







前言
相信初学爬虫大家拿来练手的会有猫眼、软科大学排行榜等,但可能正因为此,太多人拿他们来做练习了,他们也相应的设置了反爬虫机制。
猫眼在直接登陆: 猫眼验证中心 时会弹出滑动验证码,验证了才能进入到排行榜页面,如下图所示,对于刚学爬虫时的我造成了很大的困扰,现在来对此进行解决。
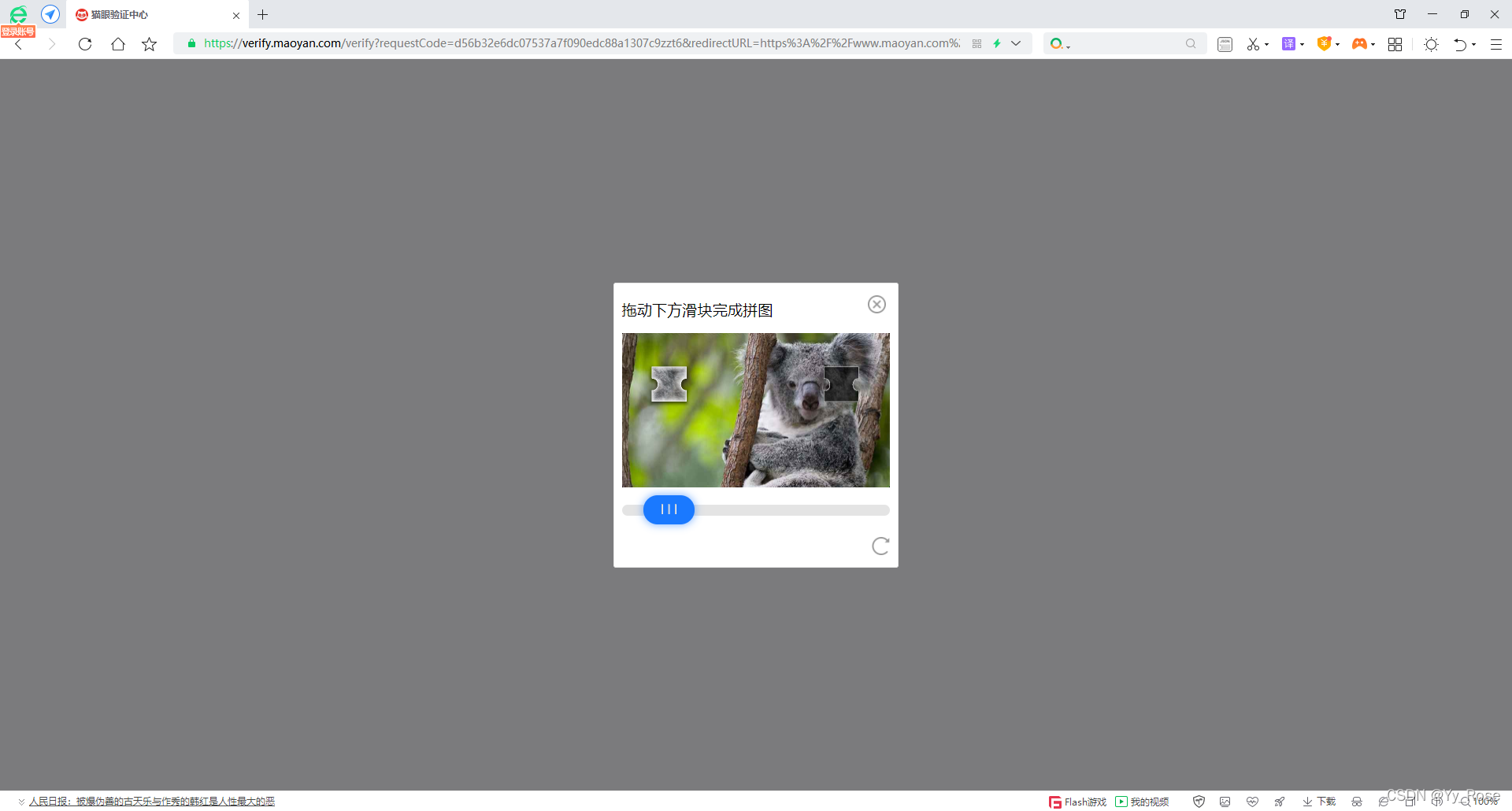
获取原图的相关思路在右侧目录中,可供参考,点击后可找到相关内容:
项目分析
这种滑动验证码的类型大致可分为两种:1.源码中能找到完整背景图的;2.没有提供完整背景图的。对于第一种情况,一般的处理方式是分别找出有缺口的图片和完整的背景图,然后进行像素点对比,找出缺口位置,获取缺口的偏移量最后确定滑块的移动轨迹。而第二种情况,则是获取带缺口的背景图片和滑块的图片,然后通过opencv库对图片进行识别,缺口匹配,得出最优的匹配结果,锁定滑块的移动轨迹,这种解决方式同样可以解决第一种类型的验证码。
这里属于第二种情况,那么我们就基于此具体分析下解决步骤:
初始化信息
定位获取背景图元素
定位获取缺块元素
定位获取滑块元素
获取带缺口背景图和缺块图片
识别缺口位置
设计移动速度和移动轨迹
拖动滑块项目实现
1)初始化信息
def __init__(self):
# 获取链接
self.url = 'https://maoyan.com/board/4?offset=100'
# 获取浏览器驱动
self.browser = webdriver.Chrome()
# 设置显式等待
self.wait = WebDriverWait(self.browser, 10)2)定位获取所需元素
在我定位验证码滑块元素的时候一直显示我定位语句错误,多次调试定位方法及路径未果,后来发现这里验证码的部分是用iframe写入的,具体对此问题的解决办法,可以观看我的另一篇博客:iframe中碰到的问题及解决方法_Yy_Rose的博客-CSDN博客

所以在定位元素前我们需要先切换到元素所在的frame中:
iframe = self.wait.until(
EC.presence_of_all_elements_located((By.TAG_NAME, 'iframe')))
self.wait.until(EC.frame_to_be_available_and_switch_to_it(iframe[1]))定位获取带缺口的背景图元素:

def bg_img_src(self):
bg_img_element = self.wait.until(EC.presence_of_element_located(
(By.XPATH,
'//*[@class="tc-bg"]/img')))
# 获取src属性内容
bg_img_src = bg_img_element.get_attribute('src')
return bg_img_src定位缺块元素:

def jpp_img_src(self):
target_img_element = self.wait.until(EC.presence_of_element_located(
(By.XPATH,
'//*[@class="tc-jpp"]/img')))
target_img_src = target_img_element.get_attribute('src')
return target_img_src定位滑块元素:

def slider_element(self):
time.sleep(2)
slider = self.wait.until(EC.presence_of_element_located(
(By.XPATH,
'//*[@class="tc-drag-thumb"]')))
return slider3)获取带缺口背景图片和滑块图片
def get_img(self):
# 获取图片
bg_src = self.bg_img_src()
jpp_src = self.jpp_img_src()
response1 = requests.get(bg_src)
# 存储Byte类型的图片
image1 = Image.open(BytesIO(response1.content))
# 图片像素 680*390
image1.save('bg_img.png')
response2 = requests.get(jpp_src)
image2 = Image.open(BytesIO(response2.content))
# 图片像素 136*136
image2.save('jpp_img.png')
return image1, image2获取到的图片示例:

bg_img.png

jpp_img.png
获取原图
我之前在测试获取图片链接的时候发现:
https://t.captcha.qq.com/hycdn?index=1&image=937159045618524928?aid=2017906796&sess=s0_QNEh1POoUl_dl78OfZqI8viz1ySW3lXnvGYJiBhoyIug8jmmzlx6u7rxisrmwscXjUZTPlsJgvXdYTyOXN4uY4pi4h_G5gHbBiOqFaQXWCnSK-v0RWLusaq9WCotUPXwls0n4klirO6y62DpY6NoIPLX6yEn4JEeCZ-ZA_UHrTeXojyyr06SHXn32TiNz1ci6xefUfsaJEleOwSwC1NMDlIyUhCHsbM5zrIV52jzoI6gPg9G4gj3d0xDXN9MHLUaC3qxPBIyIQ6DMvBPr75rSjEInC7zQ0oksYMlq6HrtRuZQ15p7x0cQ**&sid=6873095789103194112&img_index=1&subsid=3**&sid=6873095789103194112&img_index=1&subsid=3这个之前的链接点开就能获取完整的背景图:

所以我进行了以下的尝试:
bc_element = browser.find_element(By.XPATH, '//*[@class="tc-bg"]/img').get_attribute('src').split('**')
img_src = bc_element[0]
print(img_src)获取到了只有前面那段的链接,经过多次测试,虽然后面id是会变动的,但仍很大概率都是与验证码相匹配的背景完整图,这里只是提供另一种做法找原图的思路。
4)识别缺口位置
def get_gap(self, gap_img):
# 读取图片
bg_img = cv2.imread('bg_img.png')
tp_img = cv2.imread('jpp_img.png')
# 图片边缘检测,最小100,最大200
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
# 转换图片格式
# 灰度图片转为RGB彩色图片
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
# 缺口匹配
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
# 寻找最优匹配
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 绘制方框
# img.shape[:2] 获取图片的长、宽
height, width = tp_pic.shape[:2]
tl = max_loc # 左上角点的坐标
# 绘制矩形
# cv2.rectangle(img, (x1, y1), (x2, y2), RGB颜色值, 边框宽度--->若为负则填充整个矩形)
cv2.rectangle(bg_img, tl, (tl[0] + width - 15, tl[1] + height - 15),
(0, 0, 255), 2)
# 保存在本地
cv2.imwrite(gap_img, bg_img)
# 以下三行语句是使图片窗口可视化
# cv2.imshow('Show', bg_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 返回缺口的X坐标
return tl[0]相关知识:opencv cv2.rectangle 参数含义_Gaowang_1的博客-CSDN博客_cv2.rectangle
识别出的缺口位置:

5)获取运动轨迹
def get_track(self, distance):
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正5,可以选择调快点
a = 5
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track6)移动滑块
def move_to_gap(self, slider, track):
# click_and_hold()按住底部滑块
ActionChains(self.browser).click_and_hold(slider).perform()
# 沿x轴方向移动
for x in track:
ActionChains(self.browser).move_by_offset(xoffset=x,
yoffset=0).perform()
time.sleep(0.5)
# release()松开鼠标
ActionChains(self.browser).release().perform()源码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from PIL import Image
import cv2
from selenium.webdriver import ActionChains
import requests
from io import BytesIO
class MaoYanCode(object):
# 初始化
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset=100'
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 10)
def open(self):
# 打开网页
self.browser.get(self.url)
# 定位背景图
def bg_img_src(self):
bg_img_element = self.wait.until(EC.presence_of_element_located(
(By.XPATH,
'//*[@class="tc-bg"]/img')))
bg_img_src = bg_img_element.get_attribute('src')
return bg_img_src
# 定位缺块
def jpp_img_src(self):
target_img_element = self.wait.until(EC.presence_of_element_located(
(By.XPATH,
'//*[@class="tc-jpp"]/img')))
target_img_src = target_img_element.get_attribute('src')
return target_img_src
# 获取背景和缺块图片
def get_img(self):
bg_src = self.bg_img_src()
jpp_src = self.jpp_img_src()
response1 = requests.get(bg_src)
image1 = Image.open(BytesIO(response1.content))
image1.save('bg_img.png')
response2 = requests.get(jpp_src)
image2 = Image.open(BytesIO(response2.content))
image2.save('jpp_img.png')
return image1, image2
# 定位滑块
def slider_element(self):
time.sleep(2)
slider = self.wait.until(EC.presence_of_element_located(
(By.XPATH,
'//*[@class="tc-drag-thumb"]')))
return slider
# 识别缺口
def get_gap(self, gap_img):
bg_img = cv2.imread('bg_img.png')
tp_img = cv2.imread('jpp_img.png')
# 识别图片边缘
bg_edge = cv2.Canny(bg_img, 100, 200)
tp_edge = cv2.Canny(tp_img, 100, 200)
# 转换图片格式
# 灰度图片转为RGB彩色图片
bg_pic = cv2.cvtColor(bg_edge, cv2.COLOR_GRAY2RGB)
tp_pic = cv2.cvtColor(tp_edge, cv2.COLOR_GRAY2RGB)
# 缺口匹配
res = cv2.matchTemplate(bg_pic, tp_pic, cv2.TM_CCOEFF_NORMED)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res) # 寻找最优匹配
# 绘制方框
# img.shape[:2] 获取图片的长、宽
height, width = tp_pic.shape[:2]
tl = max_loc # 左上角点的坐标
# cv2.rectangle(img, (x1, y1), (x2, y2), RGB颜色值, 边框宽度--->若为负则填充整个矩形)
cv2.rectangle(bg_img, tl, (tl[0] + width - 15, tl[1] + height - 15),
(0, 0, 255), 2) # 绘制矩形
cv2.imwrite(gap_img, bg_img) # 保存在本地
# cv2.imshow('Show', bg_img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# 返回缺口的X坐标
return tl[0]
# 构造移动轨迹
def get_track(self, distance):
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 0
while current < distance:
if current < mid:
# 加速度为正5
a = 5
else:
# 加速度为负3
a = -3
# 初速度v0
v0 = v
# 当前速度v = v0 + at
v = v0 + a * t
# 移动距离x = v0t + 1/2 * a * t^2
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
# 移动滑块
def move_to_gap(self, slider, track):
# click_and_hold()按住底部滑块
ActionChains(self.browser).click_and_hold(slider).perform()
for x in track:
ActionChains(self.browser).move_by_offset(xoffset=x,
yoffset=0).perform()
time.sleep(0.5)
# release()松开鼠标
ActionChains(self.browser).release().perform()
def login(self):
self.open()
time.sleep(2)
# 网速原因可能导致网页加载不完全,致使iframe报错
iframe = self.wait.until(
EC.presence_of_all_elements_located((By.TAG_NAME, 'iframe')))
self.wait.until(
EC.frame_to_be_available_and_switch_to_it(iframe[1]))
self.get_img()
slider = self.slider_element()
slider.click()
gap = self.get_gap('result.png')
# 页面为360*360,图片为680*390,更改比例,减去初始位移
gap_end = int((gap - 40) / 2)
# 获取缺口
print('缺口位置', gap_end)
# 减去缺块白边
gap_end -= 10
# 获取移动轨迹
track = self.get_track(gap_end)
print('滑动轨迹', track)
# 拖动滑块
self.move_to_gap(slider, track)
if __name__ == '__main__':
crack = MaoYanCode()
crack.login()
注意:图片保存下来为原图大小,要用代码更改为与页面对应适合的比例,不然位移量会错误。
gap_end = int((gap - 30) / 2)如果导入cv2报错,可参考:cv2导入失败原因及安装opencv后仍报错的解决方式_Yy_Rose的博客-CSDN博客
如果需要登录验证的,则多定义一个函数用于键入数据,然后点击获取验证码后模拟点击登录就行了。selenium+crop+chaojiying之登录超级鹰_Yy_Rose的博客-CSDN博客 中有相关操作。
友情提示:如果网络较差,可能导致页面加载不完全,以至于元素读取不到,可以选择重试或采取异常捕捉后延时等待的方式进行处理,同时可以设置代理ip以免请求过多被拒绝服务,这里提供几个https的免费代理ip:
111.201.210.192:7890
8.218.91.61:59394
114.238.91.235:30001
代理ip网站:免费代理ip网站总结_成长的烧年-CSDN博客_免费代理ip网站
xpath相关Chrome浏览器插件安装及selenium中如何配置使用插件:
xpath-helper、chropath下载方式及selenium中如何配置使用插件_Yy_Rose的博客-CSDN博客
结言
以上并不一定是最优解,后续将会进行更新,欢迎大家指正交流~
—————————————————更新于2021.12.08——————————————————


















 2429
2429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









