







 本文介绍了如何使用双指针法合并两个有序链表,以及利用哈希集合解决删除无序链表重复节点和查找相交链表的问题,还展示了递归方法在链表操作中的应用。
本文介绍了如何使用双指针法合并两个有序链表,以及利用哈希集合解决删除无序链表重复节点和查找相交链表的问题,还展示了递归方法在链表操作中的应用。
合并两个有序链表
双指针法
由于list1和list2都是递增的,可以想到用双指针法。假如当前list1这个指针指向的节点被收入完成,那就list1++;如果是list2被收入,那就list2++。
具体是list1和节点被收入还是list2的节点被收入?比较list1->val和list2->val的大小即可。
算法流程:
1. 创建dum节点(leetcode貌似都没有给虚假头节点的),作为新链表的虚假头节点。最后返回dum->next即可。
2. 写循环主体,注意循环终止的条件,list1或list2这两个指针有一个指向nullptr,说明有一个链表被选完了,那剩下另一个没被选完的直接往后插就行了。(为什么能这么干脆?因为list1和list2这两个链表本身就是有序的!)
3. 退出循环后,注意把还没选完的链表往新链表后面一插。
基于插入节点的算法设计,此处采用尾插法。
尾插法,需要用一个指针来记录尾节点。此处使用Cur
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
ListNode* dum = (ListNode*)malloc(sizeof(ListNode));
ListNode* cur = dum;
while(list1 != nullptr && list2 != nullptr) {
if(list1->val < list2->val) {
cur->next = list1;
list1 = list1->next;
}
else {
cur->next = list2;
list2 = list2->next;
}
cur = cur->next;
}
if(list1 == nullptr) cur->next = list2;
else cur->next = list1;
return dum->next;
}
};递归
这直接不用创建什么dum了。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {
if(list1 == nullptr) {
return list2;
}
if(list2 == nullptr) {
return list1;
}
if(list1->val <= list2->val) {
list1->next = mergeTwoLists(list1->next, list2);
return list1;
}
list2->next = mergeTwoLists(list1, list2->next);
return list2;
}
};
//这里不能再写第四个if,不然编译器觉得如果你四个条件都不满足的话,你return啥呢?woc太深奥了。
删除有序链表中的重复元素
双指针法
用pre和cur两个指针。pre指针作为最新确定的“标杆”,cur指针始终为pre-next(写cur是为了阅读和理解方便),是我们当前需要检验的节点。
循环退出的条件是,我们没有需要检验的节点了。也就是说,cur不存在了,即cur指向nullptr。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
//链表为空或链表只有一个节点时,直接return
//不过其实这里也可以只写链表为空的情况
if(head == nullptr || head->next == nullptr) {
return head;
}
ListNode* pre = head;
ListNode* cur = pre->next;
while(cur != nullptr) {
if(cur->val == pre->val) {
ListNode* r = cur->next;
delete cur;
pre->next = r;
cur = r;
}
else if(cur->val != pre->val) {
pre = cur;
cur = cur->next;
}
}
return head;
}
};这里为什么可以返回head?因为head绝对不会被删掉!
移除链表元素
单指针迭代
单指针即可,双指针完全没必要啊。这里必须要创建虚假头节点dum!因为head可能会被删掉。注意退出循环的条件,pre后面没有东西了。因为我们每次要检验的是pre-next,那你pre后面都没东西了我还检验啥呢?
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
//链表为空直接返回不用犹豫
if(head == nullptr) {
return head;
}
ListNode* dum = new ListNode(0);
dum->next = head;//dum的位置要记住,因为head可能被删掉!
ListNode* pre = dum;//用pre走,而不用dum走
while(pre->next != nullptr) {
if(pre->next->val == val) {
ListNode* r = pre->next->next;
delete pre->next;
pre->next = r;
}
else
pre = pre->next;
}
return dum->next;
}
};递归
“链表的定义具有递归的性质”?好好好。也就是说递归法是求解链表题的常用方法是吧。其实也很好理解。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeElements(ListNode* head, int val) {
//递归终止的条件为head为空
if(head == nullptr) {
return head;
}
//递归,就是只用关注每层的工作,以及每层传递给上层的东西
//本题,每层的工作就是把该节点之后的所有节点进行一次remove操作+对本层的头节点进行判断,以确定返回值是head还是head-next
//所以,每层肉眼可见做的事情,只有判断本层头节点
head->next = removeElements(head->next, val);
//最后判断头节点
if(head->val == val) {
return head->next;
}
return head;
}
};反转链表
迭代法
把后继节点记住,用r表示。pre、cur进行迭代。cur是我们要处理的节点。退出循环的条件是cur为空,就是没有需要处理的节点了。

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode *cur = head, *pre = nullptr;
while(cur != nullptr) {
ListNode *r = cur->next;
cur->next = pre;
pre = cur;
cur = r;
}
return pre;
}
};
最初的pre是nullptr,第一个需要处理的节点cur就是头节点。( pre最初设置成nullptr作为反转前链表头节点将要指向的东西,还挺重要的。我以前好像没意识到。)
整个while循环可以直接运转,无需特殊处理。最后返回pre。
递归
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
return cur(head, nullptr);
}
private:
ListNode* recur(ListNode* cur, ListNode* pre) {
if(cur == nullptr) return pre;
ListNode* res = recur(cur->next, cur);
cur->next = pre;
return res;
}
};
太抽象了nb。
回文链表
先反转链表
本来是想套用上题函数,但。。。这方法有大bug!
你反转完,原来的链表不就不在啦?!所以你要用这方法就必须再复制一个链表。
所以额外还要再写两个函数,一个reverseList一个copyList。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
//链表为空的特殊讨论
if(head == nullptr) {
return true;
}
ListNode* head1 = copyList(head);
ListNode* head2 = reverseList(head);
while(head1 != nullptr) {
if(head1->val != head2->val) {
return false;
}
head1 = head1->next;
head2 = head2->next;
}
return true;
}
ListNode* reverseList(ListNode* head) {
ListNode* cur = head, *pre = nullptr;
while(cur != nullptr) {
ListNode* r = cur->next;
cur->next = pre;
pre = cur;
cur = r;
}
return pre;
}
ListNode* copyList(ListNode* head) {
ListNode* newHead = new ListNode(head->val);
ListNode* r = newHead;
while(head->next != nullptr) {
ListNode* newNode = new ListNode(head->next->val);
r->next = newNode;
r = newNode;
head = head->next;
}
return newHead;
}
};把链表转换成数组
(我感觉可能是数据结构课上魔怔了,我的脑洞都打不开了!思维发散都不会了QAQ)
数组和链表,都是线性表的表现形式。数组是顺序表,链表是链式表。其实二者是可以相互转换的。至少在本题,回文数组可是很好求的!
我自己写的是纯数组。。因为他最多就100000个数,我开10005大小的数组。(刚开始脑抽,数组类型写成ListNode了/笑)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
int arr[100005] = {};
int i = 0;
while(head != nullptr) {
arr[i++] = head->val;
head = head->next;
}
for(int j = 0, q = i-1; j < i/2; j++,q--) {
if(arr[j] != arr[q]) return false;
}
return true;
}
};优雅vector,这样空间复杂度小了。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
vector<int> vals;
while(head != nullptr) {
vals.emplace_back(head->val);
head = head->next;
}
for(int i = 0, j = (int)vals.size() - 1; i < j; ++i, --j) {
if(vals[i] != vals[j]) {
return false;
}
}
return true;
}
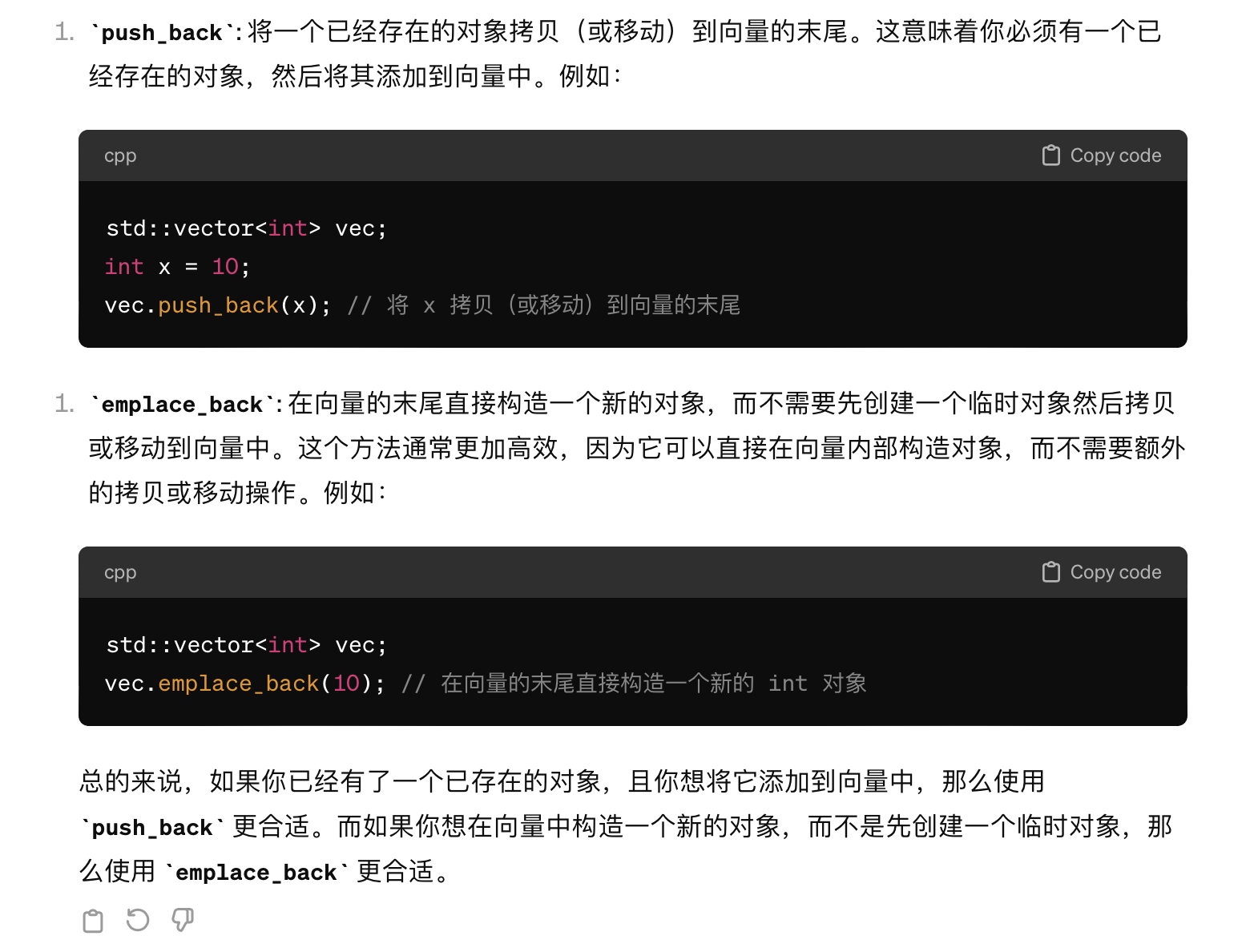
};插播一下std中的emplace_back函数:
相交链表
哈希集合
没想到这么做是因为对stl太不熟悉了,我最初只想到数组存储值,但后来一看,节点的值可以重复取,遂放弃。好伟大的哈希集合啊!
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
unordered_set<ListNode *> visited;
ListNode *temp = headA;
while(temp != nullptr) {
visited.insert(temp);
temp = temp->next;
}
temp = headB;
while(temp != nullptr) {
if(visited.count(temp)) {
return temp;
}
temp = temp->next;
}
return nullptr;
}
};时间复杂度:Om+n,m为链表A的长度,n为链表B的长度
空间复杂度:Om
双指针
这个太妙了只能说。思路就看看吧先。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode *pA = headA, *pB = headB;
if(pA == nullptr || pB == nullptr) {
return nullptr;
}
while(pA != pB) {
if(pA == nullptr) {
pA = headB;
}
else {
pA = pA->next;
}
if(pB == nullptr) {
pB = headA;
}
else {
pB = pB->next;
}
}
return pA;
}
};移除无序链表的重复节点
哈希集合
感觉哈希集合其实是很好用的。(上面那个删除有序链表中的节点,我感觉也可以用这个方法)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* removeDuplicateNodes(ListNode* head) {
if(head == nullptr) return nullptr;
unordered_set<int> visited;
//你要说删除节点,我可要创建dum了哦
//但其实这里不会删除头节点
ListNode* dum = new ListNode(0);
dum->next = head;
ListNode* temp = dum;
while(temp->next != nullptr) {
if(visited.count(temp->next->val)) {
temp->next = temp->next->next;
} else {
visited.insert(temp->next->val);
temp = temp->next;
}
}
return head;
}
};(不释放内存了我就展示算法)
时间复杂度:On,n为链表的节点个数
空间复杂度:On,哈希集合的长度(最坏情况n个节点的值都不同)















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









