







Applicaton如何向Master注册信息?
如何启动Master和Worker?
Driver与Executor资源如何分配?
在这里都能找到答案。
def rddBasics: Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("rdd basics implement")
val sparkContext: SparkContext = SparkContext.getOrCreate(sparkConf)
val rdd: RDD[Int] = sparkContext.parallelize(Array(1,2,3,4,5,6))
rdd.count()
}
程序一开始运行时会实例化SparkContext对象,所有不在方法里面的成员都会被实例化。一开始实例化的是createTaskScheduler,位于SparkContext的主构造器中,当SparkContext实例化时createTaskScheduler直接被调用,源码:
// 创建和启动调度器(scheduler)
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
//在DAGScheduler构造器中设置taskScheduler的引用后,启动TaskScheduler
_taskScheduler.start()
.........
创建和启动调度器后接下来是调用SparkContext的createTaskScheduler方法,此方法返回(SchedulerBackend,TaskScheduler),SparkContext的createTaskScheduler方法的源码:
// 创建和启动调度器(scheduler)
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
//在DAGScheduler构造器中设置taskScheduler的引用后,启动TaskScheduler
_taskScheduler.start()
.........
创建和启动调度器后接下来是调用SparkContext的createTaskScheduler方法,此方法返回(SchedulerBackend,TaskScheduler),SparkContext的createTaskScheduler方法的源码:
// 基于给定的URL创建任务调度器,返回一个(SchedulerBackend,TaskScheduler)二元组
private def createTaskScheduler(sc: SparkContext,
master: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._
// 当在本地运行时,不要试图在失败后重新执行新任务
val MAX_LOCAL_TASK_FAILURES = 1
master match {
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_REGEX(threads) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*]估计机器的核数,local[N]精确使用N个线程
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler)
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler)
case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
// requested <= memoryPerSlave则spark挂起
val memoryPerSlaveInt = memoryPerSlave.toInt
if (sc.executorMemory > memoryPerSlaveInt) {
throw new SparkException(
"Asked to launch cluster with %d MB RAM / worker but requested %d MB/worker".format(
memoryPerSlaveInt, sc.executorMemory))
}
......
在createTaskScheduler方法中实际调用了TaskSchedulerImpl中的initialize方法进行task的初始化,initialize方法的入参是特质SchedulerBackend,创建一个调度器线程池来定义资源分配模式schedulerMode,资源分配模式有FIFO和FAIR两种,源码:
def initialize(backend: SchedulerBackend) {
this.backend = backend
// 临时设置rootPool名字为空
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
createTaskScheduler方法执行完毕后,调用了TaskScheduler的start方法(在SparkContext的createTaskScheduler构造器中,见以上部分),虽然调用了特质TaskScheduler的start方法,但实际上是调用了TaskSchedulerImpl的start方法,因为TaskSchedulerImpl是特质TaskScheduler的子类,TaskSchedulerImpl的start方法的源码:
override def start() {
backend.start() //调用CoarseGrainedSchedulerBackend的start方法
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
speculationScheduler.scheduleAtFixedRate(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}
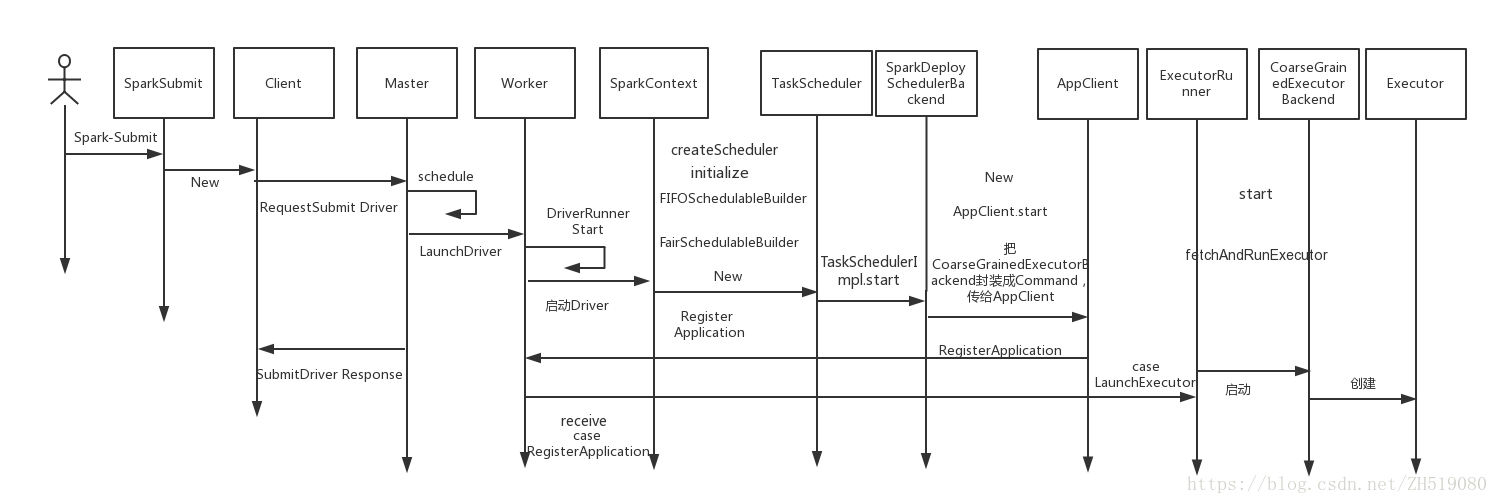
TaskSchedulerImp的start方法是通过backend.start方法启动了SparkDeploySchedulerBackend的start方法(spark1.6版本的standalone模式下,在spark2.0后SparkDeploySchedulerBackend更改名称为StandaloneSchedulerBackend)。SparkDeploySchedulerBackend的start方法中将command封装注册给Master,Master转过来要Worker启动具体的Executor,command已经封装好指令,Executor具体要启动进程入口类CoarseGrainedExecutorBackend,然后调用new()函数创建一个AppClient,通过Appcient.start启动client。Executor通过线程池并发执行Task,然后在调动它的run方法。
SparkDeploySchedulerBackend的start方法的源码:
override def start() {
super.start()
launcherBackend.connect()
// 获取executor的endpoint
val driverUrl = rpcEnv.uriOf(SparkEnv.driverActorSystemName,
RpcAddress(sc.conf.get("spark.driver.host"), sc.conf.get("spark.driver.port").toInt),
CoarseGrainedSchedulerBackend.ENDPOINT_NAME)
val args = Seq("--driver-url", driverUrl, "--executor-id", "{{EXECUTOR_ID}}", "--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}","--app-id", "{{APP_ID}}","--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil) ......
// Start executors with a few necessary configs for registering with the scheduler,通过scheduler的注册信息启动executor
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
//将command封装给Master,Master转过来要Worker启动具体的Ececutor,CoarseGrainedExecutorBackend是其进程
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory,
command, appUIAddress, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor)
client = new AppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start() //通过启动AppClient.start来启动client
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
AppClient(spark2.0后更名为StandaloneAppClient)的start方法中调用new()函数创建了ClientEndpoint对象,AppClient的start方法的源码:
def start() {
// Just launch an rpcEndpoint; it will call back into the listener.
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}又由于AppClient继承与trait ThreadSafeRpcEndpoint,实现了ThreadSafeRpcEndpoint的onStart方法,该方法是调用registerWithMaster方法向Master注册程序。
private class ClientEndpoint(override val rpcEnv: RpcEnv) extends ThreadSafeRpcEndpointwith Logging { ......
override def onStart(): Unit = {
try {
registerWithMaster(1)
} catch {
......}在AppClient的registerWithMaster方法中主要是实现了registerMasterFuturs.set(tryRegisterAllMasters())的tryRegisterAllMasters()方法,tryRegisterAllMasters中ClientEndpoint向Master发送RegisterApplication消息进行应用程序的注册。AppClient的tryRegisterAllMasters方法的源码:
private def tryRegisterAllMasters(): Array[JFuture[_]] = {
for (masterAddress <- masterRpcAddresses) yield {
registerMasterThreadPool.submit(new Runnable {
override def run(): Unit = try {if (registered.get) {return}
val masterRef =rpcEnv.setupEndpointRef(Master.SYSTEM_NAME, masterAddress, Master.ENDPOINT_NAME)
masterRef.send(RegisterApplication(appDescription, self))
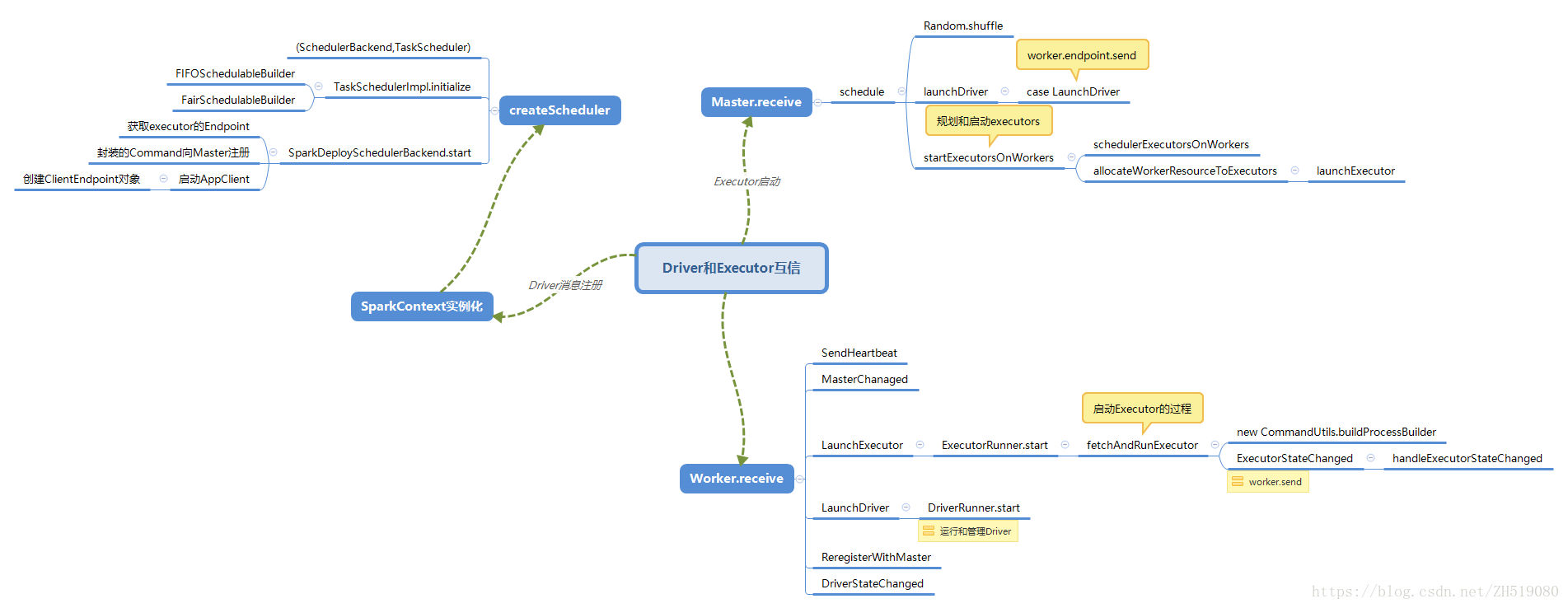
} catch {......}程序注册以后,Master通过schedule()分配资源,通知Worker启动Executor,Executor启动的进程是CoarseGrainedExecutorBackend,Executor启动以后又转过来向Driver注册,Driver其实是SparkDeploySchedulerBackend的父类CoarseGrainedSchedulerBackend的一个消息循环体DriverEndpoint。
Master-Driver-Executor资源分配和启动
ClientEndpoint向Master运行程序注册完成后,需要Master接收注册的消息,Master接收调用的是Master的receive方法,Master的receive方法的源码:
override def receive: PartialFunction[Any, Unit] = { ......
case RegisterApplication(description, driver) => {......
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()
}
case ExecutorStateChanged(appId, execId, state, message, exitStatus) => {......
val normalExit = exitStatus == Some(0)
if (!normalExit) {
if (appInfo.incrementRetryCount() < ApplicationState.MAX_NUM_RETRY) {
schedule()} else {
......Master匹配到RegisterApplication请求,先判断Master的状态是否为STANDBY(备用)状态,若不是说明Master为ALIVE状态,在此状态下调用createApplication(description,sender)方法创建ApplicationInfo,完成后调用persistenceEngine.addApplication(app)方法,将新创建的ApplicationInfo持久化,以便错误恢复。完成这两步操作后,通过send(RegisteredApplication(app.id,masterUrl))向AppClient返回注册成功后ApplicationInfo的Id和master的url地址。
Master的schdule方法是在Workers上启动Executor,实现了使正在等待运行的程序调用当前可用的资源,由Master的receive方法可知,每次一个新的应用程序连接或资源发生可用性变化时,则调用该方法:
private def schedule(): Unit = {
// 随机加载起到平衡的作用,从此看出,Driver在集群中随机的Worker上启动的
val shuffledWorkers = Random.shuffle(workers) // Randomization helps balance drivers
for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) { //遍历状态为ALIVE的Worker
//从waitingDrivers中提取Driver进行匹配
for (driver <- waitingDrivers) {
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver) //在该Worker上启动加载Driver
waitingDrivers -= driver //加载Driver后,从waitingDrvers中移除该Driver}}}
startExecutorsOnWorkers()}
Master类的schedule方法有两种作用:一是完成Driver的调度,将waitingDrivers数组中的Driver发送到满足运行条件的Worker上运行;二是在满足条件上的Worker节点上为Application启动Executor,其实调用的是startExecutorsOnWorkers方法。
Master在schedule方法中调用了launchDriver方法,launchDriver方法给Worker发送LaunchDriver消息,LaunchDriver本身是一个case class 包括driver.id、driver.desc信息:
private def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
worker.addDriver(driver)
driver.worker = Some(worker)
worker.endpoint.send(LaunchDriver(driver.id, driver.desc))
driver.state = DriverState.RUNNING}Master的schedule方法中启动了Executor的部分,在schdule方法中以RPC通信方式调用了startExecutorsOnWorkers方法,通过此startExecutorsOnWorkers方法在workers上进行shedule and launch executors,其Master的startExecutorsOnWorkers的源码
/** Schedule and launch executors on workers*/
private def startExecutorsOnWorkers(): Unit = {
for (app <- waitingApps if app.coresLeft > 0) {
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB &&
worker.coresFree >= coresPerExecutor.getOrElse(1))
.sortBy(_.coresFree).reverse
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps) //分配资源
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors( //启动Executors
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))}}在Master的startExecutorsOnWorkers方法中调用schdulerExecutors方法是把资源分配到Executor,调用allocateWorkerResourceToExecutors方法是为了启动Executor,在allocateWorkerResourceToExecutors方法中调用launchExecutor方法启动Eexecutor,源码:
private def launchExecutor(worker: WorkerInfo, exec: ExecutorDesc): Unit = {
worker.addExecutor(exec)
worker.endpoint.send(LaunchExecutor(masterUrl,
exec.application.id, exec.id, exec.application.desc, exec.cores, exec.memory))
exec.application.driver.send(
ExecutorAdded(exec.id, worker.id, worker.hostPort, exec.cores, exec.memory))}在Master类中通过launchDriver方法启动了Driver,调用launchExecutor方法启动了Executor。
Worker-Driver-Executor互信和管理
Master与Worker部署在不同的机器上,当Master把case class LaunchDriver、case class LaunchExecutor通过RPC的方式把消息发送给Worker时,Worker通过receive方法收到Master的LaunchDriver和LaunchExecutor消息,Worker的receive的源码:
override def receive: PartialFunction[Any, Unit] = synchronized {
case SendHeartbeat =>if (connected) { sendToMaster(Heartbeat(workerId, self)) } ......
case MasterChanged(masterRef, masterWebUiUrl) => changeMaster(masterRef, masterWebUiUrl) ......
case ReconnectWorker(masterUrl) => registerWithMaster() ......
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) => ......
val manager = new ExecutorRunner(appId,execId,appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),cores_,memory_,self,workerId,host,webUi.boundPort,
publicAddress,sparkHome,executorDir,workerUri,conf,appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
manager.start()
coresUsed += cores_
memoryUsed += memory_
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {......}
case LaunchDriver(driverId, driverDesc) => {
val driver = new DriverRunner(conf,driverId,workDir,sparkHome, //创建DriverRunner对象,包括配置文件、driverId、工作目录(workDir)、driverDesc、workerUri、securityManager等内容
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),self,workerUri,securityMgr)
drivers(driverId) = driver
driver.start()
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
}
case driverStateChanged @ DriverStateChanged(driverId, state, exception) => {
handleDriverStateChanged(driverStateChanged)
case ReregisterWithMaster =>reregisterWithMaster()
}匹配LaunchDriver成功构建DriverRunner对象,调用DriverRunner的start方法,DriverRunner的start方法源码如下:
/** Starts a thread to run and manage the driver. */
private[worker] def start() = {
new Thread("DriverRunner for " + driverId) {
override def run() {
try {val driverDir = createWorkingDirectory() //创建Driver的工作目录,除非磁盘满一般不会失败
val localJarFilename = downloadUserJar(driverDir) //把自己写的程序jar包下载到本地
def substituteVariables(argument: String): String = argument match {
case "{{WORKER_URL}}" => workerUrl
case "{{USER_JAR}}" => localJarFilename}
val builder = CommandUtils.buildProcessBuilder(driverDesc.command, securityManager,
driverDesc.mem, sparkHome.getAbsolutePath, substituteVariables)
launchDriver(builder, driverDir, driverDesc.supervise)
}catch { ......
worker.send(DriverStateChanged(driverId, state, finalException))}
}.start()
}重新回到Worker类的receive方法中,若Driver运行时KILLED/FAILED,通过worker.send发给自己一个消息,通知DriverStateChanged状态改变,Worker.receive中的driverStateChanaged实际调用的handleDriverStateChanged方法,此方法是针对不同的state情况,打印相关日志。
case driverStateChanged @ DriverStateChanged(driverId, state, exception) => {
handleDriverStateChanged(driverStateChanged)
}匹配LaunchExecutor成功构建ExecutorRunner对象,调用ExecutorRunner的start方法,在start方法中创建一个线程Thread调用的fetchAndRunExecutor方法,fetchAndRunExecutor方法源码如下:
private def fetchAndRunExecutor() {
try {
val builder = CommandUtils.buildProcessBuilder(appDesc.command, new SecurityManager(conf),
memory, sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command()
val formattedCommand = command.asScala.mkString("\"", "\" \"", "\"")
builder.directory(executorDir)
builder.environment.put("SPARK_EXECUTOR_DIRS", appLocalDirs.mkString(File.pathSeparator))
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
val baseUrl =
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
process = builder.start()
val header = "Spark Executor Command: %s\n%s\n\n".format(
formattedCommand, "=" * 40)
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
val exitCode = process.waitFor()
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
worker.send(ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode)))
} catch {
......}
fetchAndRunExecutor类似于启动Executor的过程,在启动Executor时首先构建CommandUtils.buildProcessBuilder,然后是builer.start(),退出时发送ExecutorStateChanaged消息给Worker,在ExecutorStateChanaged中其实是调用的handleExecutorStateChanaged,sendToMaster(executorStateChanaged)法executorStateChanaged消息给Master,Worker类的handleExecutorStateChanaged的源码:
private[worker] def handleExecutorStateChanged(executorStateChanged: ExecutorStateChanged):Unit = {
sendToMaster(executorStateChanged)
val state = executorStateChanged.state
if (ExecutorState.isFinished(state)) {
val appId = executorStateChanged.appId
val fullId = appId + "/" + executorStateChanged.execId
val message = executorStateChanged.message
val exitStatus = executorStateChanged.exitStatus
executors.get(fullId) match {
case Some(executor) =>
executors -= fullId
finishedExecutors(fullId) = executor
trimFinishedExecutorsIfNecessary()
coresUsed -= executor.cores
memoryUsed -= executor.memory
case None => ......
}
maybeCleanupApplication(appId)
}
}














 1348
1348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









