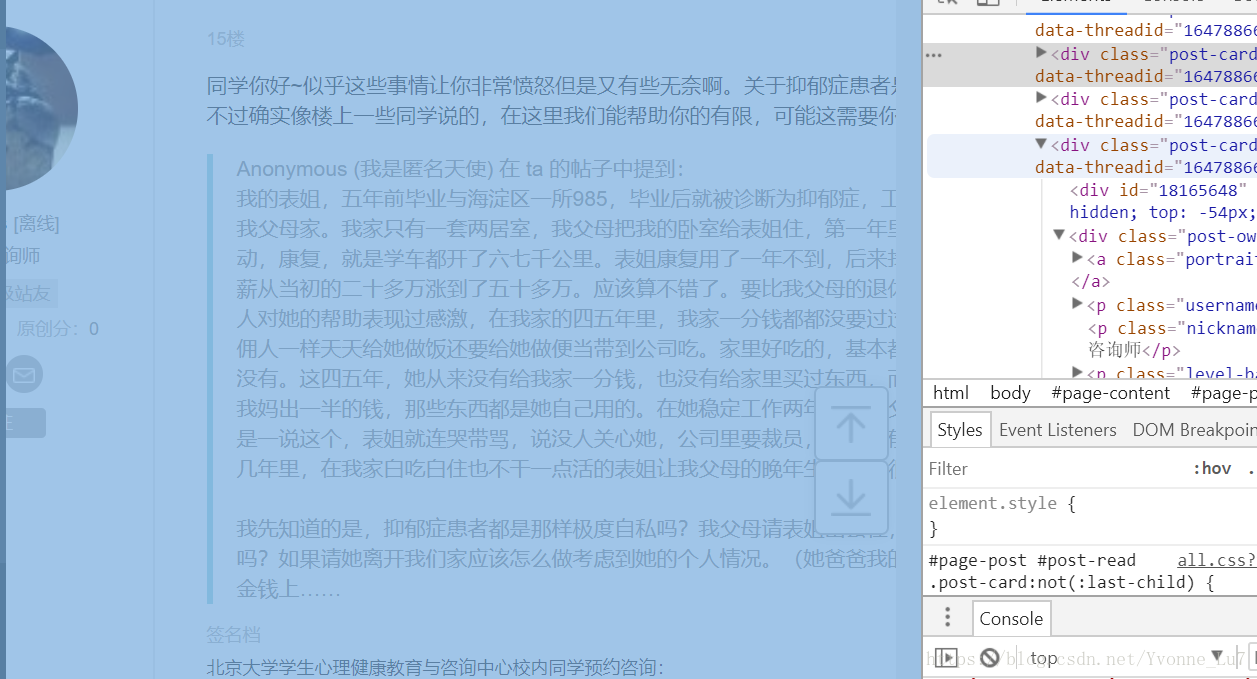
而这整篇回复是放在一个class为post-card的div下的,而这个div恰好是我们之前爬取好的回复者身份的parent.parent,我们将这个大div整个转化为string,并创建BeautifulSoup对象,然后就可以在这个新的bs对象下爬取回复啦~代码如下:
def getLinks(pageUrl):
html = urlopen("https://bbs.pku.edu.cn/v2/" + pageUrl)
bsObj = BeautifulSoup(html.read(), 'html.parser')
try:
print('标题:'+bsObj.find(id="post-read").find("h3").get_text())
name = bsObj.findAll('p', {'class': 'nickname text-line-limit'})
for n in name:
if n.text == '心理咨询师':
postcard = n.parent.parent
bsn = BeautifulSoup(str(postcard), 'html.parser')
answer = bsn.find('div', {'class': 'body file-read image-click-view'}).p
print('心理咨询师的回复:'+answer.get_text())
print('------------------------------')
except AttributeError:
print("页面缺少一些属性!不过不用担心!")
这样爬取一篇帖子的标题和回复的函数就做好啦,只需要将这个函数嵌入我们所需要的部分就可以了。
而现在,我们需要做的是如何爬取所有帖子,通过观察网页,我们可以发现,一个网页中有很多篇帖子,而这样的网页也有很多页,因此,如果我们需要爬取所有的帖子题目以及回复,就需要爬取每页网页的url以及每页网页中每篇帖子的url。
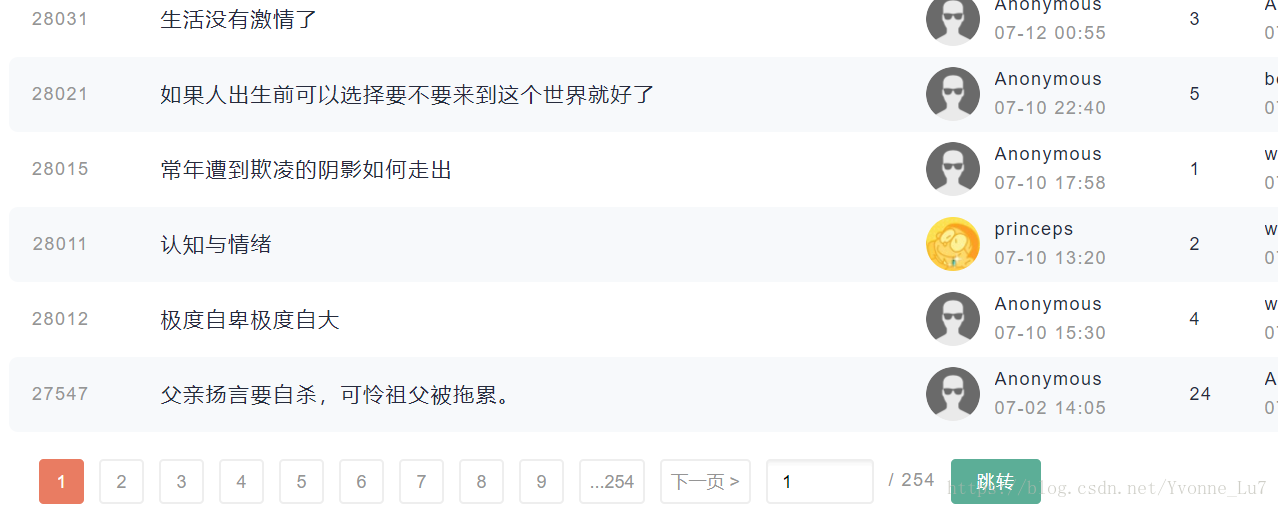
通过开发者工具可以看到,页数的url是存在class为paging-button n的div下的a标签中

因此,我们可以爬取所有的页数
btn = bsObj.findAll('div', {'class': 'paging-button n'})
由此可以获得一个所有页数url的列表,有这个列表后,我们就可以通过for循环,找到每一页所有帖子的url,而每篇帖子的url恰好就是我们之前以及做好的函数getLinks(pageUrl)所需要的参数。
所有代码如下:
from urllib.request import urlopen
from bs4 import BeautifulSoup
def getLinks(pageUrl):
html = urlopen("https://bbs.pku.edu.cn/v2/" + pageUrl)
bsObj = BeautifulSoup(html.read(), 'html.parser')
try:
print('标题:'+bsObj.find(id="post-read").find("h3").get_text())
name = bsObj.findAll('p', {'class': 'nickname text-line-limit'})
for n in name:
if n.text == '心理咨询师':
postcard = n.parent.parent
bsn = BeautifulSoup(str(postcard), 'html.parser')
answer = bsn.find('div', {'class': 'body file-read image-click-view'}).p
print('心理咨询师的回复:'+answer.get_text())
print('------------------------------')
except AttributeError:
print("页面缺少一些属性!不过不用担心!")
html = urlopen('https://bbs.pku.edu.cn/v2/thread.php?bid=690')
bsObj = BeautifulSoup(html.read(), 'html.parser')
btn = bsObj.findAll('div', {'class': 'paging-button n'})
for n in btn:
articles = bsObj.findAll('div', {'class': 'list-item-topic list-item'})
for art in articles:
getLinks(art.a.attrs['href'])
html = urlopen('https://bbs.pku.edu.cn/v2/thread.php'+n.a.attrs['href'])
bsObj = BeautifulSoup(html.read(), 'html.parser')
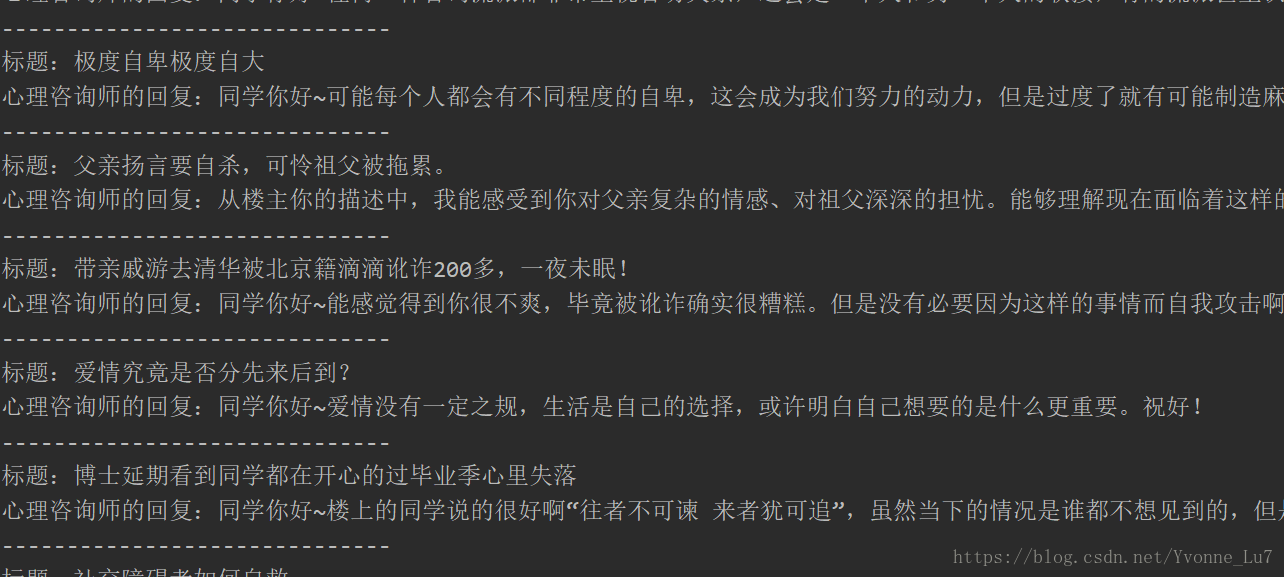
爬取的结果如图所示:














 2749
2749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









