







来学NLP, 课程是斯坦福CS224N, 我用的2021版, b站搜出来的第一个就是了
课程视频:(Lecture 1 Introduction and Word Vectors)https://www.bilibili.com/video/BV18Y411p79k/?share_source=copy_web&vd_source=89823c744096e29cafad55e0e1765912
课程教材:无
课程作业:http://web.stanford.edu/class/cs224n/index.html,5 个编程作业 + 1 个 Final Project
The Course
-
介绍NLP相关知识,基本概念
-
学会PyTorch等工具的使用
Human language and word meaning
-
语言的特点
-
由人类产生, 不断变化
-
-
NLP的目的
-
让计算机看得懂人类语言
-
让计算机拥有人类智慧(computer with knowledge of people)
-
-
进展/成果
-
翻译(machine translation)
-
chatGPT--> universal model
-
-
怎么描述一个词汇
-
旧方法: 指称语义
-
含义: 用同义词描述, 将一个个词语视为一个个离散的符号
-
缺点:
-
在细节上容易阐释不清
-
词库是有限的, 部分词语无法用同义词替换
-
-
-
新方法: 分布语义
-
含义: 不再依靠同义词来描述一个词语, 而是在某一个语境下依靠周围词汇来阐述某词汇的含义("You shall know a word by the company it keeps!")
-
过程
-
收集语段资料--为每个表示单词含义的单词建立密集实值向量(build up dense real valued vector for each words represent the meaning of words)
-
-
检验: 用于预测语段中随机某个词语的含义
word一词在NLP中的两种含义(说实话我自己都有点蒙)-
Types:同义词
-
Tokens:象征
-
-
-
Word2vec introduction
-
什么是Word2vec
-
word to vector--> 将词语变成向量, 是一个学习词语向量的框架
-
-
思路
-
搜集语料库(
corpus&body) -
将词汇表中的每一个单词都用向量表示
-
遍历语料库中的每一个词汇, 让每一个词汇都成为一次被描述的中心词C (
center), 并且将中心词周围的词语记为O (outside) -
使用C和C的词汇向量的相似性来计算给定O的概率(反之亦然)
-
调整向量使得概率最大化
-
-
具体过程
-
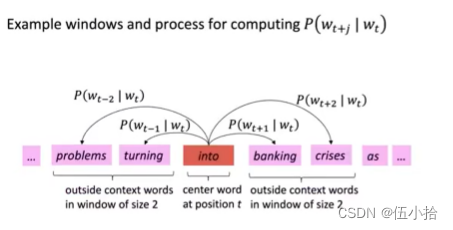
-
至于这里具体的概率P如何计算则是需要借助后面的函数
-
-
Word2vec objective function gradients
这里先放PPT吧
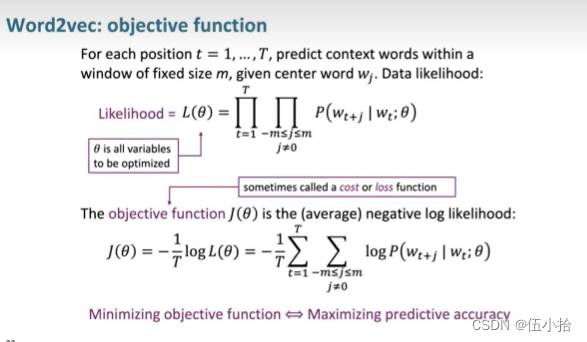
-
Likelihood =
-
计算范围: 语段内每一个单词都可以作为C, 然后将这个C前后长度为m的窗口的每一个词汇的概率进行相乘
-
注意
-
在这里
才是要优化的对象
-
-
-
: 目标函数, 也可以说是想要优化的成本或者损失
-
-
在这里使用对数来进行计算使得之前的Likelihood变成和, 简化计算,
-
同时, 使用了平均的Likelihood, 所以前面有一个
-

-
如何计算一个单词在上下文中出现的概率
-
在这里给每个单词赋予了两个向量
-
当该单词作为C的时候使用
-
当该单词作为O的时候使用
-
-
然后就可以获得一个描述相似度的数据,接下来需要将该数据转化为概率
-

-
但是对于概率一般来说需要将范围控制在0~1之间所以这里还需要一个softmax函数对求出来的概率进行归一化(分母)
-
为了防止出现负数, 所以这里使用了exp
-
另外, softmax函数还对概率进行了一定程度上的放缩再返回概率分布(所以叫max)
-
在这里, softmax函数并没有直接指出最大的概率对应的词汇, 而是仍然保留了其他词汇, 所以是soft
Optimization basics

接下来要做的就是训练模型对模型进行优化
是一个特别特别长的向量, 长度是2dv, 接下来讲讲2dv怎么来的
-
在这里每一个词汇都分别作为C和O出现了一次, 之前有讲过u和v, 所以需要乘2
-
N指的是词汇量, 就是有多少个词汇
-
d指的是窗口大小, 因为前面计算Likelihood是在一个长度为-m~m的窗口内进行的
-
注意: 在这里看似只有2N个向量但是实际上每一个u或者v都是一个小向量, 在这里为了排版这么写, 但是实际上写出来应该是可长可长一段了
-
所以要优化的方向就是让J(\theta)达到最小, 在这里需要进行一些微积分的操作
在这里优化的数学部分直接采用手写(字很丑但是应该看得懂吧)

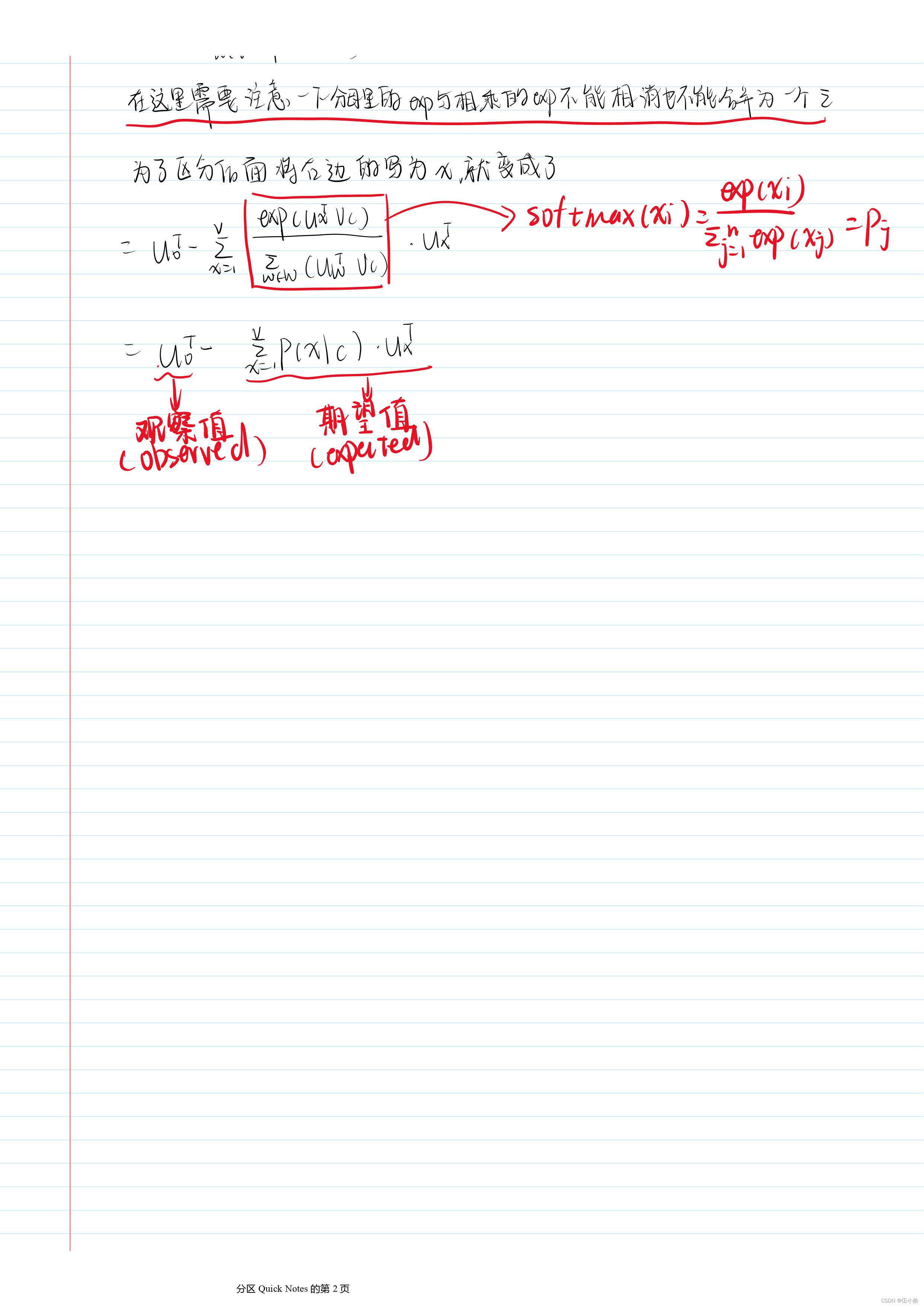
Looking at word vectors
视频里就展示了一下jupyter, 然后讲了一个就是类比功能
analogy['pencil','sketching','camera'] return 'photogra
Lecture 1 的笔记就这么多, 后面的Q&A环节就没记笔记了
最后放只小猫, 只是因为小猫Misty很可爱















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









