







目录
3.3 只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
3.4 只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)
问题
面试当中总会被问题这么一个问题:如何保证 Redis 缓存和数据库一致性?
但依旧有很多的疑问:
-
到底是更新缓存还是删除缓存?
-
到底选择先更新数据库,再删除缓存,还是先删除缓存,再更新数据库?
前言
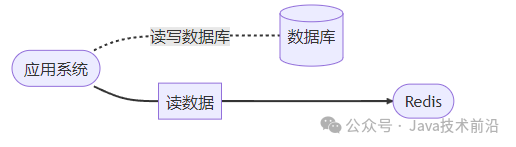
在项目业务的初期阶段,由于流量极其有限,无论是处理读取请求还是写入请求,直接对数据库进行操作是高效且直接的方式。此时的架构模型十分简洁,无需引入复杂的中间件或分布式系统,直接通过应用程序与数据库之间的交互来满足业务需求。此时架构模型是这样的

随着项目业务量的不断扩张,业务请求量急剧增加,若持续直接从数据库中读取数据,将面临显著的性能瓶颈。为了缓解这一问题,一个常见的做法是在架构中引入缓存机制,以提升读操作的性能。这样做能够有效减少数据库的压力,加快数据访问速度,此时的架构模型因而发生了变化,由单一依赖数据库转向了结合缓存与数据库的混合架构模式。
在实际软件开发实践中,缓存的采用极为普遍,它极大地提升了系统性能。然而,当同时使用缓存和数据库作为数据存储方案时,不可避免地会遇到一个挑战,即双写操作下的数据一致性问题。这指的是在更新数据时,如果缓存和数据库中的数据未能同步更新,就会导致Redis缓存中的数据与数据库中实际保存的数据出现不一致的情况,从而可能引发业务逻辑错误或数据混乱。
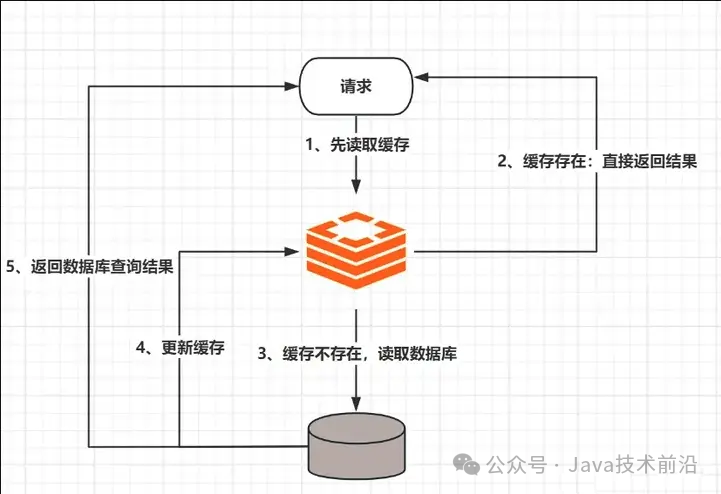
如上图所描绘的缓存应用场景,它确实能有效减轻数据库的处理负担,提升系统整体性能。然而,在涉及数据双写或更新操作时,确保缓存与数据库之间数据的一致性变得尤为复杂且挑战重重。无论是采取先删除缓存再写入数据库的策略,还是先写入数据库再删除缓存的顺序,都无法绝对避免数据一致性问题。
例如,若先尝试删除Redis缓存,但在缓存被清空至数据库更新完成之间的短暂时间窗口内,若有其他线程并发访问该数据,它们会发现缓存缺失而转向数据库查询旧数据,并将这些数据重新加载回缓存,从而导致缓存中存储了“脏数据”。
相反,若先写入数据库再尝试删除缓存,也可能遇到这样的情况:数据库更新成功,但在删除缓存前,由于某种原因(如系统崩溃、线程中断等),执行删除操作的线程未能完成其任务,从而使得旧缓存数据仍然保留,造成数据不一致。
鉴于读写操作在并发环境下的不确定性,确保缓存与数据库间数据完全一致变得极为困难。因此,我们需要探索和实施一系列策略来解决或缓解这一问题,包括但不限于使用事务、消息队列、延迟双删、分布式锁等机制,以确保数据的一致性和系统的健壮性。
一、说说一致性
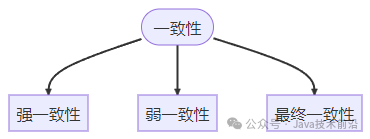
首先,我们先来看看有哪几种一致性的情况呢?
-
强一致性:要求写入即读取,符合用户直觉但影响性能。它需串行处理读写请求,排入内存队列,降低处理效率和吞吐量。若项目追求强一致性体验,缓存机制可能不适用,需权衡其对系统性能的潜在影响。在分布式系统中,强一致性实现复杂,通常需考虑其他一致性模型以平衡性能与一致性需求。
-
弱一致性:模型允许数据写入后,不保证即时可读取最新值,且不设定具体一致时间。它旨在一定时间内(如秒级),努力使数据趋于一致状态。这种模型牺牲即时性换取性能,适用于对实时性要求不高但追求系统效率的场景。它允许系统内部有一定的数据延迟,但确保最终数据的一致性。
-
最终一致性:是弱一致性的特殊形式,确保数据在不确定时间后终将达到一致。作为业界推崇的模型,它特别适用于大型分布式系统。此模型不追求即时一致,但保证数据最终一致,适合对实时性要求不高而重视高可用性的场景。在高可用设计中,通常保证最终一致性而非强一致性,以平衡系统性能与数据一致性的需求。
二、 应用场景分析
2.1 针对读操作的应用场景
当A请求查询数据时,若缓存中存在所需数据,则直接从缓存中获取并返回结果,提高响应速度。若缓存未命中而数据库中存在相应数据,系统将直接从数据库读取数据返回给请求者,并随后将数据更新至Redis缓存中,确保数据的最新状态被缓存。此流程设计确保了数据的一致性,避免了因缓存与数据库不同步而导致的数据不一致问题。

2.2 针对写操作的应用场景
若查询的数据在缓存中不存在,则直接修改数据库中的数据是可行的,因为此时不涉及缓存与数据库之间的同步问题,所以不会立即产生数据不一致的情况。
然而,当数据同时在缓存和数据库中存在时,更新操作就变得复杂且需要谨慎处理。如果更新操作仅针对数据库进行,并计划随后更新缓存,就需要确保这两个步骤的原子性。如果写数据库的值与预期更新到缓存的值一致,理论上可以立即更新缓存;但在高并发环境下,若写数据库与更新缓存的操作不是原子的,就可能因为操作顺序的错乱或失败(如缓存更新失败)而导致数据不一致。
以商品库存更新为例,若库存从100更新为99,理想的操作顺序是先更新数据库,再更新缓存。但如果在更新缓存时发生失败,就会导致数据库与缓存不一致(数据库为99,缓存为100)。
此外,在高并发场景下,还可能出现以下情况:若先删除了缓存再更新数据库,但数据库更新尚未完成时,其他请求可能因为缓存缺失而去数据库查询旧数据(如库存100),并重新将旧数据缓存,导致数据库更新完成后(库存为99),缓存中的数据仍然是旧的(库存100),从而产生数据不一致。
因此,处理这类问题时,需要设计合理的缓存更新策略,如使用事务、消息队列或延迟双删等机制,来尽量减少或避免缓存与数据库之间的数据不一致问题。
三、同步策略
想要保证缓存与数据库的双写一致,一共有4种方式,即4种同步策略:
缓存更新的设计方法大概有以下四种:
-
先删除缓存,再更新数据库(这种方法在并发下最容易出现长时间的脏数据,不可取)
-
先更新数据库,删除缓存(Cache Aside Pattern)
-
只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
-
只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)
接下来详细介绍一些这四种设计方法
3.1 先删除缓存,再更新数据库
这种方法在并发读写的情况下容易出现缓存不一致的问题
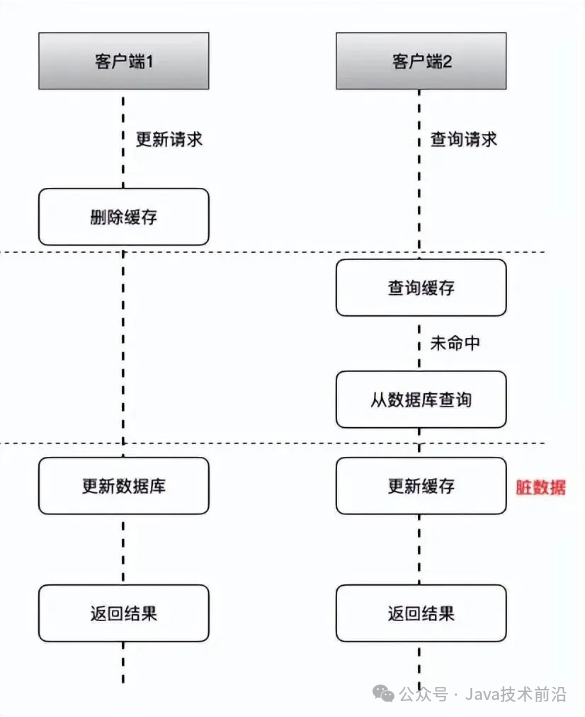
具体流程如下:
-
客户端1触发了更新数据A的逻辑。
-
紧接着,客户端2触发了查询数据A的逻辑。
-
客户端1首先更新缓存中的数据A,并立即返回操作结果给客户端1,提高了写操作的性能。
-
客户端2在缓存中查询数据A时,由于缓存已被客户端1更新,因此命中缓存并返回数据A,也提升了读操作的性能。
-
随后,缓存服务会异步地将更新后的数据A同步到数据库中。这个步骤是异步的,不会阻塞客户端的请求处理。
这种方式的优势在于显著提升了读写操作的性能,因为读写操作主要依赖于内存中的缓存,减少了对数据库的直接访问,从而降低了延迟并提高了吞吐量。然而,
其劣势在于无法保证强一致性,即存在数据丢失的风险。具体来说,如果缓存服务在异步更新数据到数据库的过程中发生故障或挂掉,那么那些尚未同步到数据库的数据就会丢失。这种情况下,如果系统依赖于数据库作为最终的数据源,那么丢失的数据将无法恢复,导致数据不一致。
因此,在采用这种异步更新策略时,需要仔细评估系统的数据一致性和可用性需求,并考虑实施额外的数据保护措施,如数据备份、故障恢复机制或更强的数据一致性模型,以确保数据的完整性和可靠性。
3.2 先更新数据库,再让缓存失效
这种方法在并发读写的情况下,也可能会出现短暂缓存不一致的问题
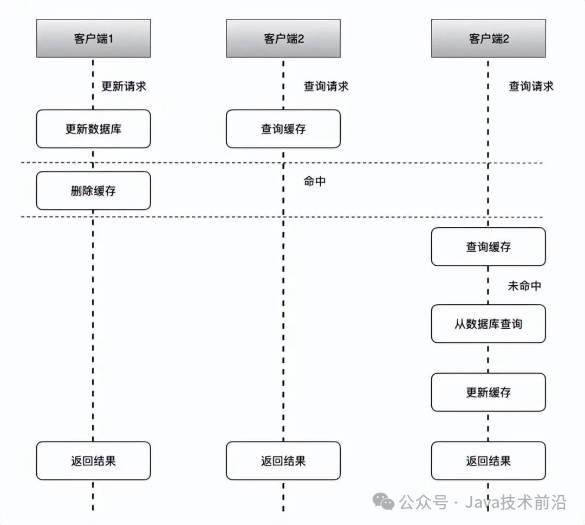
具体流程如下:
-
客户端1首先触发了更新数据A的逻辑。
-
几乎同时,客户端2和客户端3分别触发了查询数据A的逻辑。
-
客户端1执行更新操作,首先直接更新数据库中的数据A。
-
紧接着,客户端2查询缓存中的数据A,由于缓存尚未被更新或失效,因此命中了缓存并返回了旧的数据A。
-
随后,客户端1执行让缓存中数据A失效的操作,这通常是通过删除缓存中的对应项或设置过期时间来实现的。
-
当客户端3尝试查询缓存中的数据A时,由于缓存已被客户端1失效,因此查询未命中。
-
客户端3随后查询数据库中的数据A,获取到最新的数据,并将其更新到缓存中,从而确保了缓存与数据库之间的数据一致性。
虽然理论上存在一小段时间内数据不一致的情况(即客户端2查询到了旧数据,而客户端3最终查询到了新数据),但这种不一致的时间窗口通常很短,且发生的概率相对较低。对于大多数业务场景而言,这种短暂的数据不一致是可以接受的,因为最终缓存和数据库中的数据会保持一致。然而,在需要严格保证数据一致性的场景下,可能需要考虑采用其他的数据同步策略或一致性模型。
3.3 只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
这种方法相当于是业务只更新缓存,再由缓存去同步更新数据库。一个Write Through的 例子如下:
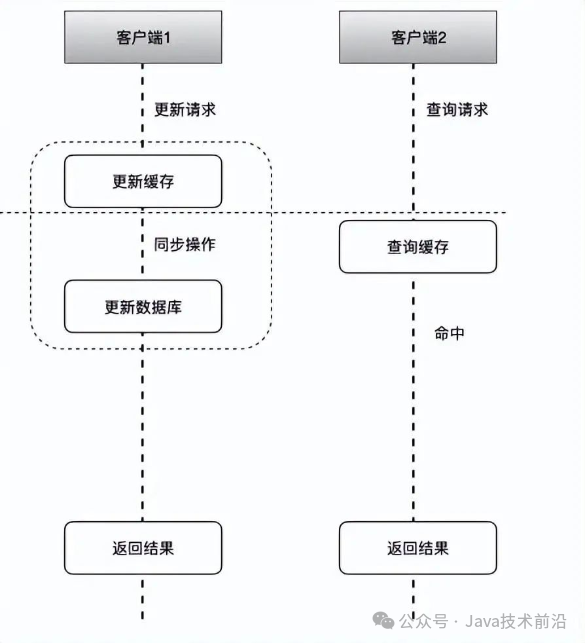
具体流程如下:
-
客户端1触发了更新数据A的逻辑。
-
在这一过程中,客户端1的更新操作不仅更新了缓存中的数据A,还通过缓存层的同步机制,将更新后的数据A同步更新到数据库中。这一步骤完成后,客户端1返回操作结果。
-
紧接着,客户端2触发了查询数据A的逻辑。
-
由于客户端1已经更新了缓存和数据库中的数据A,因此当客户端2查询缓存时,缓存中的数据A是最新的,查询命中并返回结果给客户端2。
这种方式虽然能够极大地降低缓存不一致的概率,但确实需要对缓存系统进行专门的改造,以支持缓存与数据库之间的同步机制以及缓存失效后的自动查询和更新功能。这样的改造虽然增加了系统的复杂性,但能够显著提升数据的一致性和系统的整体性能。
3.4 只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)
这种方式性详单于是业务只操作更新缓存,再由缓存异步去更新数据库,例如:

如图示流程所示,其执行顺序大致为:
-
客户端1触发了对数据A的更新逻辑。
-
几乎同时,客户端2触发了对数据A的查询逻辑。
-
客户端1首先更新缓存中的数据A,并立即返回操作成功的响应给客户端1,这一步骤显著提升了写操作的性能。
-
紧接着,客户端2查询缓存中的数据A,由于缓存已被客户端1更新,因此查询命中并返回了最新(对于缓存而言)的数据A给客户端2,这也提升了读操作的性能。
-
随后,缓存服务会异步地将更新后的数据A同步到数据库中。这个步骤是异步的,不会阻塞客户端的请求处理。
这种方式的优势在于它能够提供非常高效的读写性能,因为读写操作主要依赖于内存中的缓存,减少了对数据库的直接访问,从而降低了延迟并提高了吞吐量。
总结
上述所探讨的多种缓存更新设计策略,均源自业界的实践与智慧结晶,每种方式都有其独特的优势,但同时也伴随着相应的局限性和不完美之处。在设计系统时,应当认识到完美无缺的设计方案往往难以企及,因此重要的是在追求效率与一致性的平衡中做出明智的取舍。关键在于深入理解自身业务的具体需求与场景,从而选择一种最能契合这些需求、最大化系统效能的设计方案。这样,即使面对不完美的选择,也能确保系统在实际应用中发挥出最佳效能。
















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









