






目录
解释为什么在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失
为什么在jdk1.8中,在多线程环境下,插入元素到空桶会发生数据覆盖的情况?
HashMap存在的问题
如果 HashMap 作为多线程的共享数据,比如单实例的成员变量、静态变量等
那么多线程并发修改 HashMap 时,是会出现线程不安全的问题的
1在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
2在jdk1.8中,在多线程环境下,插入元素到空桶会发生数据覆盖的情况。
介绍HashMap的transfer方法
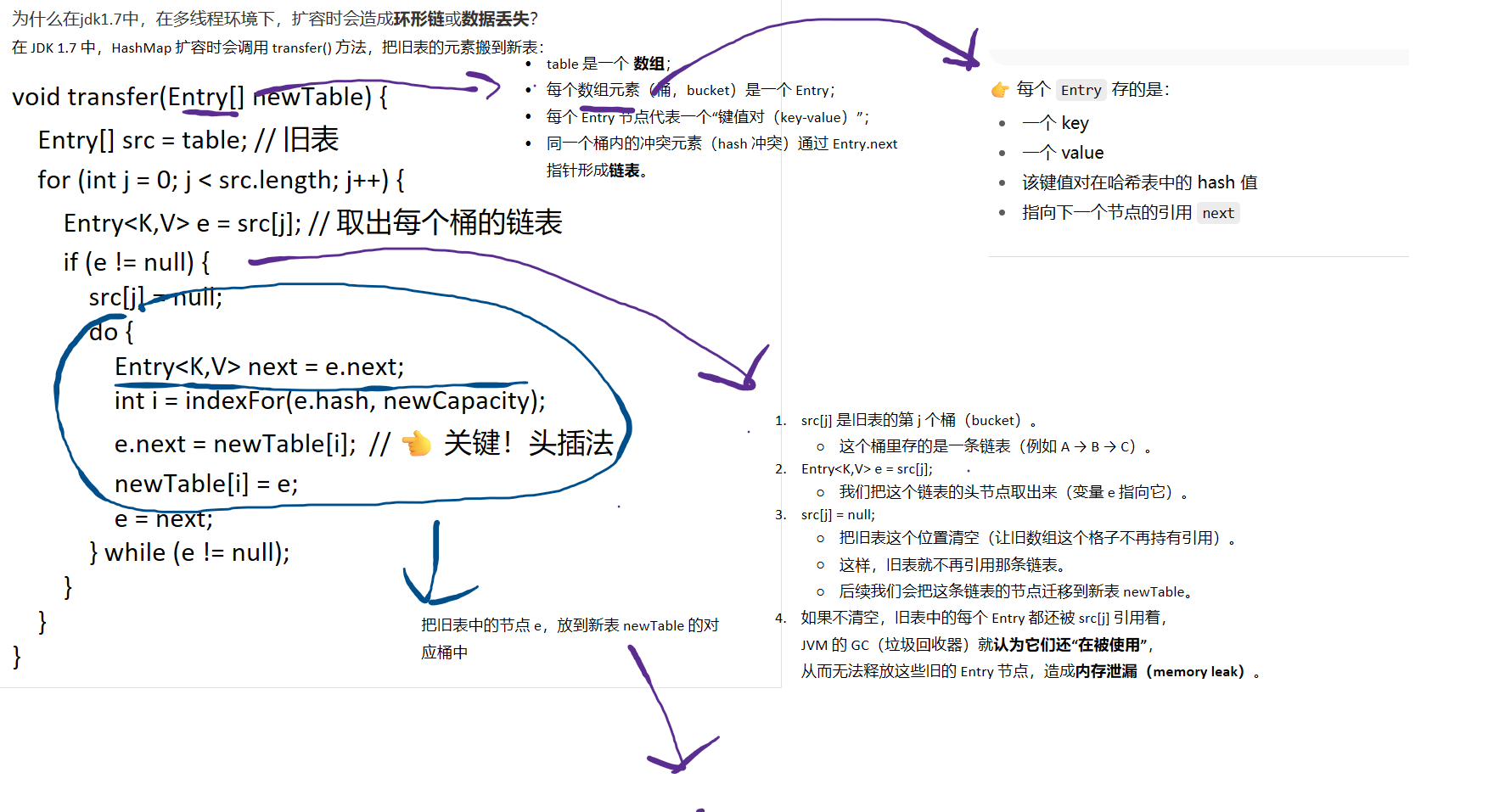
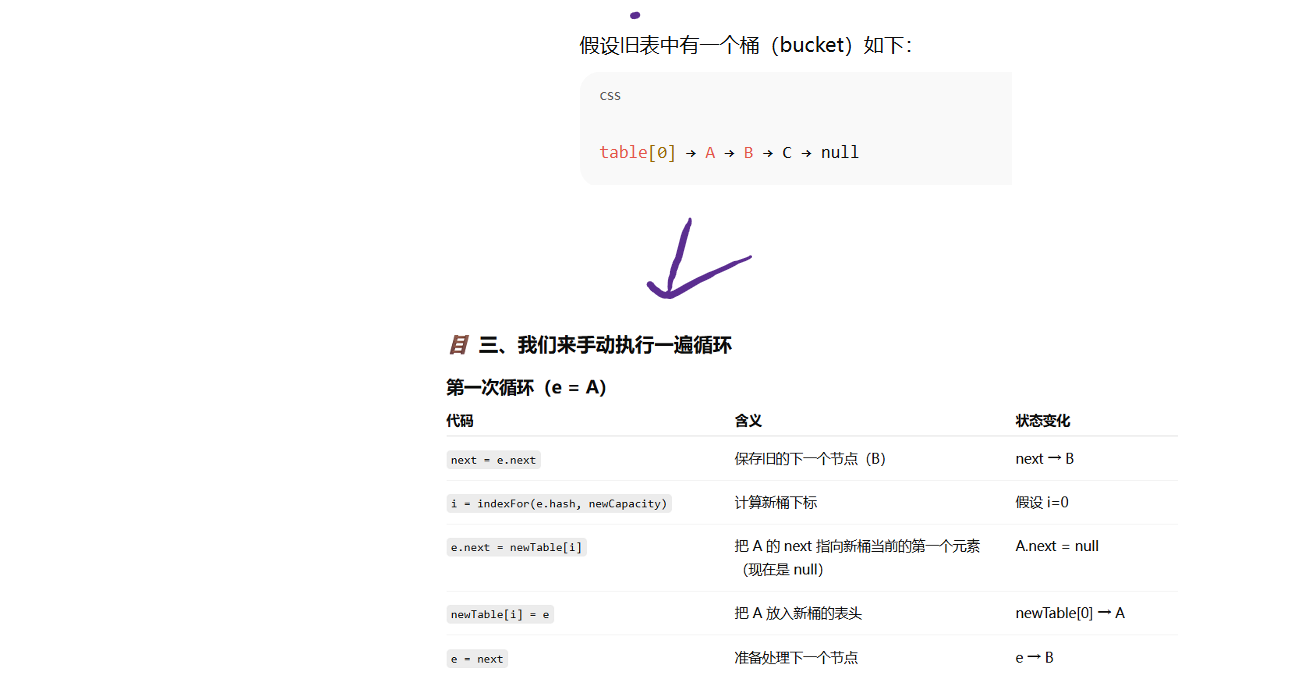

解释为什么在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失
造成环形链:
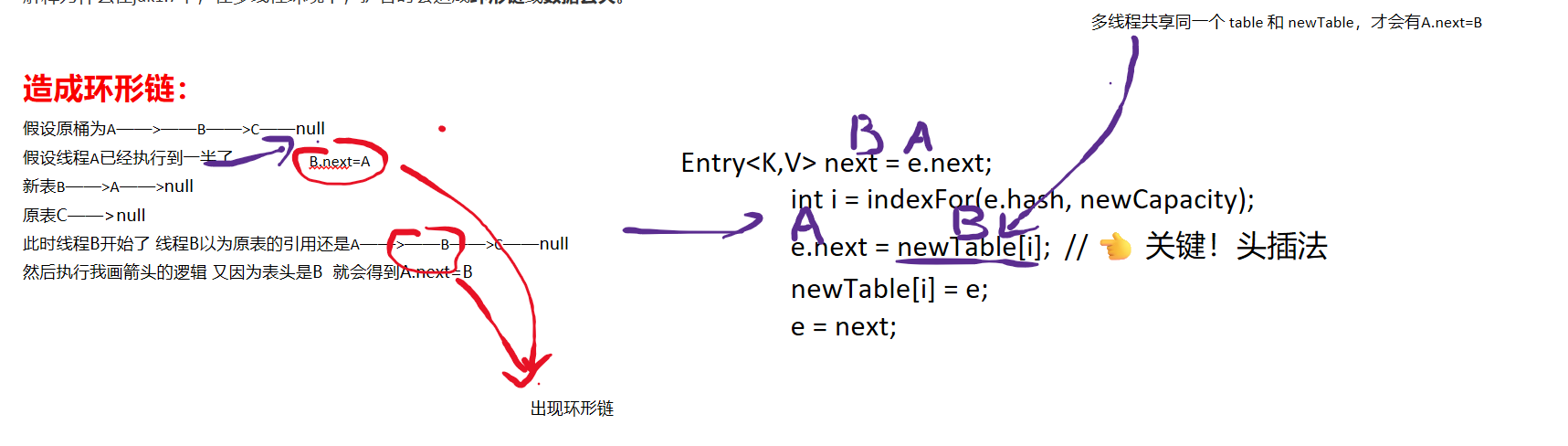
数据丢失

举例说明数据丢失
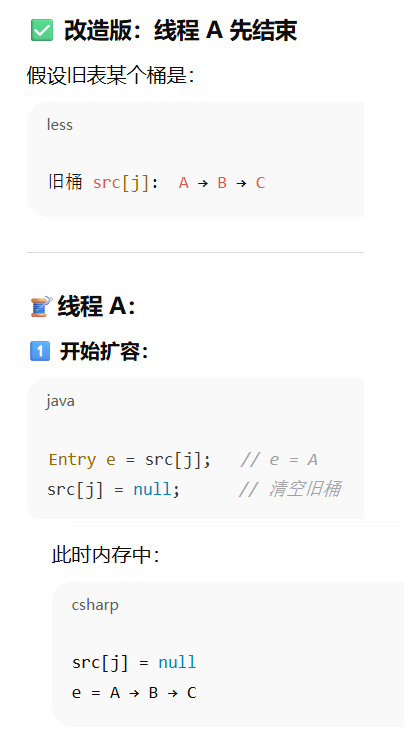
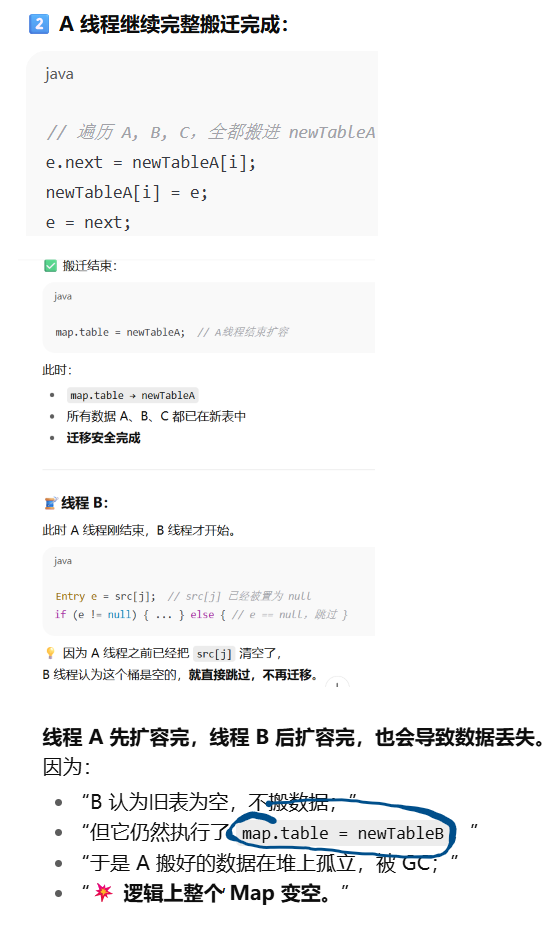
总结
总结:JDK1.7 HashMap 在多线程扩容时会出问题,是因为它用头插法无锁迁移旧桶,两个线程同时修改同一链表的 next 指针会导致链表成环;同时两个线程无序地写回 map.table 引用,导致后写的覆盖先写的,造成数据丢失。
为什么在jdk1.8中,在多线程环境下,插入元素到空桶会发生数据覆盖的情况?
- CAS 操作的竞争条件:
- 多个线程可能同时检测到桶为空并尝试插入元素。
- CAS 操作会确保只有一个线程能成功插入元素,其他线程会因为桶的值已被改变而失败并重试,但在某些情况下,重试可能导致数据覆盖。
- 扩容过程中的问题:
- 在哈希表扩容时,原有元素会被迁移到新桶。
- 如果一个线程在扩容过程中,另一个线程同时插入数据,可能导致数据丢失或覆盖。
- 缺乏同步机制的竞态条件:
- 即使使用了 CAS 操作,如果没有足够的同步控制,多个线程同时访问和修改同一个桶时可能会发生竞态条件,导致数据覆盖。
JDK 1.8 相比于 JDK 1.7 进行的优化
在 JDK 1.8 相比于 JDK 1.7 进行的优化,确实主要集中在 多线程环境下 对 哈希表扩容 和 元素插入 的处理方式上。以下分别讲解 HashMap 和 ConcurrentHashMap 在这些方面的优化:
1. HashMap 在 JDK 1.8 中的优化:
- 尾插法(Tail Insertion):
- JDK 1.7 中的 HashMap 插入元素时采用 头插法(即将新元素插入链表头部),这会增加多线程并发插入时的锁竞争,尤其是在链表长时。
- 在 JDK 1.8 中,HashMap 采用了 尾插法,即将新元素插入到链表的末尾。尾插法减少了多个线程同时操作链表头部的竞争,从而降低了插入时的锁竞争,提高了并发性能。
- 链表转红黑树(树化机制):
- JDK 1.7 中,如果某个桶的链表长度过长,查找效率会变差,因为每次查找都需要遍历整个链表,最坏情况的时间复杂度是 O(n)。
- JDK 1.8 引入了 树化机制:当链表长度超过一定阈值时(默认阈值为 8),链表会转化为 红黑树。红黑树的查找时间复杂度是 O(log n),有效提高了查找性能。
- 扩容时的优化:
- JDK 1.7 中的扩容操作涉及大量的哈希值重新计算和桶的重新分配,可能导致扩容时的数据丢失或覆盖。
- JDK 1.8 在扩容时,采用了更精细的机制,并且改进了扩容过程中链表和树的管理,避免了并发修改时的错误链表拼接或数据丢失问题。
2. ConcurrentHashMap 在 JDK 1.8 中的优化:
- 尾插法(Tail Insertion):
- 在 JDK 1.8 中,ConcurrentHashMap 采用了尾插法来插入新元素。尾插法确保每个新插入的元素都添加到链表的末尾,避免了多个线程同时竞争链表头部的情况,从而减少了锁竞争,提升了并发性能。
- 扩容机制的改进:
- 在 JDK 1.7 中,ConcurrentHashMap 使用了 分段锁,这使得扩容时仍然可能出现某些问题(如扩容期间多个线程操作同一个桶,导致数据丢失)。
- 在 JDK 1.8 中,ConcurrentHashMap 改用了 细粒度的锁机制(例如使用 CAS 操作),允许在扩容时多个线程并发地进行操作,减少了扩容过程中数据丢失或覆盖的可能性。
- 树化机制:
- 类似于 HashMap,JDK 1.8 中的 ConcurrentHashMap 在桶中的元素过多时,会将链表转化为 红黑树,这减少了长链表的遍历开销,提升了查询性能。
- 细粒度锁和 CAS 操作:
- JDK 1.8 对 ConcurrentHashMap 进行了显著优化,采用了更细粒度的锁控制,使得多个线程可以同时操作不同的桶,避免了锁的竞争。
- CAS 操作(比较并交换)被广泛应用于 ConcurrentHashMap 中,用来确保数据的一致性,避免并发插入时出现覆盖或丢失的问题。
总结:
- HashMap 在 JDK 1.8 中的优化:采用 尾插法 解决并发插入时的锁竞争问题,引入 树化机制 提升查找性能,改进了扩容时的数据处理方式,增强了对高并发情况下的性能支持。
- ConcurrentHashMap 在 JDK 1.8 中的优化:通过采用 尾插法、细粒度锁、CAS 操作 和 树化机制,极大地提升了并发性能,减少了扩容过程中数据丢失或覆盖的风险。

















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









